
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1.HashMap
1.1.HashMap遍历方法
public class CircleMap {
public static void main(String[] args) {
//创建HashMap对象
HashMap<String, Integer> tempMap = new HashMap<String, Integer>();
//以<key,value>的形式向HashMap对象中添加数据。
//数据的存储数据与添加的顺序无关,与key值对应的hash值有关
tempMap.put(“a”, 1);
tempMap.put(“b”, 2);
tempMap.put(“c”, 3);
// 遍历方法一 hashmap entrySet() 遍历
System.out.println(“方法一“);
Iterator it = tempMap.entrySet().iterator();
while (it.hasNext()) {
//HashMap里面静态内部类Entry对象
Map.Entry entry = (Map.Entry) it.next();
Object key = entry.getKey(); //取得key值
Object value = entry.getValue(); //取得value值
System.out.println(“key=” + key + ” value=” + value);
}
// JDK1.5中,应用新特性For-Each循环
// 遍历方法二
System.out.println(“方法二“);
//for each方法遍历
for (Map.Entry<String, Integer> entry : tempMap.entrySet()) {
String key = entry.getKey().toString();
String value = entry.getValue().toString();
System.out.println(“key=” + key + ” value=” + value);
}
// 遍历方法三 hashmap keySet() 遍历
//map.keySet():表示包含HashMap中所有key的Collection对象
System.out.println(“方法三“);
for (Iterator i = tempMap.keySet().iterator(); i.hasNext();) {
Object obj = i.next(); //获取下一个key值
System.out.println(obj);// 循环输出key
System.out.println(“key=” + obj + ” value=” + tempMap.get(obj));
}
//map.values():表示包含HashMap中所有value的Collection对象
for (Iterator i = tempMap.values().iterator(); i.hasNext();) {
Object obj = i.next(); //获取下一个value值
System.out.println(obj);// 循环输出value
}
// 遍历方法四 treemap keySet()遍历
System.out.println(“方法四“);
//for each方法遍历
for (Object o : tempMap.keySet()) {
//o对象的值属于key值。
//map.get(key)方法:通过key值获取value值
System.out.println(“key=” + o + ” value=” + tempMap.get(o));
}
// java如何遍历HashMap <String, ArrayList> map = new HashMap <String,
// ArrayList>();
System.out
.println(“java 遍历Map <String, ArrayList> map = new HashMap <String, ArrayList>();”);
HashMap<String, ArrayList> map = new HashMap<String, ArrayList>();
Set<String> keys = map.keySet(); //创建包含 所有key值得集合
Iterator<String> iterator = keys.iterator(); //创建遍历所有key值得对象
while (iterator.hasNext()) {
String key = iterator.next();
//将通过key参数获得对应的value值保存在ArrayList集合中
ArrayList arrayList = map.get(key);
for (Object o : arrayList) { //使用for each方法遍历ArrayList集合
System.out.print(o + ” “);
}
//使用List集合遍历HashMap
HashMap<String, List> mapList = new HashMap<String, List>();
for (Map.Entry entry : mapList.entrySet()) {
String key = entry.getKey().toString();
List<String> values = (List) entry.getValue();
for (String value : values) {
System.out.println(key + ” –> ” + value);
}
}
}
1.2.HashMap(哈希表)实现原理分析
哈希表的实现有几种方法:
1.2.1。HashMap的数据结构

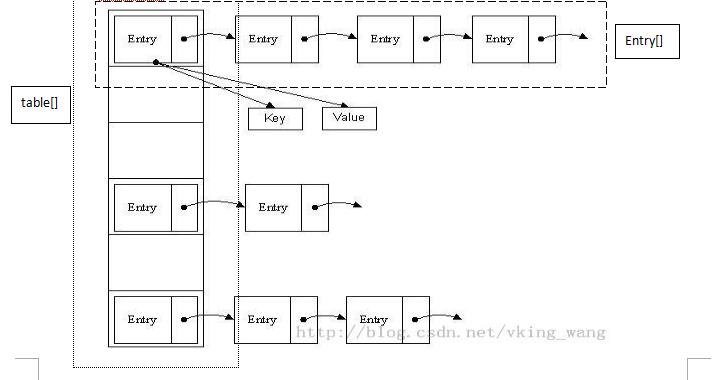
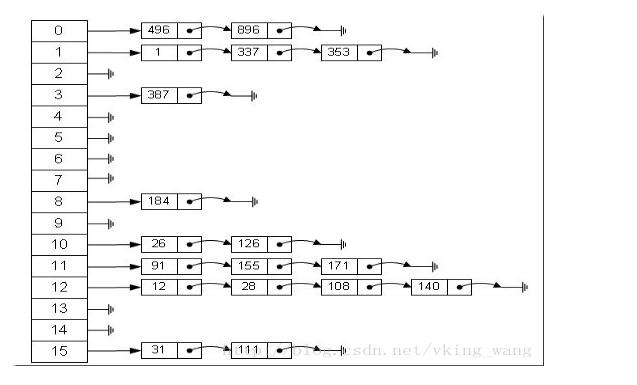
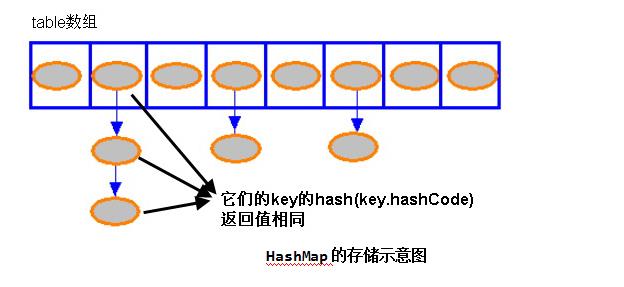
HashMap是以键值对<key,value>的形式存储数据的。
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap怎么实现按键值对来存取数据呢?这里HashMap有做一些处理:
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
1.2.2.HashMap的存取实现
// 存储时:
// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int hash = key.hashCode();
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
1)put:map.put(key,value)
疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。例如,第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。也就是说数组中存储的是最后插入的元素。
HashMap<String , Double> map = new HashMap<String , Double>();
map.put("语文" , 80.0);
map.put("数学" , 89.0);
map.put("英语" , 78.2); put(K key, V value)源代码:
Entry[] table;
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
// 根据 key 的 keyCode 计算 Hash 值
int hash = hash(key.hashCode());
// 搜索指定 hash 值在对应 table 中的索引
int i = indexFor(hash, table.length);
// 遍历链表:如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
//<key,value>是一一映射的:相同的key对应相同的value值。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // 将 key、value 添加到 i 索引处
return null;
}
//该方法仅用于添加一个key-value队
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex];
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e, 是Entry.next
//如果size超过threshold,则扩充table大小为原来的2倍。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因子,随着map的size越来越大,Entry[]会以一定的规则加长长度。 根据上面 put 方法的源代码可以看出,当程序试图将一个 key-value 对放入 HashMap 中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但 key 不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部。当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。
2)get:value=map.get(key)
public V get(Object key) {
// 如果 key 是 null,调用 getForNullKey 取出对应的 value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
// 直接取出 table 数组中指定索引处的值
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
// 如果该 Entry 的 key 与被搜索 key 相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
3)null key的存取
null key总是存放在Entry[]数组的第一个元素。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
4)确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
//Returns index for hash code h.
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%。
这意味着数组下标相同,并不表示hashCode相同。
1.3. 解决hash冲突的办法
1. 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
2. 再哈希法
3. 链地址法
4. 建立一个公共溢出区
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/195491.html原文链接:https://javaforall.net

![ES6数组常用方法总结[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
