
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1. 函数简介
mysql 5.0开始支持函数,函数是存在数据库中的一段sql集合,调用函数可以减少很多工作量,
减少数据在数据库和应用服务器上的传输,对于提高数据处理的效率。参数类型为in类型,函数必须有返回值,
与oracle等其他库函数参数类型有区别,如果做数据迁移,或许需要将函数改变成存储过程,
因为mysql的存储过程参数包括in,out,inout三种模式。
创建函数语法:
CREATE FUNCTION fn_name(func_parameter[,...])
RETURNS type
[characteristic...]
routine_body参数代表含义:
func_parameter: param_name type
type: 任何mysql支持的类型
characteristic:
LANGUAGE SQL | [NOT]DETERMINISTIC
| {CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA}
| SQL SECURITY {DEFINER | INVOKER}
| COMMENT ‘String’
routine_body: 函数体
更改函数语法:
ALTER FUNCTION fn_name [characteristic...]characteristic:
{CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA}
| SQL SECURITY {DEFINER | INVOKER}
| COMMENT ‘String’
2. 实例分析准备条件
创建表:
CREATE TABLE `t_user_main` (
`f_userId` int(10) NOT NULL AUTO_INCREMENT COMMENT '用户id,作为主键',
`f_userName` varchar(5) DEFAULT NULL COMMENT '用户名',
`f_age` int(3) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`f_userId`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;插入数据:
INSERT INTO t_user_main (f_userName, f_age)
VALUES('one',24),('two',25),('three',26),('four',27),('five',28),('six',29);3. 实例分析函数
eg:
#创建一个函数
DELIMITER $$ -- 定界符
-- 开始创建函数
CREATE FUNCTION user_main_fn(v_id INT)
RETURNS VARCHAR(50)
BEGIN
-- 定义变量
DECLARE v_userName VARCHAR(50);
-- 给定义的变量赋值
SELECT f_userName INTO v_userName FROM t_user_main
WHERE f_userId = v_id;
-- 返回函数处理结果
RETURN v_userName;
END $$ -- 函数创建定界符
DELIMITER; sql中使用函数:
SELECT user_main_fn(1) FROM DUAL;mysql中函数创建特别注意的两点:
(1) 需要定义定界符,否则是创建不了函数的,因为mysql见到’分号’就认为执行结束了,只有开始
创建时定义分界符,结束时在配对一个分界符,mysql认为这个时候才结束,使得函数能够完整编译创建。
(2)mysql创建函数是没有or replace 这个概念的,这个地方与创建视图不同。
在函数中,运行包含DDL语句,允许提交或回滚,函数中可以调用其他函数或存储过程。
#创建第二个函数,使用第一个函数
DELIMITER $$
CREATE FUNCTION user_main_fn2(v_id INT)
RETURNS VARCHAR(100)
BEGIN
#定义变量
DECLARE v_userName VARCHAR(50);
DECLARE v_userNameNew VARCHAR(50);
#通过into赋值
SELECT f_userName INTO v_userName FROM t_user_main WHERE f_userId = v_id;
#使用函数
SELECT user_main_fn(v_id) INTO v_userNameNew FROM DUAL;
#返回函数处理结果
RETURN CONCAT(v_userName,'***',v_userNameNew);
END $$
DELIMITER;查询新建函数:
SELECT user_main_fn2(1);查询结果:

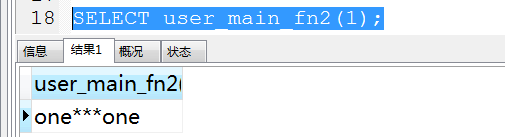
4. 函数中变量的使用
MySql中变量从5.1后不区分大小写。
变量的定义:
通过DECLARE可以定义一个局部变量,变量的作用范围BEGIN…END块中;
变量语句必须卸载复合语句开头,并且在其他语句的前面;
一次性可以声明多个变量;
变量定义语法:
DECLARE var_name[,...] type [DEFAULT value]在函数中定义变量的用法:
DELIMITER $$
CREATE FUNCTION user_main_fn2(v_id INT)
RETURNS VARCHAR(100)
BEGIN
#定义变量
DECLARE v_userName VARCHAR(50);
DECLARE v_userNameNew VARCHAR(50);
#定义变量,可以一次性定义多个
#DECLARE v_userName,v_userNameNew VARCHAR(50);
DECLARE v_testSet VARCHAR(50);
SET v_testSet = 'testSet';
#通过into赋值
SELECT f_userName INTO v_userName FROM t_user_main WHERE f_userId = v_id;
#使用函数
SELECT user_main_fn(v_id) INTO v_userNameNew FROM DUAL;
#返回函数处理结果
RETURN CONCAT(v_userName,'***',v_userNameNew,v_testSet);
END $$
DELIMITER;我们通过DECLARE 定义一个v_userName变量,变量类型为varchar,长度为50;
对于变量定义,对于同类型的变量,可以分开声明,也可以一次声明;
变量赋值:变量可以通过直接赋值,也可以通过查询语句赋值。
直接赋值语法:SET var_name = expr[,var_name=expr]…
在上面函数中,定义一个v_testSet变量,通过set直接赋值,eg:
DECLARE v_testSet VARCHAR(50);
SET v_testSet = 'testSet';通过select…INTO…赋值,通过这种方式赋值,要求查询返回只有一行结果,
使用语法:
SELECT col_name[,...] INTO var_name[,...] table_expr;eg:
SELECT f_userName INTO v_userName FROM t_user_main WHERE f_userId = v_id;5. 查看函数状态或定义语句
查看函数状态语法:
SHOW FUNCTION STATUS [LIKE 'pattern']查看函数的定义语法:
SHOW CREATE FUNCTION fn_name;eg:
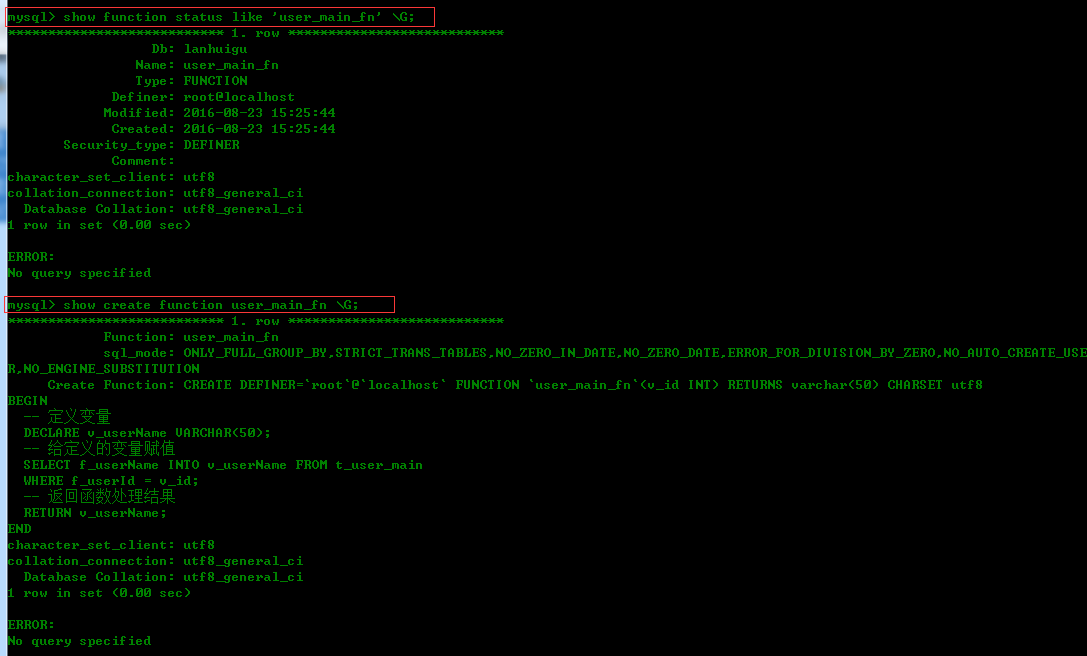
6. 函数删除
DROP FUNCTION [IF EXISTS] fn_name;
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/195985.html原文链接:https://javaforall.net

![PCI与PCIe学习一——硬件篇[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
