
文章目录
前言
一、指针式复用
1、指针
我们知道,内存可以通过地址(指针)来访问。但 SQL 没有用内存指针表示的数据对象,在返回结果集时,通常要把数据复制一份,形成一个新的数据表。这样不仅多消耗 CPU 时间(用于复制数据)而且还会占用更多昂贵的内存空间(用于存储复制的数据),降低内存使用率。
2、RDD
3、返回指针
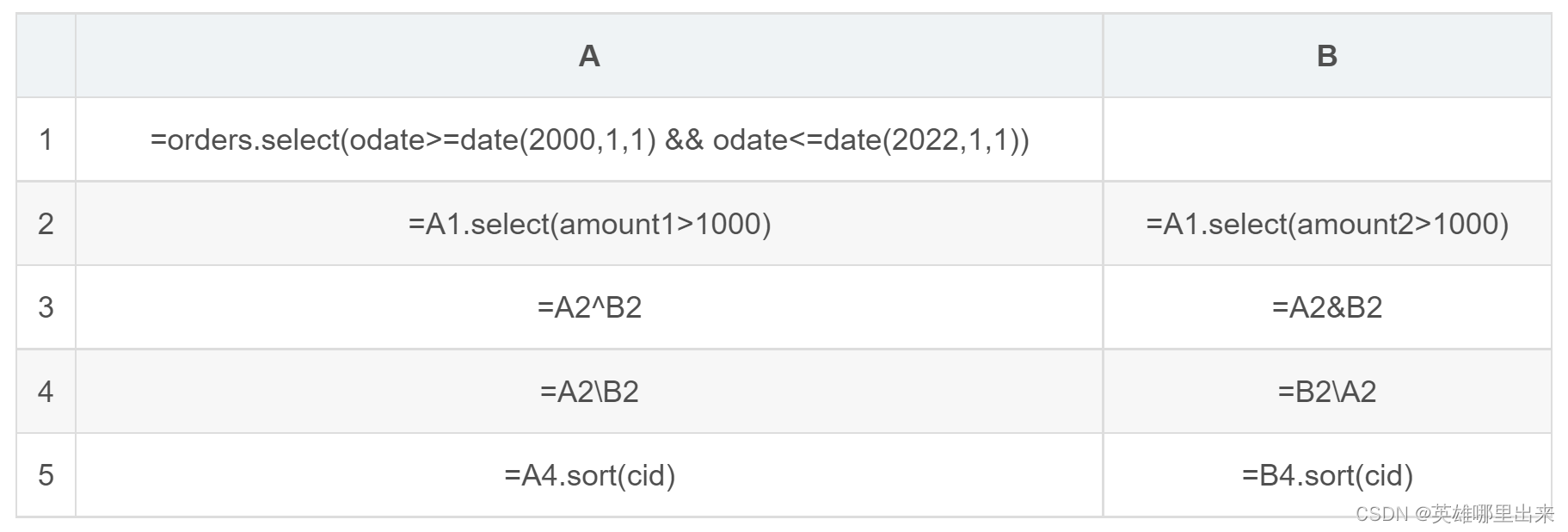

以上代码中有好几个步骤,有的中间结果也被用了多次,但由于使用的都是订单表记录的指针,所以内存占用增加的很少,也避免了记录复制的耗时。
二、外键预关联
1、外键关联
外键关联是指用一个表(事实表)的非主键字段,去关联另一个表(维表)的主键。比如订单表中的客户号和产品号分别关联客户表、产品表的主键。现实运算中这种关联可能多达七八个甚至十几个表,还可能出现多层的关联。SQL 数据库通常使用 HASH JOIN 算法来做内存连接,需要计算和比对 HASH 值,过程中还会占用内存来存储中间结果,关联表很多时计算性能就会急剧下降。
2、指针引用
其实,我们也可以利用内存指针引用机制事先做好关联。在系统初始化阶段,把事实表中的关联字段值转换为对应维表记录的指针。因为维表的关联字段是主键,所以关联记录唯一,将外键值转换成记录指针不会引起错误。在后续计算中,需要引用维表字段时,可以用指针直接引用,无需计算和比对 HASH 值,也不需要再存储中间结果,从而获得更优的性能。SQL 没有记录指针这种数据类型,也就无法实现预关联了。
3、预关联
SPL 则从原理上支持并实现了这种预关联机制。例如,完成订单表和客户表、产品表预关联的代码大致是这样:
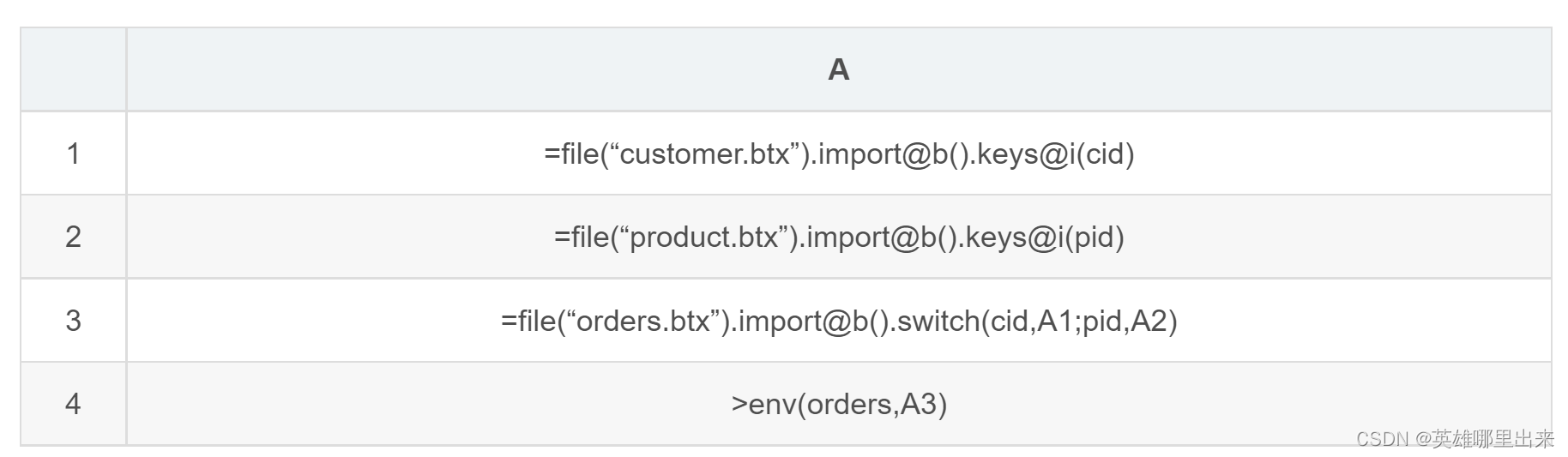
A1、A2 加载客户表和产品表。
A3:加载订单表,将其中的客户号 cid、产品号 pid 转换为对应维表记录的指针。
A4:将完成预关联的订单表存入全局变量,供后续计算使用。
系统运行时,按照产品供应商过滤订单,再按客户所在城市分组汇总的代码大致是下面这样:

订单表中的 pid 已经转换为产品表记录的指针,所以可以直接用“.”操作符引用产品表记录。 不仅书写更简单,而且运算性能也快得多。
只是两、三个表关联时,预关联和 HASH JOIN 的差别还不是非常明显。这是因为关联并不是最终目的,之后还会有其它很多运算,关联本身运算消耗时间的占比相对不大。但如果关联情况比较复杂,涉及的表很多,以及有多层的时候(比如订单关联产品,产品关联供应商,供应商关联城市,城市关联国家等等),预关联的性能优势会更明显。
三、序号定位
1、序号
与外存相比,内存的另一个重要特征是支持高速的随机访问,可以快速从内存表中按指定序号(也就是位置)取出数据。在做查找计算时,如果被查找的值正好是目标值在内存表中的序号,或者很容易通过被查找值计算出目标值的序号,我们就可以用序号直接取目标记录。这种方法不需要进行任何比对就能直接取出查找结果,性能不仅远远好于遍历查找,也好于使用索引的查找算法。
2、索引
但是,SQL 以无序集合为基础,不能按序号取成员,只能用序号去查找。如果没有索引就只能遍历查找,会非常慢。即使有索引也要计算 HASH 值或用二分法查找,速度也比不上直接定位。而且,建立索引也会占用昂贵的内存。如果数据表中没有序号还要先排序再硬造个序号时,性能就会更差。
3、序号定位
SPL 以有序集合为基础,提供序号定位功能。比如订单表中的订单号是从 1 开始的自然数。在查找订单号 i 时,直接取订单表中的第 i 条记录就行了。再比如数据表 T 从 2000 年到 2022 年每天存储一条数据,现在需要查询指定日期的记录。日期虽然不是目标值的序号,但是我们可以先算出指定日期距离起始日期的天数。这就是目标值的序号,然后再用序号取 T 表记录就可以了。对表 T 用序号定位查找 2022 年 4 月 20 日记录的代码,大致是下面这样:
| A | |
|---|---|
| 1 | =date(2022,12,31)-date(1999,12,31) |
| 2 | =T_orginal.align@b(to(A1),dt-date(1999,12,31)) |
| 3 | =env(T,A5) |
| 4 | =T(date(2021,4,20)-date(1999,12,31)) |
A1:计算出 2000 年到 2022 年总天数是 8401 天。
A2:用原始的 T 表记录计算出距离起始日期的天数,再和 to(A1)这个自然数集合 [1,2,3,…,8401] 对齐,空缺的日期会用 null 补齐。align 的 @b 选项表示对齐时将使用二分法来查找位置,这样完成对齐动作也会更快一点。
A3:计算好的结果,放到全局变量 T 中。
A4:要查找 2021 年 4 月 20 日记录,求出这个日期和起始日期距离 7781 天,直接取出 T 表中第 7781 条记录就可以了。
A1 到 A3 是对齐计算,用于处理空缺的日期,可以放在系统初始化阶段。在查找计算时,用 A4 中的序号定位代码就能得到查找结果,实际查找的日期可以作为参数传入。
四、集群维表
1、集群
当数据量太大,超出单机内存时,就要使用集群来加载这些数据。许多内存数据库也支持分布式计算,通常是将数据分成多段,分别加载到集群不同分机的内存中。
2、JOIN
JOIN 是分布式计算的一个麻烦任务,会涉及多个分机之间的数据传输。严重的时候,传输造成的延迟会抵消集群分摊计算量得到的好处,会出现集群变大反而性能并不能提升的现象。
3、分布式数据库
SQL 体系下的分布式数据库,通常是将单机 HASH JOIN 方法扩展到集群上。每个分机根据 HASH 值将本机数据分发到其他分机,确保相关联的数据在同一分机上。然后再在各个分机上做单机连接。但是,HASH 方法在运气不好的时候,可能会造成数据分配的严重不均衡,需要借助外存来缓存这些分发到的数据,否则可能因为内存溢出而导致系统崩溃。但是,内存数据库的主要特征就是将数据加载到内存中计算,出现外存缓存会严重拖慢计算性能。
4、外键关联
实际上,外键关联的事实表和维表有很大区别。事实表一般都比较大,要用各个分机内存分段加载才能装的下。正好事实表也比较适合分段,每个分段的数据都相互独立,分机之间不需要相互访问。而维表记录则会被随机访问,事实表的任何一个分段都可能关联全部维表记录。我们可以利用事实表和维表的区别,对集群的外键关联提速。
如果维表比较小,则将维表全量数据复制到所有分机内存中。这样,每个分机中的事实表分段和全量维表就可以继续完成预关联,完全避免了关联过程中的网络传输。
如果维表也很大,单机内存放不下,只能在各分机内存中分段加载。这时,没有一个分机上有全量的维表,外键关联计算就无法避免网络传输了。不过传输内容并不算很大,只涉及事实表的外键和维表关联记录的字段,事实表其它字段不需要传输,计算可以直接完成,过程中也不会产生缓存数据。
SPL 从原理上区分维表和事实表,针对维表较小和维表较大两种情况,分别提供了维表复制机制和分段维表机制,实现了上述算法,能显著提高集群情况下外键关联的计算性能。
五、回顾与总结
内存数据库的计算体系,必须充分利用内存的特征才能获得极致性能。从数据计算的角度来看,内存主要优点有:支持指针引用、支持高速随机访问、并发读取能力强。内存的缺点是:成本高昂、扩容有上限。
而 SQL 计算体系中缺乏一些必要的数据类型和运算,比如:缺少记录指针类型,不支持有序运算,JOIN 定义过于笼统,不区分 JOIN 类型等,从原理上就不能充分利用内存的上述特征实现某些高速算法。基于 SQL 的内存数据库,通常只是简单的照搬外存数据结构和运算,会出现各种问题。比如:记录式复制过多消耗 CPU 和内存;查找和 JOIN 性能没有达到极致。再比如集群方面:内存利用率过低;大量网络传输导致分机数量增加但性能反而下降;多机 JOIN 出现外存缓存等等。
开源数据计算引擎 SPL 扩展了数据类型和运算定义,可以充分利用内存的特征,从而实现多种高性能算法,让性能达到极致。其中,指针式复用利用内存特有的指针引用机制,节省了内存空间,而且速度更快。预关联同样利用指针引用机制,在初始化阶段完成很耗时的外键关联,后续计算中直接使用关联好的结果,计算速度显著提高。序号定位利用有序性,充分发挥内存高速随机访问的优势,不用做任何计算和比对,直接用序号读取记录,性能好于 HASH 索引等查找算法。集群维表有效避免或减少了网络传输、避免了外存缓存,备胎式容错在保证高可用性的前提下,有效提高了集群内存利用率。
七、SPL
- SPL官网
- SPL下载
- SPL源代码
欢迎对SPL有兴趣的加小助手(VX号:SPL-helper),进SPL技术交流群
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/200083.html原文链接:https://javaforall.net


