
1.双向链表的定义
/*随机数的范围*/ #define MAX 100 /*节点结构*/ typedef struct Node{
struct Node *pre; int data; struct Node *next; }Node; 2.双向链表的创建
#define MAX 100 Node *CreatNode(Node *head) {
head=(Node*)malloc(sizeof(Node));//鍒涘缓閾捐〃绗竴涓粨鐐癸紙棣栧厓缁撶偣锛? if(head == NULL) {
printf("malloc error!\r\n"); return NULL; } head->pre=NULL; head->next=NULL; head->data=rand()%MAX; return head; } Node* CreatList(Node * head,int length) {
if (length == 1) {
return( head = CreatNode(head)); } else {
head = CreatNode(head); Node * list=head; for (int i=1; i<length; i++) /*创建并初始化一个新结点*/ {
Node * body=(Node*)malloc(sizeof(Node)); body->pre=NULL; body->next=NULL; body->data=rand()%MAX; /*直接前趋结点的next指针指向新结点*/ list->next=body; /*新结点指向直接前趋结点*/ body->pre=list; /*把body指针给list返回*/ list=list->next; } } /*加上以下两句就是双向循环链表*/ // list->next=head; // head->prior=list; return head; } 3.双向链表的插入
2.添加至表的中间位置
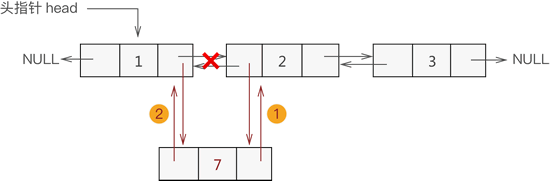
同单链表添加数据类似,双向链表中间位置添加数据需要经过以下 2 个步骤,如下图所示:
新节点先与其直接后继节点建立双层逻辑关系;
新节点的直接前驱节点与之建立双层逻辑关系;

3.添加至表尾
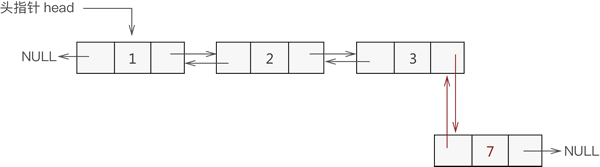
与添加到表头是一个道理,实现过程如下:
找到双链表中最后一个节点;
让新节点与最后一个节点进行双层逻辑关系;
/*在第add位置的前面插入data节点*/ Node * InsertListHead(Node * head,int add,int data) {
/*新建数据域为data的结点*/ Node * temp=(Node*)malloc(sizeof(Node)); if(temp== NULL) {
printf("malloc error!\r\n"); return NULL; } else {
temp->data=data; temp->pre=NULL; temp->next=NULL; } /*插入到链表头,要特殊考虑*/ if (add==1) {
temp->next=head; head->pre=temp; head=temp; } else {
Node * body=head; /*找到要插入位置的前一个结点*/ for (int i=1; i<add-1; i++) {
body=body->next; } /*判断条件为真,说明插入位置为链表尾*/ if (body->next==NULL) {
body->next=temp; temp->pre=body; } else {
body->next->pre=temp; temp->next=body->next; body->next=temp; temp->pre=body; } } return head; } /*在第add位置的后面插入data节点*/ Node * InsertListEnd(Node * head,int add,int data) {
int i = 1; /*新建数据域为data的结点*/ Node * temp=(Node*)malloc(sizeof(Node)); temp->data=data; temp->pre=NULL; temp->next=NULL; Node * body=head; while ((body->next)&&(i<add+1)) {
body=body->next; i++; } /*判断条件为真,说明插入位置为链表尾*/ if (body->next==NULL) {
body->next=temp; temp->pre=body; temp->next=NULL; } else {
temp->next=body->pre->next; temp->pre=body->pre; body->next->pre=temp; body->pre->next=temp; } return head; } 4.双向链表的删除
Node * DeleteList(Node * head,int data) {
Node * temp=head; /*遍历链表*/ while (temp) {
/*判断当前结点中数据域和data是否相等,若相等,摘除该结点*/ if (temp->data==data) {
/*判断是否是头结点*/ if(temp->pre == NULL) {
head=temp->next; temp->next = NULL; free(temp); return head; } /*判断是否是尾节点*/ else if(temp->next == NULL) {
temp->pre->next=NULL; free(temp); return head; } else {
temp->pre->next=temp->next; temp->next->pre=temp->pre; free(temp); return head; } } temp=temp->next; } printf("Can not find %d!\r\n",data); return head; } 5.双向链表更改节点数据
更改双链表中指定结点数据域的操作是在查找的基础上完成的。实现过程是:通过遍历找到存储有该数据元素的结点,直接更改其数据域即可。
/*更新函数,其中,add 表示更改结点在双链表中的位置,newElem 为新数据的值*/ Node *ModifyList(Node * p,int add,int newElem) {
Node * temp=p; /*遍历到被删除结点*/ for (int i=1; i<add; i++) {
temp=temp->next; } temp->data=newElem; return p; } 6.双向链表的查找
通常,双向链表同单链表一样,都仅有一个头指针。因此,双链表查找指定元素的实现同单链表类似,都是从表头依次遍历表中元素。
/*head为原双链表,elem表示被查找元素*/ int FindList(Node * head,int elem) {
/*新建一个指针t,初始化为头指针 head*/ Node * temp=head; int i=1; while (temp) {
if (temp->data==elem) {
return i; } i++; temp=temp->next; } /*程序执行至此处,表示查找失败*/ return -1; } 7.双向链表的打印
/*输出链表的功能函数*/ void PrintList(Node * head) {
Node * temp=head; while (temp) {
/*如果该节点无后继节点,说明此节点是链表的最后一个节点*/ if (temp->next==NULL) {
printf("%d\n",temp->data); } else {
printf("%d->",temp->data); } temp=temp->next; } } 8.测试函数及结果
int main() {
Node * head=NULL; //创建双链表 head=CreatList(head,5); printf("新创建双链表为\t"); PrintList(head); //在表中第 5 的位置插入元素 1 head=InsertListHead(head, 5,1); printf("在表中第 5 的位置插入元素 1\t"); PrintList(head); //在表中第 3 的位置插入元素 7 head=InsertListEnd(head, 3, 7); printf("在表中第 3 的位置插入元素 7\t"); PrintList(head); // //表中删除元素 7 head=DeleteList(head, 7); printf("表中删除元素 7\t\t\t"); PrintList(head); printf("元素 1 的位置是\t:%d\n",FindList(head,1)); //表中第 3 个节点中的数据改为存储 6 head = ModifyList(head,3,6); printf("表中第 3 个节点中的数据改为存储6\t"); PrintList(head); return 0; } 
大家的鼓励是我继续创作的动力,如果觉得写的不错,欢迎关注,点赞,收藏,转发,谢谢!
以上代码均为测试后的代码。如有错误和不妥的地方,欢迎指出。
部分内容参考网络,如有侵权,请联系删除。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/201399.html原文链接:https://javaforall.net


