
什么是联邦学习?
简单来说就是在一个多方的环境中,数据集是零散的(在各个不同的客户端中),那么怎样实现机器学习算法呢?
首先想到的就是将多个数据集合并合并起来,然后统一的使用传统的机器学习或者深度学习算法进行计算,但是如果有一方因为数据隐私问题不愿意提交自己的数据呢?
那么就出现了联邦学习,核心就是“数据不动模型动,数据可用不可见”
多个客户端不提交数据而是提交训练时的参数/梯度给中心服务器,中心服务器进行计算后再将参数/梯度返回多个客户端再学习的过程
整个过程数据的所有权依然在用户手中,这就是联邦学习
当然数据隐私方面,联邦学习还将结合同态加密、安全多方计算、查分隐私等隐私计算技术实现更安全的保障
(ps:这里只是简单的介绍,详细的内容请多查阅其他资料)
基本概念入门学习见:《Federated_Machine_Learning:Concept_and_Applications》精读
一、环境准备
实验基于机器学习库PyTorch, 所以需要一些基础的PyTorch使用
(ps:不会也没事,下面代码有详细的注释,因为我也刚刚入门 ? )
- anaconda、python3.7、PyTorch
pip install torch - GPU安装
CUDA、cuDNN
二、横向联邦图像分类
基本信息
数据集:CIFAR10
模型:ResNet-18
环境角色:
- 中心服务器
- 多个客户端
为了简化,这里服务器客户端都是在单机上模拟,后面使用FATE会在真实多台机器上实现
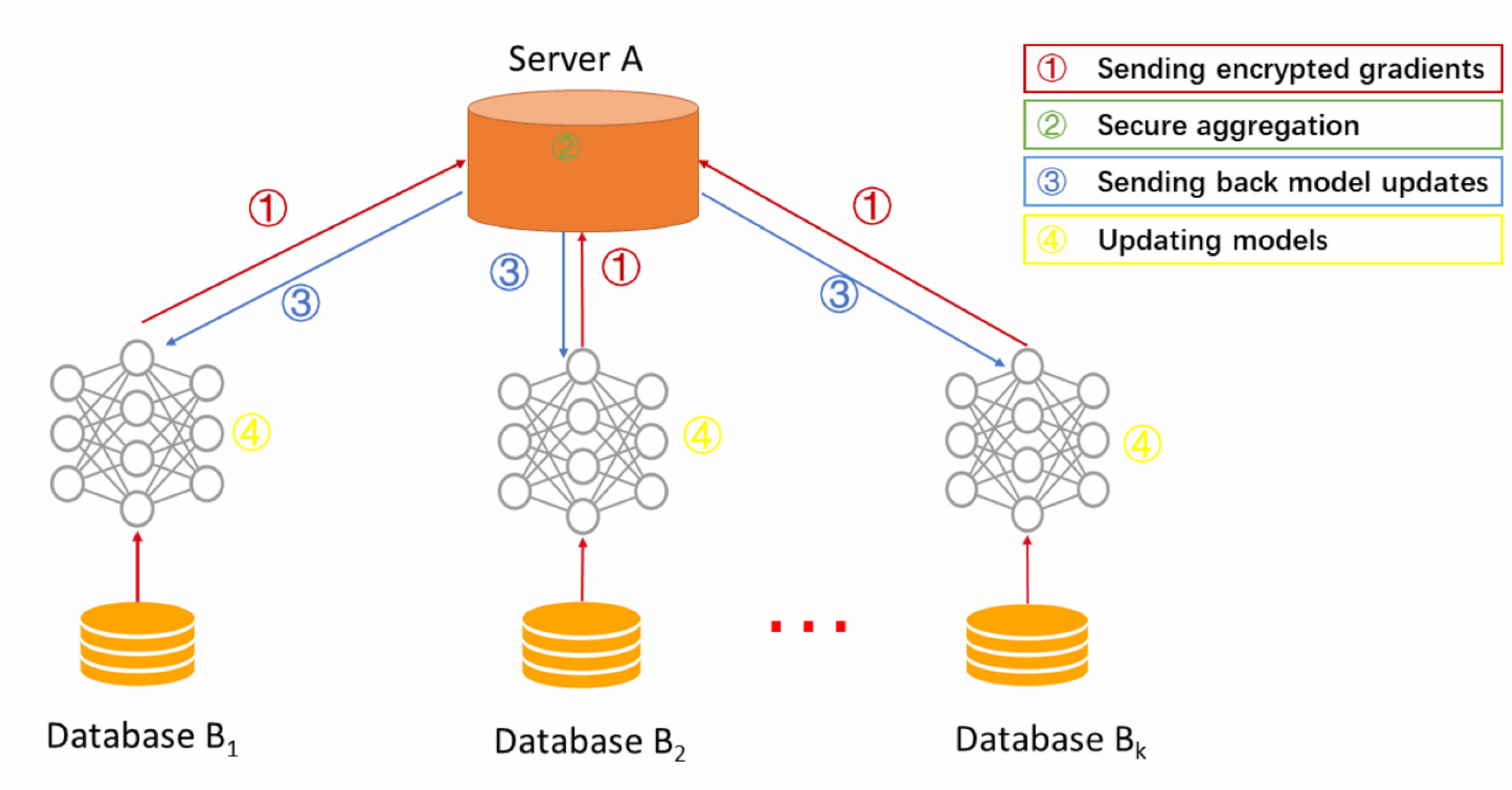

基本的流程:
- 服务器按配置生成初始化模型,客户端按照顺序将数据集横向不重叠切割
- 服务器将全局模型发送给客户端
- 客户端接收全局模型(来自服务器)通过本地多次迭代计算本地参数差值返回给服务器
- 服务器聚合各个客户端差值更新模型,再评估当前模型性能
- 如果性能未达标,则重复2过程,否则结束
2.1 配置文件
配置文件包含了整个项目的模型、数据集、epoch等核心训练参数
需要注意的是,一般来说配置文件需要在所有的客户端与服务端之间同步一致
创建一个配置文件:
项目文件夹下./utils/conf.json创建配置文件:
{
"model_name" : "resnet18", "no_models" : 10, "type" : "cifar", "global_epochs" : 20, "local_epochs" : 3, "k" : 6, "batch_size" : 32, "lr" : 0.001, "momentum" : 0.0001, "lambda" : 0.1 } - model_name:模型名称
- no_models:客户端总数量
- type:数据集信息
- global_epochs:全局迭代次数,即服务端与客户端的通信迭代次数
- local_epochs:本地模型训练迭代次数
- k:每一轮迭代时,服务端会从所有客户端中挑选k个客户端参与训练。
- batch_size:本地训练每一轮的样本数
- lr,momentum,lambda:本地训练的超参数设置
2.1 构建训练数据集
构建数据集代码如下:
datasets.py
import torchvision as tv # 获取数据集 def get_dataset(dir, name): if name == 'mnist': # root: 数据路径 # train参数表示是否是训练集或者测试集 # download=true表示从互联网上下载数据集并把数据集放在root路径中 # transform:图像类型的转换 train_dataset = tv.datasets.MNIST(dir, train=True, download=True, transform=tv.transforms.ToTensor()) eval_dataset = tv.datasets.MNIST(dir, train=False, transform=tv.transforms.ToTensor()) elif name == 'cifar': # 设置两个转换格式 # transforms.Compose 是将多个transform组合起来使用(由transform构成的列表) transform_train = tv.transforms.Compose([ # transforms.RandomCrop: 切割中心点的位置随机选取 tv.transforms.RandomCrop(32, padding=4), tv.transforms.RandomHorizontalFlip(), tv.transforms.ToTensor(), # transforms.Normalize: 给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化 tv.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) transform_test = tv.transforms.Compose([ tv.transforms.ToTensor(), tv.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) train_dataset = tv.datasets.CIFAR10(dir, train=True, download=True, transform=transform_train) eval_dataset = tv.datasets.CIFAR10(dir, train=False, transform=transform_test) return train_dataset, eval_dataset 2.2 服务端
服务端的主要功能是模型的聚合、评估,最终的模型也是在服务器上生成
首先创建一个服务类
所有的程序放在server.py
构造函数
定义其构造函数:
# 定义构造函数 def __init__(self, conf, eval_dataset): # 导入配置文件 self.conf = conf # 根据配置获取模型文件 self.global_model = models.get_model(self.conf["model_name"]) # 生成一个测试集合加载器 self.eval_loader = torch.utils.data.DataLoader( eval_dataset, # 设置单个批次大小32 batch_size=self.conf["batch_size"], # 打乱数据集 shuffle=True ) 聚合函数
定义全局联邦平均FedAvg聚合函数:
FedAvg算法的公式如下:
G t + 1 = G t + λ ∑ i = 1 m ( L i t + 1 − G i t ) G^{t+1} = G^{t} + \lambda \sum^m_{i=1}(L_i^{t+1}-G_i^t) Gt+1=Gt+λ∑i=1m(Lit+1−Git)
G t G^t Gt表示第t轮更新的全局模型参数, L i t + 1 L_i^{t+1} Lit+1表示第i个客户端在第t+1轮本地更新后的模型
在模型聚合时,weight_accumulator就是 ( L i t + 1 − G i t ) i = 1 , 2 , . . . m (L_i^{t+1}-G_i^t) \ i = 1,2,…m (Lit+1−Git) i=1,2,...m部分,具体weight_accumulator的计算会在后面详细介绍其实现
# 全局聚合模型 # weight_accumulator 存储了每一个客户端的上传参数变化值/差值 def model_aggregate(self, weight_accumulator): # 遍历服务器的全局模型 for name, data in self.global_model.state_dict().items(): # 更新每一层乘上学习率 update_per_layer = weight_accumulator[name] * self.conf["lambda"] # 累加和 if data.type() != update_per_layer.type(): # 因为update_per_layer的type是floatTensor,所以将起转换为模型的LongTensor(有一定的精度损失) data.add_(update_per_layer.to(torch.int64)) else: data.add_(update_per_layer) 评估函数
定义模型评估函数
评估函数主要是不断的评估当前模型的性能,判断是否可以提前终止迭代或者是出现了发散退化等现象
# 评估函数 def model_eval(self): self.global_model.eval() # 开启模型评估模式(不修改参数) total_loss = 0.0 correct = 0 dataset_size = 0 # 遍历评估数据集合 for batch_id, batch in enumerate(self.eval_loader): data, target = batch # 获取所有的样本总量大小 dataset_size += data.size()[0] # 存储到gpu if torch.cuda.is_available(): data = data.cuda() target = target.cuda() # 加载到模型中训练 output = self.global_model(data) # 聚合所有的损失 cross_entropy交叉熵函数计算损失 total_loss += torch.nn.functional.cross_entropy( output, target, reduction='sum' ).item() # 获取最大的对数概率的索引值, 即在所有预测结果中选择可能性最大的作为最终的分类结果 pred = output.data.max(1)[1] # 统计预测结果与真实标签target的匹配总个数 correct += pred.eq(target.data.view_as(pred)).cpu().sum().item() acc = 100.0 * (float(correct) / float(dataset_size)) # 计算准确率 total_1 = total_loss / dataset_size # 计算损失值 return acc, total_1 2.3 客户端
客户端的主要功能是:
- 接受服务器下发的指令和全局模型
- 利用本地数据进行局部模型训练
此部分所有程序都在client.py中
构造函数
定义client类
# 构造函数 def __init__(self, conf, model, train_dataset, id = 1): # 配置文件 self.conf = conf # 客户端本地模型(一般由服务器传输) self.local_model = model # 客户端ID self.client_id = id # 客户端本地数据集 self.train_dataset = train_dataset # 按ID对训练集合的拆分 all_range = list(range(len(self.train_dataset))) data_len = int(len(self.train_dataset) / self.conf['no_models']) indices = all_range[id * data_len: (id + 1) * data_len] # 生成一个数据加载器 self.train_loader = torch.utils.data.DataLoader( # 制定父集合 self.train_dataset, # batch_size每个batch加载多少个样本(默认: 1) batch_size=conf["batch_size"], # 指定子集合 # sampler定义从数据集中提取样本的策略 sampler=torch.utils.data.sampler.SubsetRandomSampler(indices) ) 本案例中根据ID将数据集进行横向切分,每个客户端之间没有交集
本地训练
本地模型训练函数:采用交叉熵作为本地训练的损失函数,并使用梯度下降来求解参数
# 模型本地训练函数 def local_train(self, model): # 整体的过程:拉取服务器的模型,通过部分本地数据集训练得到 for name, param in model.state_dict().items(): # 客户端首先用服务器端下发的全局模型覆盖本地模型 self.local_model.state_dict()[name].copy_(param.clone()) # 定义最优化函数器用于本地模型训练 optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'], momentum=self.conf['momentum']) # 本地训练模型 self.local_model.train() # 设置开启模型训练(可以更改参数) # 开始训练模型 for e in range(self.conf["local_epochs"]): for batch_id, batch in enumerate(self.train_loader): data, target = batch # 加载到gpu if torch.cuda.is_available(): data = data.cuda() target = target.cuda() # 梯度 optimizer.zero_grad() # 训练预测 output = self.local_model(data) # 计算损失函数 cross_entropy交叉熵误差 loss = torch.nn.functional.cross_entropy(output, target) # 反向传播 loss.backward() # 更新参数 optimizer.step() print("Epoch %d done" % e) # 创建差值字典(结构与模型参数同规格),用于记录差值 diff = dict() for name, data in self.local_model.state_dict().items(): # 计算训练后与训练前的差值 diff[name] = (data - model.state_dict()[name]) print("Client %d local train done" % self.client_id) # 客户端返回差值 return diff 2.4 整合
所有程序代码在main.py中
import argparse import json import random import datasets from client import * from server import * if __name__ == '__main__': # 设置命令行程序 parser = argparse.ArgumentParser(description='Federated Learning') parser.add_argument('-c', '--conf', dest='conf') # 获取所有的参数 args = parser.parse_args() # 读取配置文件 with open(args.conf, 'r') as f: conf = json.load(f) # 获取数据集, 加载描述信息 train_datasets, eval_datasets = datasets.get_dataset("./data/", conf["type"]) # 开启服务器 server = Server(conf, eval_datasets) # 客户端列表 clients = [] # 添加10个客户端到列表 for c in range(conf["no_models"]): clients.append(Client(conf, server.global_model, train_datasets, c)) print("\n\n") # 全局模型训练 for e in range(conf["global_epochs"]): print("Global Epoch %d" % e) # 每次训练都是从clients列表中随机采样k个进行本轮训练 candidates = random.sample(clients, conf["k"]) print("select clients is: ") for c in candidates: print(c.client_id) # 权重累计 weight_accumulator = {
} # 初始化空模型参数weight_accumulator for name, params in server.global_model.state_dict().items(): # 生成一个和参数矩阵大小相同的0矩阵 weight_accumulator[name] = torch.zeros_like(params) # 遍历客户端,每个客户端本地训练模型 for c in candidates: diff = c.local_train(server.global_model) # 根据客户端的参数差值字典更新总体权重 for name, params in server.global_model.state_dict().items(): weight_accumulator[name].add_(diff[name]) # 模型参数聚合 server.model_aggregate(weight_accumulator) # 模型评估 acc, loss = server.model_eval() print("Epoch %d, acc: %f, loss: %f\n" % (e, acc, loss)) 2.5 测试
按照以上配置,(本人)运行后的准确度以及损失为:

官方的对比:
联邦学习与中心化训练的效果对比
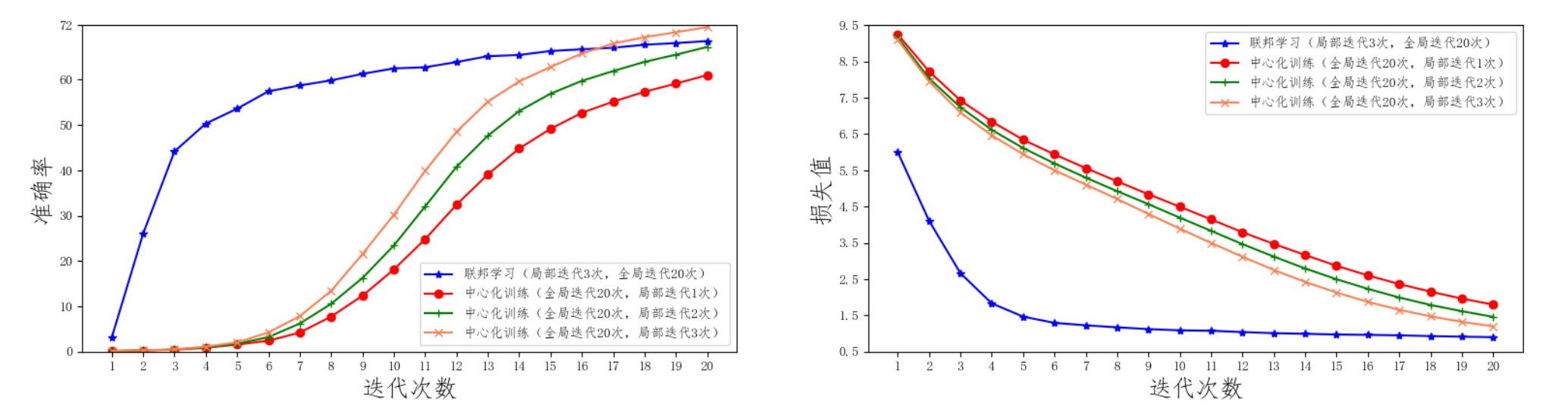
- 联邦训练配置:一共10台客户端设备(no_models=10),每一轮任意挑选其中的5台参与训练(k=5), 每一次本地训练迭代次数为3次(local_epochs=3),全局迭代次数为20次(global_epochs=20)。
- 集中式训练配置:我们不需要单独编写集中式训练代码,只需要修改联邦学习配置既可使其等价于集中式训练。具体来说,我们将客户端设备no_models和每一轮挑选的参与训练设备数k都设为1即可。这样只有1台设备参与的联邦训练等价于集中式训练。其余参数配置信息与联邦学习训练一致。图中我们将局部迭代次数分别设置了1,2,3来进行比较。
联邦学习在模型推断上的效果对比
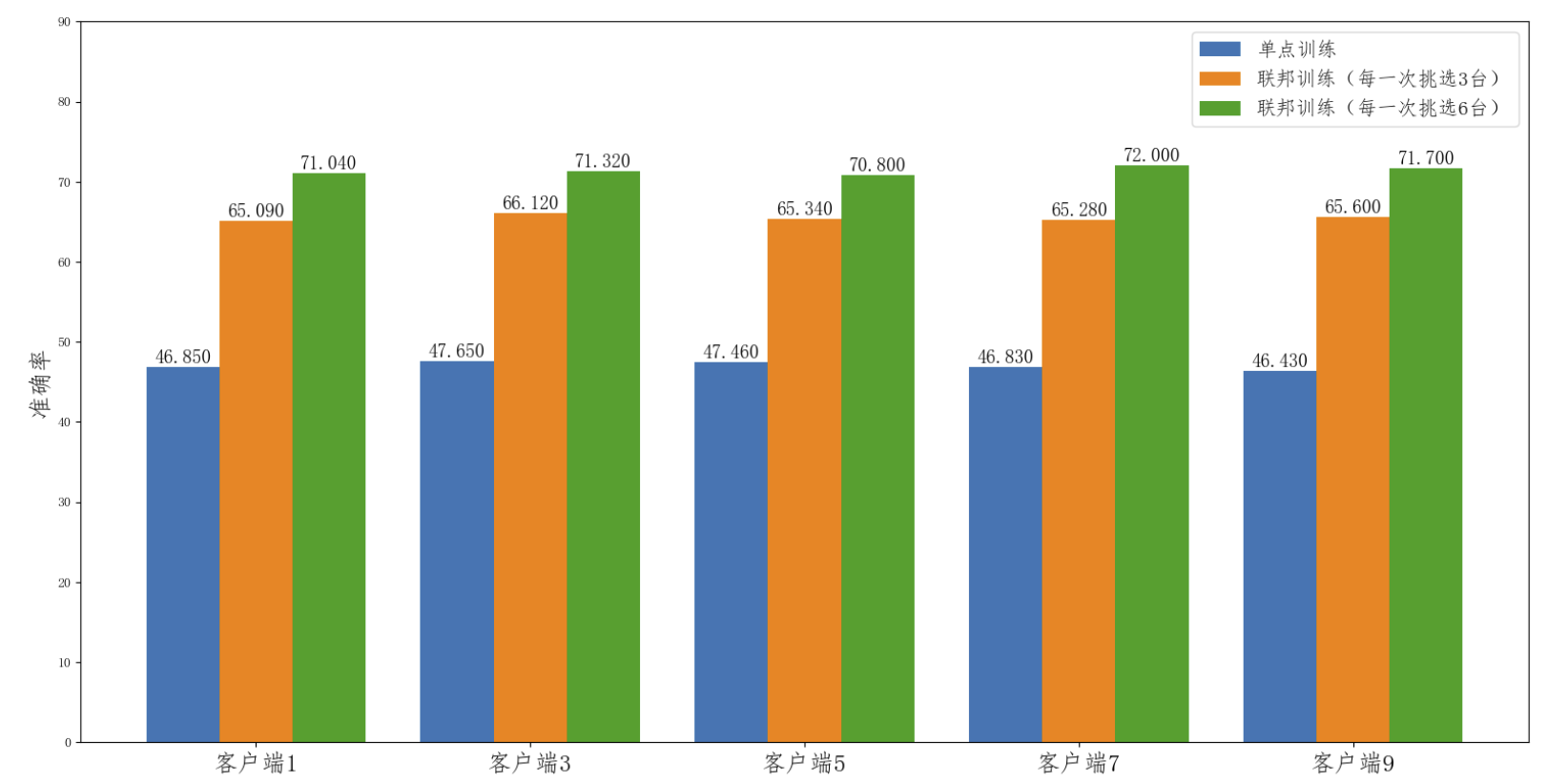
图中的单点训练只的是在某一个客户端下,利用本地的数据进行模型训练的结果。
- 我们看到单点训练的模型效果(蓝色条)明显要低于联邦训练 的效果(绿色条和红色条),这也说明了仅仅通过单个客户端的数据,不能够 很好的学习到数据的全局分布特性,模型的泛化能力较差。
- 此外,对于每一轮 参与联邦训练的客户端数目(k 值)不同,其性能也会有一定的差别,k 值越大,每一轮参与训练的客户端数目越多,其性能也会越好,但每一轮的完成时间也会相对较长。
学习资料来自于:
杨强:《联邦学习实战》
https://github.com/FederatedAI/Practicing-Federated-Learning/tree/main/chapter03_Python_image_classification
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/201752.html原文链接:https://javaforall.net


