
什么是列式数据库?
列数据存储区也称为面向列的DBMS或列式数据库管理系统。列存储DBMS将数据存储在列而不是行中。关系数据库管理系统(RDBMS)将行中的数据和数据属性存储为列标题。基于行的DBMS和基于列的DBMS都使用SQL作为查询语言,但是面向列的DBMS可能会提供更好的查询性能。假设您需要根据ID列出表中的所有名称;而不是遍历所有行,您可以只访问表的单个列。
以下是列数据存储DBMS的一些关键特性。
- 列存储DBMS使用的键空间类似于RDBMS中的数据库架构。
- 列存储DBMS具有称为列族的概念。列族就像RDBMS上的表,键空间包含数据库中的所有列族。
- 列族包含多个行,每行都有一个唯一的键,称为行键,这是该行的唯一标识符。
- 列存储数据库中的每一列都有一个“名称”,“值”和“时间戳记”字段。
- 每行可以包含不同数量的列,所有行都不必具有相同的列。
- 每列可以包含多行,所有行都不必具有相同的数据类型或大小。
键空间(Keyspace)
列存储DBMS使用的键空间类似于RDBMS中的数据库架构。键空间包含所有列族,键空间名称可以是CMS数据库,用于存储用户配置文件、文档和文档元数据。
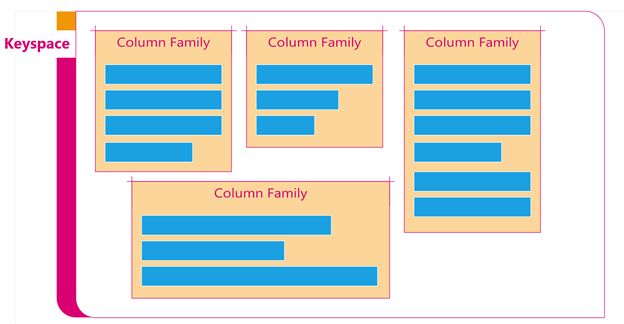

列族(Column Family)
列族就像RDBMS中的表,一个键空间可以有多个列族。例如,键空间可以具有以下列列族AuthorProfile,MemberProfile,Article,Blog和Question。
行键(Row key)
列族包含多个行。下面是列族行的示例,行中的第一项是单值行键,它是标识行的唯一键。

列(Column)
每行可以有多列。列数据存储中的一列包含实际值。列存储数据库中的数据存储在带有时间戳的键/值对中,每行可以具有不同数量的列。
AuthorProfile
以下是具有三行的AuthorProfile列族,每行具有不同数量和类型的列。从数据中可以看到,每行都有唯一的行键。

列族的三行是Mahesh,David和Allen。第一行包含三列:性别,专业知识和等级。第二行有两列,性别和书本。第三行包含三列:城市,图书和等级。
列式存储的主要优点
列存储数据库的主要优点包括更快的加载,搜索和聚合。列存储数据库具有可伸缩性,可以在几秒钟内读取数十亿条记录。列存储数据库在数据压缩和分区方面也比传统的行存储更有效。
流行的列式数据库
一些流行的面向列的DBMS包括Bigtable,Cassandra,HBase,Druid,Hypertable,MariaDB,Azure SQL Data warehouse,Google BigQuery,IBM Db2,MemSQL,SQL Server和SAP HANA。
Google BigTable
Google Bigtable是PB级的列存储数据库,一个完全托管的NoSQL数据库服务,支持大型分析和业务操作的工作负载。主要功能包括:
- 低延迟,可大规模扩展的NoSQL
- 保证数据一致的情况下,实现10毫秒以下延迟
- 通过复制提供高可用、更高的持久性和弹性以解决区域数据故障
- 适用于互联网广告技术,金融科技和物联网等应用
- 面向机器学习应用的存储引擎
- 与开源大数据工具轻松集成
Apache Cassandra
Apache Cassandra NoSQL数据库在不降低性能的前提下,提供很强的扩展性和高可用。线性可扩展,以及在商用硬件或云基础架构上经过验证的容错能力使它成为关键数据处理的理想平台。Cassandra对跨多个数据中心的复制提供了一流的支持,为您的用户提供了更低的延迟,并且帮助您的客户在区域数据中心故障的情况下保持数据可用,让用户安心无忧。
Apache HBase
Apache HBase是开源、分布式和可扩展的NoSQL大数据存储平台,它可以在几秒钟内访问数十亿行大数据。主要功能包括:
- 线性扩展和模块化
- 严格一致的读写
- 表的自动分片,并且可配置
- 支持RegionServer之间的自动故障转移
- 方便的基类,可以在Apache HBase表中备份Hadoop MapReduce作业
- 易于使用的Java API用于客户端访问
- 用于实时查询的块缓存和布隆过滤器
- 通过服务器端过滤器支持谓词下推
- Thrift网关和REST-ful Web服务支持XML、Protobuf和二进制数据编码
- 可扩展的基于jruby的(JIRB)shell
注:以上内容由google翻译,重新调整和排版而成,有不妥之处,可参考原文: https://www.c-sharpcorner.com/article/what-is-a-column-store-database/
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/204233.html原文链接:https://javaforall.net

![MATLAB R2013a license.lic 过期问题[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
