
最有价值的,不是答案本身,而是诞生答案的过程。
说白了,就是某个数据,数据库有,但是缓存中没有。
那么,缓存击穿,就会使得因为这一个热点数据,将大量并发请求打击到数据库上,从而导致数据库被打垮。
要解决这个问题之前,我们就先得对整个系统的架构有一定的了解:
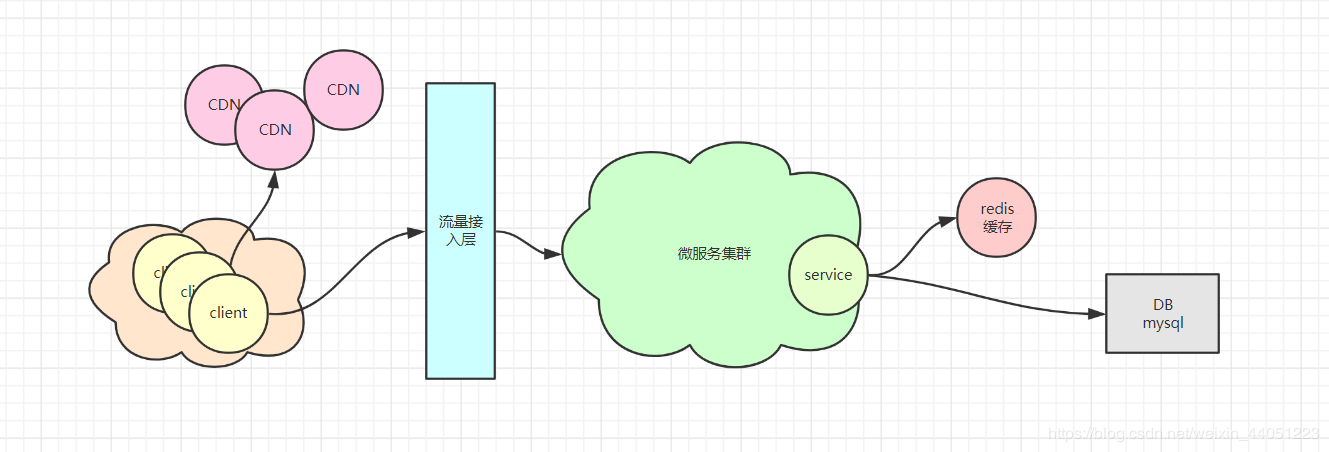

而我们的 redis,在整个系统体系中,作为缓存,就是将很多的请求抗住,过滤掉,
所以最后的数据库的压力就会很小。
那么既然 redis 是作为缓存,
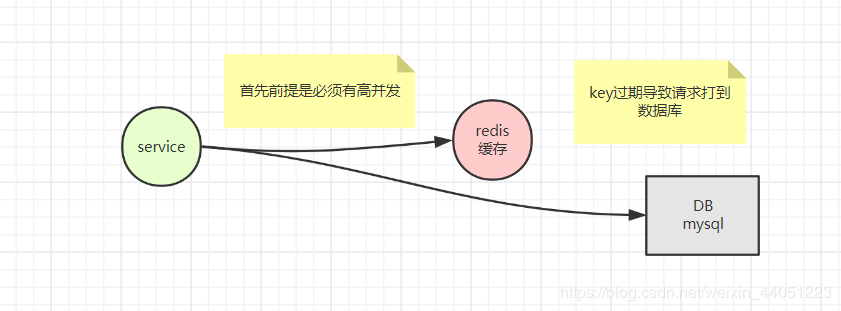
那么在高并发的情况下,一个 key 过期了,然后,就是几千几万的并发蜂拥而至,这该怎么解决?
首先,大部分人会想到这么一个答案:热点数据永不过期。
在网络上盛行的解决方案有很多:
下面我来详细分析,为什么,这些解决方案,在实际的生产环境中,是无法胜任的。
首先,我来分析,key 永不失效的解决方案,为什么不可行。
但是,你可以说,只存热点数据啊!
但是,什么叫热点数据?你觉得是就是吗?
第二个,网络上很流行的答案就是:加锁
所以实际上,缓存穿透,加锁解决,必须还要涉及到分布式锁的概念。
这里不谈 zookeeper 之类的东西,既然谈 redis,那么就用 redis 来解决这个问题。
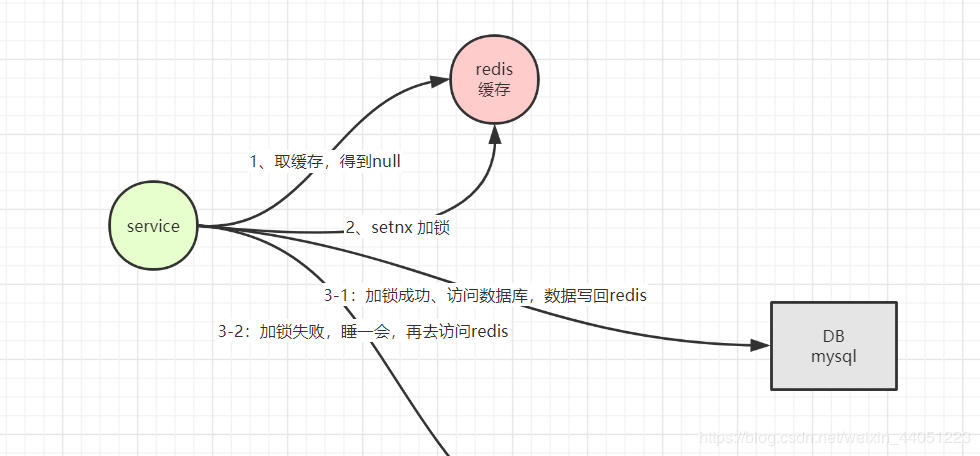
看起来似乎可行,但是,还有问题吗?
我要这么说肯定是有问题,但是,你可以想一想,存在什么问题?
如果你不知道,说明对分布式锁还不够了解,那么,就继续跟着我分析。
现在,我开始假设:
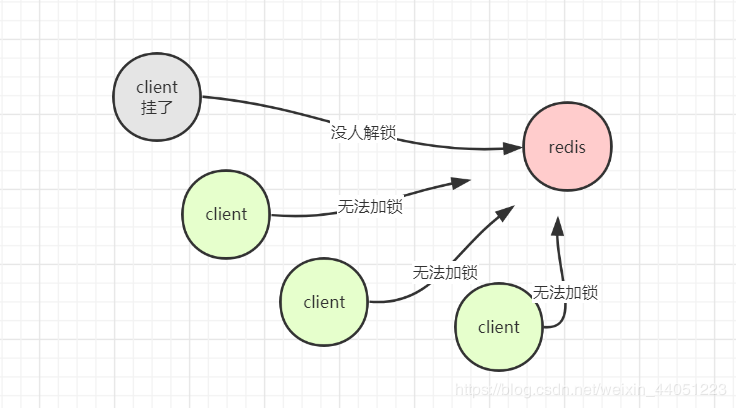
现在,既然出现了问题,那么,我们一定得想办法去解决。
明显,这么做成本比较高昂,还不如用完善的 zookeeper 去实现分布式锁。
于是,之前的方案,就可以稍作修改:
看起来很完美。
但是,还有问题吗?
我要这么问了,那么一定说明有。
那么,现在请你先不要拖到后文,先自己思考,会存在什么问题,然后再来看我的分析。
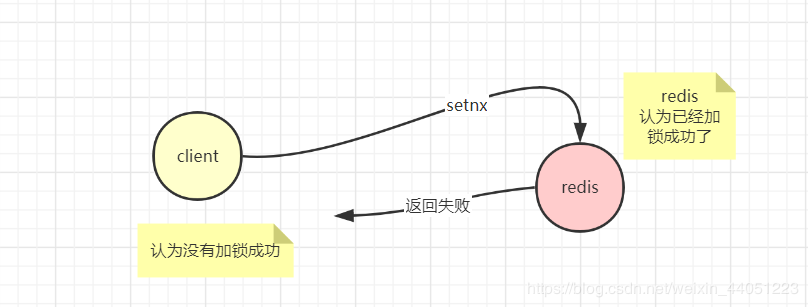
有些人可能就会说,那就放一个原子操作啊!
但是,redis 并没有一个 API,既可以 setnx,又同时给予它一个过期时间。
那该怎么办?
所以,这就需要考验,我们对 redis 的各种机制的掌握程度了。
那么不能回滚的事务也可以用来完成锁操作吗?
这样,就可以保证,redis 不会出现死锁的问题。
这样,解决了死锁问题,就看起来很完美了。
确实,如果只是解决了死锁的问题的情况下,是没有什么问题的。
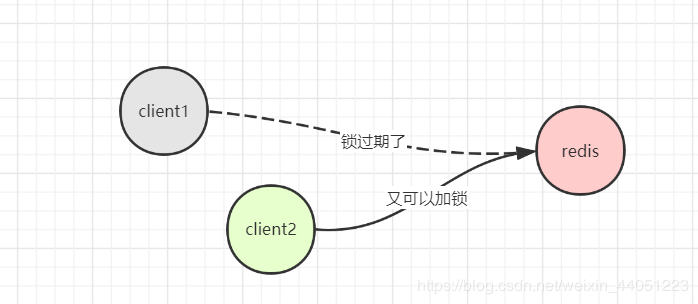
现在,假设:
所以,锁的超时时间又成了问题。
既然新问题出现了,我们就得想办法去解决它。
而现在普遍的解决方案,就是多线程:
于是就出现下面这样的场景:
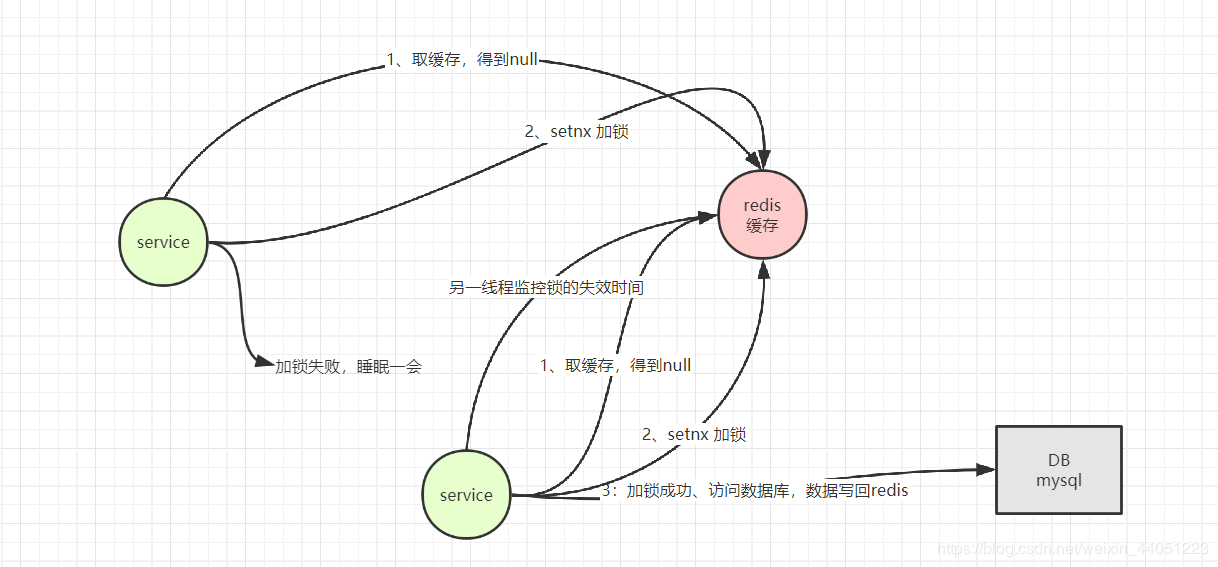
是不是觉得巨麻烦,竟然要从头到尾经历这么多的过程,才能最终,实现一个不起眼的缓存穿透!
假设:
所以说,通过双线程的加锁操作,是可以解决缓存击穿的问题的。
对于单个 redis 来说,上面的知识点已经可以实现分布式锁了。
但是,既然要讨论高并发高可用的系统,就会涉及到集群。
对于单个 redis 来说,假设,加锁的 redis 挂了,那该怎么办?
所以,这把锁很可能就丢了。
为了能够解决这样的问题,Redis 的作者 antirez 给出了一个更好的实现,称为 Redlock,算是 Redis 官方对于实现分布式锁的指导规范。
如果你们不善于阅读英文,那么就直接看我中文的描述:
在算法的分布式版本中,我们假设有 N 个 redis,且这些节点是完全独立的,也就是不存在任何主从关系,一个 redis 的死活和其他 redis 没有任何关系。
那么,应该给几台结点加锁呢?
所以,在整个加锁过程中,整个加锁的过程,不能超过锁的有效时间,否则,就应算作加锁失败,要立刻清除所有单独结点上的锁。
现在,想来你应该能大致理解,Redlock 加锁的大致过程了,下面我就用简略的语言,翻译一下官方对于 Redlock 的加锁操作:
看起来似乎很完美了,但是,我继续抛出一个问题。
假设一共有 5 个 redis ,分别是 ABCDE:
这是为什么呢?
因为这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
那就算一个 key 失效,也会对数据库造成很大的影响,那么你把雪崩的所有 key 拆成一个一个 key 来看,也就是雪崩可以拆分成一个一个缓存击穿的集合。
那么既然缓存击穿已经给过解决方案了,那么我们现在要关注的,则是如何缓解雪崩所带来的压力。
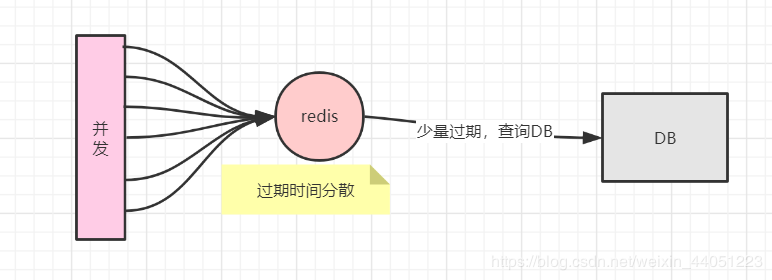
首先一个很常见的做法就是,分散 key 的过期时间。
看起来就很像一个削峰的操作。
这个方法,是最简单有效的。所以一般情况,我们都采用这种方式。
不过,要考虑一种情况,就是,如果你的业务对时点性要求高,必须每天的指定时间,去更新我们的数据。
就比如游戏每日零点更新,或者财报记录……等等等等。
像这样的业务应该怎么办?
这样可行吗?
所以,对于读请求,不适合用队列的方式,因为这已经把请求串行化了,不再是并发执行。
于是,还有人提出观点,让缓存提前开始更新。
所以,缓存是必须要在 12 点准时失效,准时更新的。你无法让更新时间进行变化。
那么,你还能想到什么办法?
既然 redis 不可以,那么其它地方可以吗?
所以,这就是考验你思维和功力的时候。
既然 redis 无法分散过期时间,那么,我们去查数据的时候,是不是可以把时间稍微地分散一下?
所以到了下面这种情景:
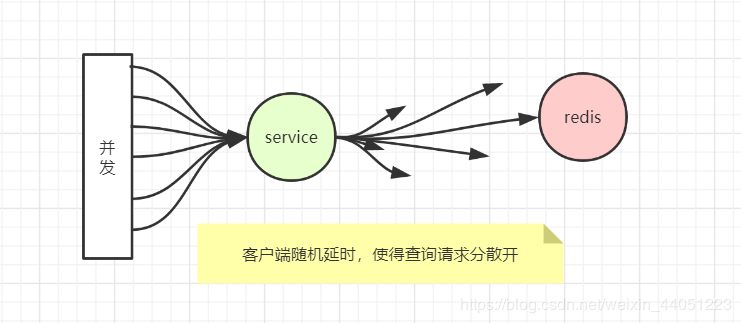
这就是,从业务层,再把时间分散。
带来的影响,也就是客户等待时,会多那么几十毫秒的延迟,不过对于人来说,是微乎其微,可以接受的。
所以,对于时点性要求高的业务要求,雪崩的问题,想要解决,还必须稍微多思考,变通一下。
所以,缓存击穿可以规避,因为只是 redis 缓存数据失效了,而数据库里有数据,只要把数据库里的数据更新到 redis 上,那么就可以解决掉缓存击穿的问题。
那么,想要解决缓存穿透,就必须想办法,能够识别出,哪些请求的数据,是数据库没有的,然后,对这些请求的查询,进行过滤。
如果你以前没有了解过这些知识,那你可以先想一想,可以用什么办法?
所以,是不是就可以额外开辟一片 Set,用来专门存储 key,这样,每次要访问数据库前,先去 key set 中查询时候存在,如果存在,那么再去访问数据库。
这样,确实可以使得缓存不会穿透了。而且相比缓存全量 key、value,只存储 key 会使得内存的占用变小了很多。
所以,到了数据面前,就能发现仍然是一个超高成本的方法。
那么,既然如果存储 key,空间仍然很大,那么我们能否想出一个更节省空间的存储方式?
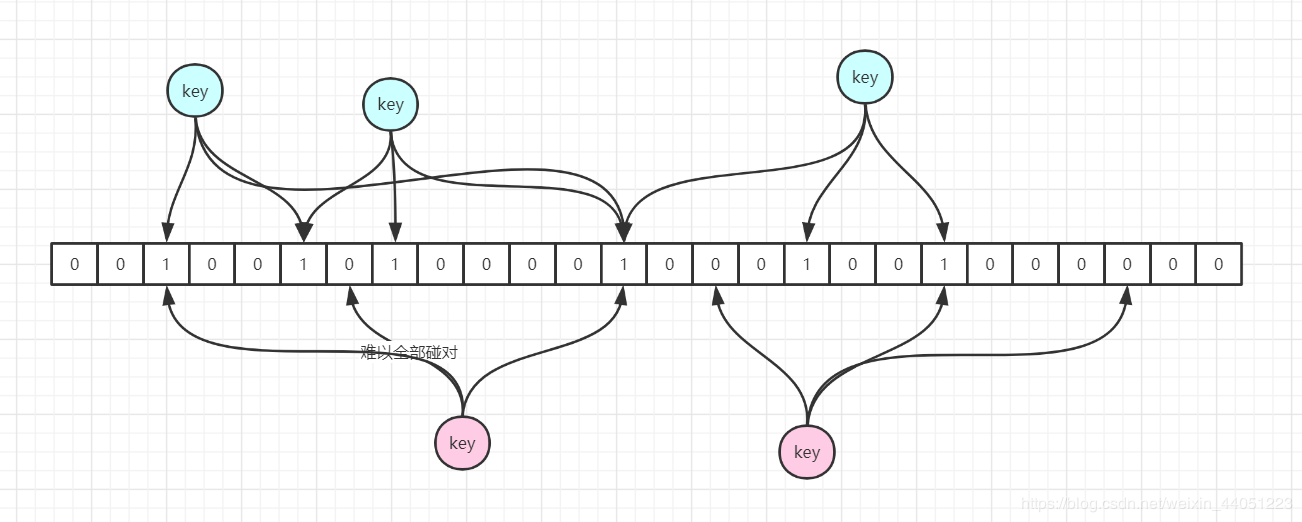
一般有点经验的都会想到用 bit,也就是用一个位来存储,这已经是计算机中的一个最小的存储单位了。
由此可见,用 bitmap,确确实实可以达到对空间利用的极致。
看起来似乎很完美,既解决了空间的问题,又可以保证每一个 key,能够映射到一个槽位上。
但是,仔细一思考,就会发现,其实还有问题。
那么,该怎么办?
这里也是如此,既然不能解决冲突问题,那么,可以想办法,让冲突发生的概率更小,而不是去完全地让冲突消失。
所以,就可以延伸到布隆算法。
这样,只要对应出我们的需求,去调整 bitmap 的大小,以及哈希函数的个数,就可以得到不同的过滤的百分比,虽然可能出现漏网之鱼,不过那也已经是少之又少了。
不过,对于布隆过滤器,我们的使用还是需要去思考一下的。
不管怎样,至少,穿透的问题,似乎已经迎来了大结局。
你现在想一想,是不是这么一个情况!
那么,解决的话,可以用布谷鸟这样的,带删除功能的,来满足动态变化的需求。
很多时候,对于一个问题,不是去拘泥于这个问题,而是你能够,联想到这个问题所置身的场景,能够理解清楚,整个系统的环境,能够从一个高的维度,去看这一系列的过程。
所以,对于我们来说,重要的,不是去背过这些答案,而是能够从一个系统、一个架构的角度,去理清设计的原由和思路。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/206011.html原文链接:https://javaforall.net


