
随着项目运行的时间越来越长,有些数据的存储也会越来越大,比如一些点击量,浏览量量,单表的数据可以到达上千万条数据,这时候会存在单表数据过大,查询效率低的问题,为了提高查询效率这时候需要对单表进行拆分,比如一张1000万条数据的表,我们需要把它拆分为10张表,一张表就需要100万,mysql中单表都有一个最大存储的阈值,数据量不能超过这个值;
分表之间,我们需要去生产一个上万条的数据的表,这里我生产了如下的数据:


我需要对这张表进行拆分多张,我这里拆分了2张表;
第一步:
表一:
DROP table IF EXISTS tb_member1; create table tb_member1( id bigint primary key auto_increment , name varchar(20), age tinyint not null default '0' )ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
- 1
- 2
- 3
- 4
- 5
- 6
表二:
DROP table IF EXISTS tb_member2; create table tb_member2( id bigint primary key auto_increment , name varchar(20), age tinyint not null default '0' )ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
- 1
- 2
- 3
- 4
- 5
- 6
接下来开始进行拆分:
insert into tb_member1(id,name,sex) select id,name,sex from dd_user where id%2=0; insert into tb_member2(id,name,sex) select id,name,sex from dd_user where id%2=1;
- 1
- 2
接下来,我们需要考虑的是一张user表被拆分成2张表,那分页如何实现呢?
第一步:
创建一个主表:
DROP table IF EXISTS tb_member_all; create table tb_member_all( id bigint primary key auto_increment , name varchar(20), age tinyint not null default '0' )ENGINE=MERGE UNION=(tb_member1,tb_member2) INSERT_METHOD=LAST CHARSET=utf8 AUTO_INCREMENT=1 ;
- 1
- 2
- 3
- 4
- 5
- 6
执行上述出现如下问题:
ERROR 1168 (HY000): Unable to open underlying table which is differently defined or of non-MyISAM type or doesn't exist
- 1
- 2
需要检查:
1:查看上面的分表数据库引擎是不是MyISAM.
2:查看分表与指标的字段定义是否一致。
上述的都成功以后,我们会发现,你在member1或者member2中创建数据member_all表中也会出现同样的数据
所以:tb_member_all表就是tb_member1,tb_member2的并集,刚刚实现到这里,我也没理解,后来看了一些文档,了解了一下:

其实tb_member_all表里面是没有存储数据,它就是一个外壳,里面的数据是tb_member1,tb_member2的并集,数据的存储是放在分表中;



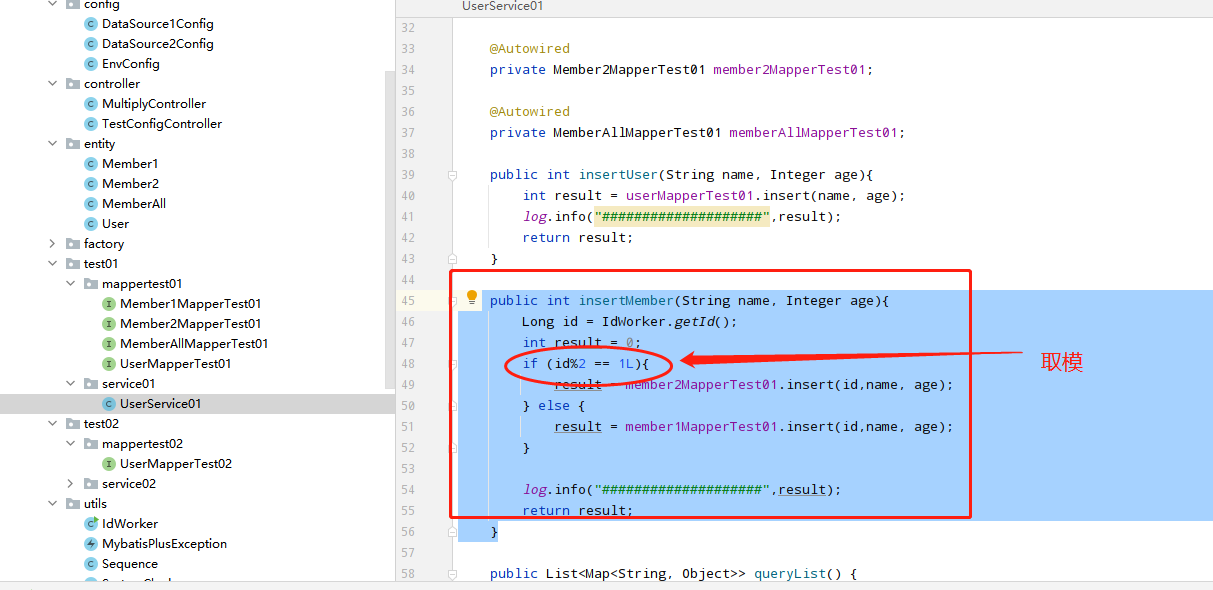
id%2这是取模处理,分配数据进入哪个数据;
原文链接传送门: https://blog.csdn.net/joy_tom/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/208423.html原文链接:https://javaforall.net


