

 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
1.官网下载安装:http://mxnet.incubator.apache.org/get_started 


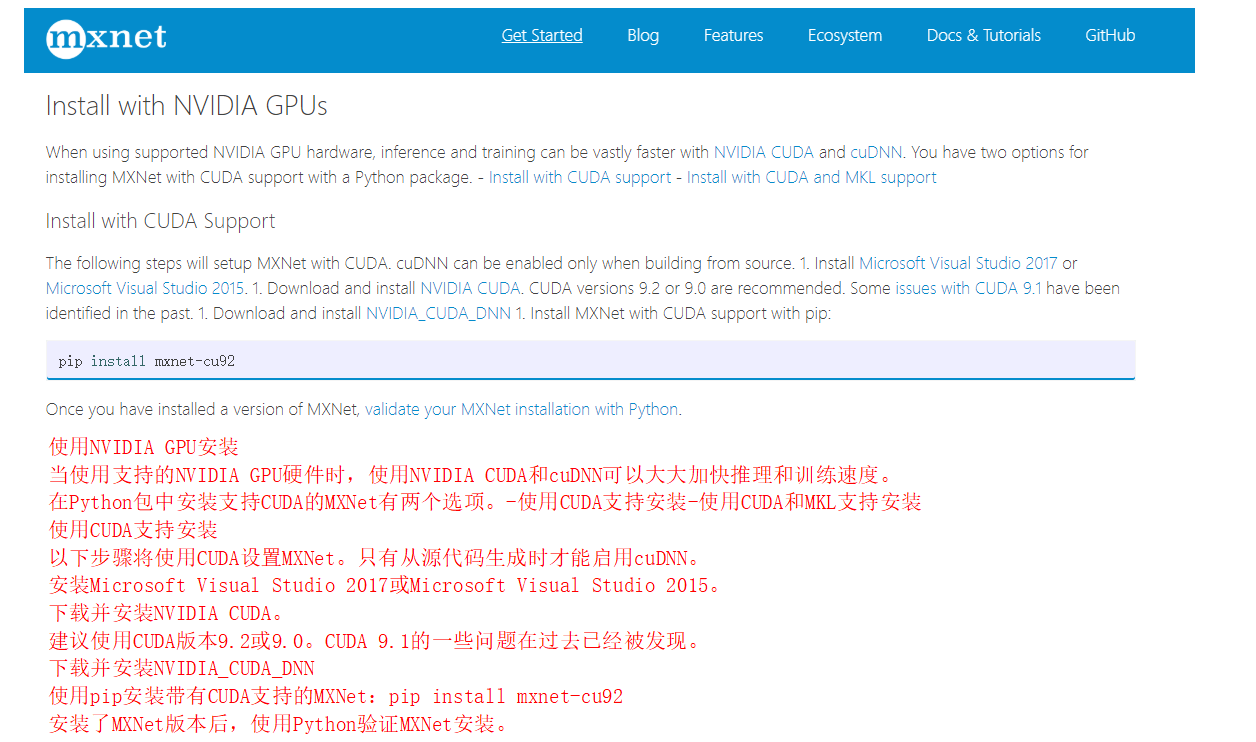
2.Window安装GPU版本的MXNet
http://mxnet.incubator.apache.org/get_started/windows_setup.html#install-with-nvidia-gpus

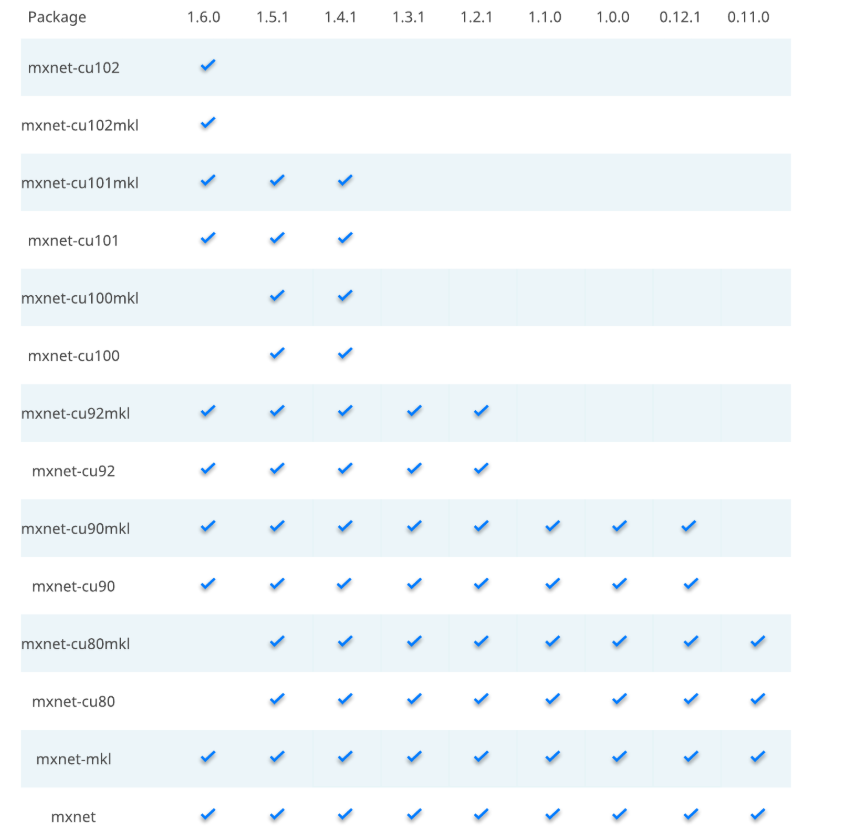
1.mxnet安装 1.方法一:Window装的是CUDA 10.0、cuDNN v7.6.5.32,那么可以选配安装的是 mxnet-cu100==1.5.1
2.方法二:官方MXNet文档的安装指引 https://zh.d2l.ai/chapter_prerequisite/install.html
2.d2lzh安装
方式一(建议):https://zh.d2l.ai/chapter_prerequisite/install.html
方式二:https://pypi.org/project/d2lzh/ 可以查看安装的d2lzh版本和命令 3.Python验证安装是否成功 http://mxnet.incubator.apache.org/get_started/validate_mxnet#python >>> import mxnet as mx >>> a = mx.nd.ones((2, 3), mx.gpu()) >>> b = a * 2 + 1 >>> b.asnumpy() array([[ 3., 3., 3.], [ 3., 3., 3.]], dtype=float32) 
1.《动手学 深度学习》电子书:https://zh.d2l.ai/d2l-zh.pdf 2.《动手学 深度学习》官网:https://zh.d2l.ai/ 3.《动手学 深度学习》github:https://github.com/d2l-ai/d2l-zh 4.《动手学 深度学习》代码:https://zh.d2l.ai/d2l-zh-1.0.zip 创建文件夹“d2l-zh”并将d2l-zh-1.0.zip压缩包解压到这个文件夹 5.conda和pip默认使用国外站点来下载MXNet和相关软件,我们可以配置国内镜像来加速下载。配置清华PyPI镜像(如无法运行,将pip版本升级到>=10.0.0) pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 6.安装 GPU版的 MXNet 1.d2l-zh-1.0.zip压缩包解压出来的文件有一个叫做environment.yml,文件信息包含要安装的软件和版本如下MXNet和d2lzh包及版本号: name: gluon dependencies: - python=3.6 - pip: - mxnet==1.4.0 - d2lzh==0.8.11 - jupyter==1.0.0 - matplotlib==2.2.2 - pandas==0.23.4 2.参数解析: 1.上述environment.yml文件中的“mxnet==1.4.0”代表的是 CPU版本的MXNet,安装 GPU版的 MXNet之前 需要先安装 CUDA、cuDNN。 environment.yml文件中的字符串“mxnet”替换成对应的GPU版本。例如,如果计算机上装的是8.0版本的CUDA,将该文件中的字符串“mxnet”改为“mxnet-cu80”。 如果计算机上安装了其他版本的CUDA(如7.5、9.0、9.2等),对该文件中的字符串“mxnet”做类似修改(如改为“mxnet-cu75”“mxnet-cu90”“mxnet-cu92”等)。 保存environment.yml文件后退出。 2.name: gluon 表示要创建新的虚拟环境的名字gluon 3.比如我装的是CUDA 9.0、cuDNN 7.1.4,然后把“mxnet==1.4.0”修改为“mxnet-cu90==1.4.0”,environment.yml文件修改后如下MXNet和d2lzh包及版本号: name: gluon dependencies: - python=3.6 - pip: - mxnet-cu90==1.4.0 - d2lzh==0.8.11 - jupyter==1.0.0 - matplotlib==2.2.2 - pandas==0.23.4 4.第一种安装方式:不创建新的虚拟环境,而是直接手动下载安装每个软件。 1.注意:可使用pip list 查看已经安装了什么软件和对应的版本号,如果已经安装了anaconda的话,则一般都已经自带同时装好了jupyter、matplotlib、pandas。 如果已经装好的软件的本地低于要求的版本可进行更新安装。 比如我的已经安装好了 jupyter 1.0.0、matplotlib 2.2.2、pandas 0.23.0,那么还仅需要安装mxnet-cu90 1.4.0、d2lzh 0.8.11, 和把 pandas 0.23.0 更新为 pandas 0.23.4,只需要执行 pip install pandas==0.23.4 即会自动卸载旧版本0.23.0 然后安装 0.23.4版本的了。 2.需要安装的 软件和版本号如下:注意根据自己的cuda版本安装对应的GPU版本的mxnet-cuxx==1.4.0 pip 安装方式: pip install mxnet-cu90==1.4.0 pip install d2lzh==0.8.11 pip install jupyter==1.0.0 pip install matplotlib==2.2.2 pip install pandas==0.23.4 conda 安装方式: conda install mxnet-cu90==1.4.0 conda install d2lzh==0.8.11 conda install jupyter==1.0.0 conda install matplotlib==2.2.2 conda install pandas==0.23.4 5.第二种安装方式:根据提供的 environment.yml文件直接进行创建虚拟环境gluon和下载安装对应版本的软件。 执行命令 conda env create -f environment.yml 表示用配置文件创建新的虚拟环境,该虚拟环境的名字为environment.yml文件中所配置的 name: gluon。 创建虚拟环境gluon的时候,会自动根据environment.yml文件所配置的软件和版本进行下载安装到当前的虚拟环境gluon中。 若使用国内镜像后出现安装错误,首先取消PyPI镜像配置,即执行命令pip config unset global.index-url。然后重试命令conda env create -f environment.yml。 激活虚拟环境gluon:conda activate gluon # 若conda版本低于4.4,使用命令activate gluon 7.测试 1.MXNet可以指定用来计算和存储的设备。默认情况下,MXNet会将数据创建在内存,然后利用CPU来计算。 2.在MXNet中,mx.cpu()/mx.cpu(任意整数) 都均表示所有的物理CPU和内存。这意味着,MXNet的计算会尽量使用所有的CPU核。mx.cpu()等价于mx.cpu(0)。 比如其中“cpu(0)”⾥的0没有特别的意义,并不代表特定的核。 3.在MXNet中,mx.gpu()/mx.gpu(任意整数) 表示第i块GPU及相应的显存(i从0开始),并且mx.gpu(0)和mx.gpu()等价。 4.MXNet的计算会在输入数据的context属性所指定的cpu/gpu设备上执行。为了使用GPU计算,我们只需要事先将所有的输入数据存储到显存上, 计算输出结果也会自动会保存在显存上。同样的,要计算的所有输入数据都在cpu上的话,那么输出的结果数据也会存储在cpu上。 因此MXNet要求计算的所有输入数据要么都在内存上,或者要么都在显存上。如果要计算的一部分数据在cpu上,一部分在gpu上,是无法计算的。 5.例子 import mxnet as mx from mxnet import nd from mxnet.gluon import nn #cpu(数字):数字并没有特别的意义,并不代表特定的核 #gpu(数字):表示第i块GPU及相应的显存(i从0开始),并且mx.gpu(0)和mx.gpu()等价 mx.cpu(), mx.gpu(), mx.gpu(0) Out[5]: (cpu(0), gpu(0), gpu(0)) mx.cpu(1), mx.gpu(2), mx.gpu(0) Out[6]: (cpu(1), gpu(2), gpu(0)) #在默认情况下,NDArray存在内存上。 x = nd.array([1, 2, 3]) x Out[2]: [1. 2. 3.]
#可以通过NDArray的context属性来查看该NDArray存储在cpu/gpu设备 x.context Out[3]: cpu(0) #可以在创建NDArray的时候通过ctx参数指定存储在cpu/gpu设备 #只能填mx.gpu()和mx.gpu(0),填其他数字会报错CUDA: invalid device ordinal a = nd.array([1, 2, 3], ctx=mx.gpu()) a Out[4]: [1. 2. 3.]
a.context Out[5]: gpu(0) #可以在创建NDArray的时候通过ctx参数指定存储在cpu/gpu设备 #mx.cpu()和mx.cpu(任意数字)都没有特殊意义,并都不代表特定的核 b = nd.array([1, 2, 3], ctx=mx.cpu()) b Out[6]: [1. 2. 3.]
b.context Out[7]: cpu(0) #可以通过copyto(mx.cpu()/mx.gpu())和as_in_context(mx.cpu()/mx.gpu()) 在cpu/gpu两种设备之间传输数据 #NDArray对象x在cpu上,下面通过copyto(mx.gpu())把x从cpu拷贝一份传输到gpu上 y1 = x.copyto(mx.gpu()) y1 Out[36]: [1. 2. 3.]
y1.context Out[37]: gpu(0) #可以通过copyto(mx.cpu()/mx.gpu())和as_in_context(mx.cpu()/mx.gpu()) 在cpu/gpu两种设备之间传输数据 #NDArray对象y1在gpu上,下面通过copyto(mx.cpu())把y1从gpu拷贝一份传输到cpu上 x1 = y1.copyto(mx.cpu()) x1 Out[52]: [1. 2. 3.]
x1.context Out[53]: cpu(0) #可以通过copyto(mx.cpu()/mx.gpu())和as_in_context(mx.cpu()/mx.gpu()) 在cpu/gpu两种设备之间传输数据 #NDArray对象x在cpu上,下面通过as_in_context(mx.gpu())把x从cpu拷贝一份传输到gpu上 y1 = x.as_in_context(mx.gpu()) y1 Out[41]: [1. 2. 3.]
y1.context Out[42]: gpu(0) #可以通过copyto(mx.cpu()/mx.gpu())和as_in_context(mx.cpu()/mx.gpu()) 在cpu/gpu两种设备之间传输数据 #NDArray对象y2在gpu上,下面通过as_in_context(mx.cpu())把y2从gpu拷贝一份传输到cpu上 x2 = y2.as_in_context(mx.cpu()) x2 Out[56]: [1. 2. 3.]
x2.context Out[57]: cpu(0) #如果输入变量和通过as_in_context输出的变量都在同一个cpu或同一个gpu上的话,那么会共享使用同一份内存或显存 #下面输入变量y在gpu上,和通过as_in_context(mx.gpu())输出的变量也同在gpu上,因此共享使用同一份显存 y.as_in_context(mx.gpu()) is y Out[45]: True #如果输入变量和通过copyto输出的变量都在同一个cpu或同一个gpu上的话,那么实际不会共享使用同一份内存或显存,copyto会为输出变量开辟新的内存或显存 #下面输入变量y在gpu上,和通过copyto(mx.gpu())输出的变量也同在gpu上,因此实际不会共享使用同一份显存,copyto会为输出变量开辟新的显存 y.copyto(mx.gpu()) is y Out[47]: False #如果输入变量和通过as_in_context输出的变量都在同一个cpu或同一个gpu上的话,那么会共享使用同一份内存或显存 #下面输入变量x在cpu上,和通过as_in_context(mx.cpu())输出的变量也同在cpu上,因此共享使用同一份内存 x.as_in_context(mx.cpu()) is x Out[45]: True #如果输入变量和通过copyto输出的变量都在同一个cpu或同一个gpu上的话,那么实际不会共享使用同一份内存或显存,copyto会为输出变量开辟新的内存或显存 #下面输入变量x在cpu上,和通过copyto(mx.cpu())输出的变量也同在cpu上,因此实际不会共享使用同一份内存,copyto会为输出变量开辟新的内存 x.copyto(mx.cpu()) is x Out[47]: False
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/209258.html原文链接:https://javaforall.net


