
接下来要分别概述以下内容:
1 首先什么是参数量,什么是计算量
2 如何计算 参数量,如何统计 计算量
3 换算参数量,把他换算成我们常用的单位,比如:mb
4 对于各个经典网络,论述他们是计算量大还是参数量,有什么好处
深度学习中模型参数量和计算量的理解与计算
1 首先什么是计算量,什么是参数量
计算量对应我们之前的时间复杂度,参数量对应于我们之前的空间复杂度,这么说就很明显了
也就是计算量要看网络执行时间的长短,参数量要看占用显存的量
2 如何计算:参数量,计算量
对于卷积层:
参数量就是
(kernel*kernel) *channel_input*channel_output kernel*kernel 就是 weight * weight 其中kernel*kernel = 1个feature的参数量 计算量就是
(kernel*kernel*map*map) *channel_input*channel_output kernel*kernel 就是weight*weight map*map是下个featuremap的大小,也就是上个weight*weight到底做了多少次运算 其中kernel*kernel*map*map= 1个feature的计算量 (2)针对于池化层:
无参数
(3)针对于全连接层:
参数量=计算量=weight_in*weight_out 3 对于换算计算量
- 一般一个参数是值一个float,也就是4个字节
- 1kb=1024字节
4 对于各个经典网络:
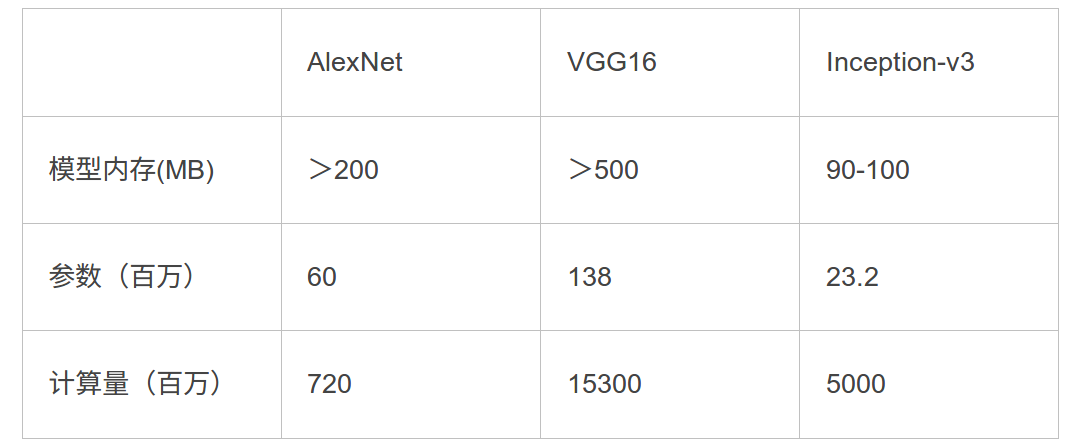

(1)换算
以alexnet为例:
参数量:6000万
设每个参数都是float,也就是一个参数是4字节,
总的字节数是24000万字节
24000万字节= 24000万/1024/1024=228mb
(2)为什么模型之间差距这么大
这个关乎于模型的设计了,其中模型里面最费参数的就是全连接层,这个可以看alex和vgg,
alex,vgg有很多fc(全连接层)
resnet就一个fc
inceptionv1(googlenet)也是就一个fc
(3)计算量
densenet其实这个模型不大,也就是参数量不大,因为就1个fc
但是他的计算量确实很大,因为每一次都把上一个feature加进来,所以计算量真的很大
5 计算量与参数量对于硬件要求
计算量,参数量对于硬件的要求是不同的
计算量的要求是在于芯片的floaps(指的是gpu的运算能力)
参数量取决于显存大小
6 计算量(FLOPs)和参数量(Params)
6.1 第一种方法:thop
第一步:安装模块
pip install thop 第二步:计算
# -- coding: utf-8 -- import torch import torchvision from thop import profile # Model print('==> Building model..') model = torchvision.models.alexnet(pretrained=False) dummy_input = torch.randn(1, 3, 224, 224) flops, params = profile(model, (dummy_input,)) print('flops: ', flops, 'params: ', params) print('flops: %.2f M, params: %.2f M' % (flops / .0, params / .0)) 结果
==> Building model.. [INFO] Register count_convNd() for <class 'torch.nn.modules.conv.Conv2d'>. [INFO] Register zero_ops() for <class 'torch.nn.modules.activation.ReLU'>. [INFO] Register zero_ops() for <class 'torch.nn.modules.pooling.MaxPool2d'>. [WARN] Cannot find rule for <class 'torch.nn.modules.container.Sequential'>. Treat it as zero Macs and zero Params. [INFO] Register count_adap_avgpool() for <class 'torch.nn.modules.pooling.AdaptiveAvgPool2d'>. [INFO] Register zero_ops() for <class 'torch.nn.modules.dropout.Dropout'>. [INFO] Register count_linear() for <class 'torch.nn.modules.linear.Linear'>. [WARN] Cannot find rule for <class 'torchvision.models.alexnet.AlexNet'>. Treat it as zero Macs and zero Params. flops: .0 params: .0 flops: 714.69 M, params: 61.10 M 注意:
- 输入input的第一维度是批量(batch size),批量的大小不回影响参数量, 计算量是batch_size=1的倍数
- profile(net, (inputs,))的 (inputs,)中必须加上逗号,否者会报错
6.2 第二种方法:ptflops
# -- coding: utf-8 -- import torchvision from ptflops import get_model_complexity_info model = torchvision.models.alexnet(pretrained=False) flops, params = get_model_complexity_info(model, (3, 224, 224), as_strings=True, print_per_layer_stat=True) print('flops: ', flops, 'params: ', params) 结果
AlexNet( 61.101 M, 100.000% Params, 0.716 GMac, 100.000% MACs, (features): Sequential( 2.47 M, 4.042% Params, 0.657 GMac, 91.804% MACs, (0): Conv2d(0.023 M, 0.038% Params, 0.07 GMac, 9.848% MACs, 3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.027% MACs, inplace=True) (2): MaxPool2d(0.0 M, 0.000% Params, 0.0 GMac, 0.027% MACs, kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(0.307 M, 0.503% Params, 0.224 GMac, 31.316% MACs, 64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.020% MACs, inplace=True) (5): MaxPool2d(0.0 M, 0.000% Params, 0.0 GMac, 0.020% MACs, kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(0.664 M, 1.087% Params, 0.112 GMac, 15.681% MACs, 192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.009% MACs, inplace=True) (8): Conv2d(0.885 M, 1.448% Params, 0.15 GMac, 20.902% MACs, 384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.006% MACs, inplace=True) (10): Conv2d(0.59 M, 0.966% Params, 0.1 GMac, 13.936% MACs, 256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.006% MACs, inplace=True) (12): MaxPool2d(0.0 M, 0.000% Params, 0.0 GMac, 0.006% MACs, kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(0.0 M, 0.000% Params, 0.0 GMac, 0.001% MACs, output_size=(6, 6)) (classifier): Sequential( 58.631 M, 95.958% Params, 0.059 GMac, 8.195% MACs, (0): Dropout(0.0 M, 0.000% Params, 0.0 GMac, 0.000% MACs, p=0.5, inplace=False) (1): Linear(37.753 M, 61.788% Params, 0.038 GMac, 5.276% MACs, in_features=9216, out_features=4096, bias=True) (2): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.001% MACs, inplace=True) (3): Dropout(0.0 M, 0.000% Params, 0.0 GMac, 0.000% MACs, p=0.5, inplace=False) (4): Linear(16.781 M, 27.465% Params, 0.017 GMac, 2.345% MACs, in_features=4096, out_features=4096, bias=True) (5): ReLU(0.0 M, 0.000% Params, 0.0 GMac, 0.001% MACs, inplace=True) (6): Linear(4.097 M, 6.705% Params, 0.004 GMac, 0.573% MACs, in_features=4096, out_features=1000, bias=True) ) ) flops: 0.72 GMac params: 61.1 M 6.3 第三种方法:pytorch_model_summary
import torch import torchvision from pytorch_model_summary import summary # Model print('==> Building model..') model = torchvision.models.alexnet(pretrained=False) dummy_input = torch.randn(1, 3, 224, 224) print(summary(model, dummy_input, show_input=False, show_hierarchical=False)) 结果
==> Building model.. ----------------------------------------------------------------------------- Layer (type) Output Shape Param # Tr. Param # ============================================================================= Conv2d-1 [1, 64, 55, 55] 23,296 23,296 ReLU-2 [1, 64, 55, 55] 0 0 MaxPool2d-3 [1, 64, 27, 27] 0 0 Conv2d-4 [1, 192, 27, 27] 307,392 307,392 ReLU-5 [1, 192, 27, 27] 0 0 MaxPool2d-6 [1, 192, 13, 13] 0 0 Conv2d-7 [1, 384, 13, 13] 663,936 663,936 ReLU-8 [1, 384, 13, 13] 0 0 Conv2d-9 [1, 256, 13, 13] 884,992 884,992 ReLU-10 [1, 256, 13, 13] 0 0 Conv2d-11 [1, 256, 13, 13] 590,080 590,080 ReLU-12 [1, 256, 13, 13] 0 0 MaxPool2d-13 [1, 256, 6, 6] 0 0 AdaptiveAvgPool2d-14 [1, 256, 6, 6] 0 0 Dropout-15 [1, 9216] 0 0 Linear-16 [1, 4096] 37,752,832 37,752,832 ReLU-17 [1, 4096] 0 0 Dropout-18 [1, 4096] 0 0 Linear-19 [1, 4096] 16,781,312 16,781,312 ReLU-20 [1, 4096] 0 0 Linear-21 [1, 1000] 4,097,000 4,097,000 ============================================================================= Total params: 61,100,840 Trainable params: 61,100,840 Non-trainable params: 0 ----------------------------------------------------------------------------- 6.4 第四种方法:参数总量和可训练参数总量
import torch import torchvision from pytorch_model_summary import summary # Model print('==> Building model..') model = torchvision.models.alexnet(pretrained=False) pytorch_total_params = sum(p.numel() for p in model.parameters()) trainable_pytorch_total_params = sum(p.numel() for p in model.parameters() if p.requires_grad) print('Total - ', pytorch_total_params) print('Trainable - ', trainable_pytorch_total_params) 结果
==> Building model.. Total - Trainable - 7 输入数据对模型的参数量和计算量的影响
# -- coding: utf-8 -- import torch import torchvision from thop import profile # Model print('==> Building model..') model = torchvision.models.alexnet(pretrained=False) dummy_input = torch.randn(1, 3, 224, 224) flops, params = profile(model, (dummy_input,)) print('flops: ', flops, 'params: ', params) print('flops: %.2f M, params: %.2f M' % (flops / .0, params / .0)) - 输入数据:(1, 3, 224, 224),一张224*224的RGB图像
flops: .0 params: .0 flops: 714.69 M, params: 61.10 M - 输入数据:(1, 3, 512, 512),一张512*512的RGB图像
flops: .0 params: .0 flops: 3710.03 M params: 61.10 M - 输入数据:(8, 3, 224, 224),八张224*224的RGB图像
flops: .0 params: .0 flops: 5717.54 M params: 61.10 M | 输入数据 | 计算量(flops) | 参数量(params) |
|---|---|---|
| (1, 3, 224, 224) | 714.69 M | 61.10 M |
| (1, 3, 512, 512) | 3710.03 M | 61.10 M |
| (8, 3, 224, 224) | 5717.54 M | 61.10 M |
参考资料
- https://www.cnblogs.com/lllcccddd/p/10671879.html
- https://blog.csdn.net/Caesar6666/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/209710.html原文链接:https://javaforall.net


