
在NLP任务中,我们通常会遇到不定长的语言序列,比如机器翻译任务中,输入可能是一段不定长的英文文本,输出可能是不定长的中文或者法语序列。当遇到输入和输出都是不定长的序列时,可以使用编码器-解码器(encoder-decoder)模型或者seq2seq模型。其基本思想是编码器用来分析输入序列,解码器用来生成输出序列。
首先,来简单介绍下RNN(循环神经网络)结构:
1. RNN 结构


RNN结构
RNN中,每个单元接受两个输入,一个是当前时间步输入的信息 X t X_t Xt,另一个是上一个单元的隐藏层状态 H t − 1 H_{t-1} Ht−1。为什么这种结构的RNN适合用于做文本等序列型数据的任务,主要是因为隐藏状态的存在使得模型具有记忆性。针对不同的任务,根据输入和输出的数量,通常对RNN结构进行调整。
- N to N
该模型处理的一般是输入和输出序列长度相等的任务,如- 词性标注
- 语言模型(Language Modeling)
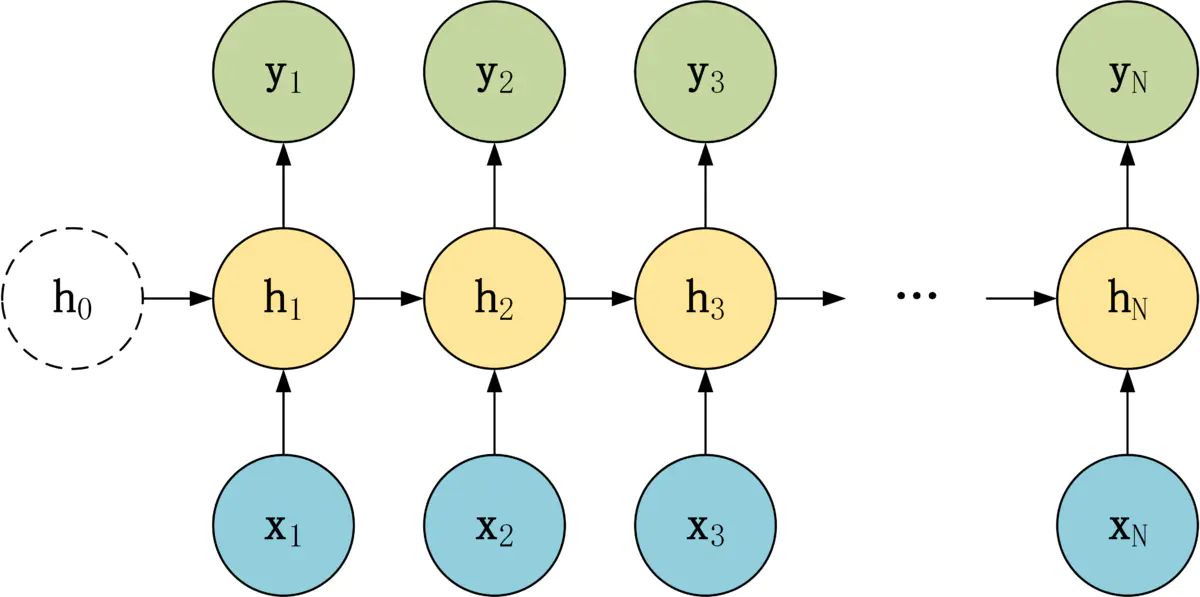
- 1 to N
此类结构的输入长度为1,输出长度为N,一般又可以分为两种:一种是将输入只输入到第一个神经元,另一种将输入输入到所有神经元。一般用于以下任务:
- 图像生成文字,一般输入 X 为图片,输出为一段图片描述性的文字;
- 输入音乐类别,生成对应的音乐
- 根据小说(新闻情感)类别,生成对应的文字

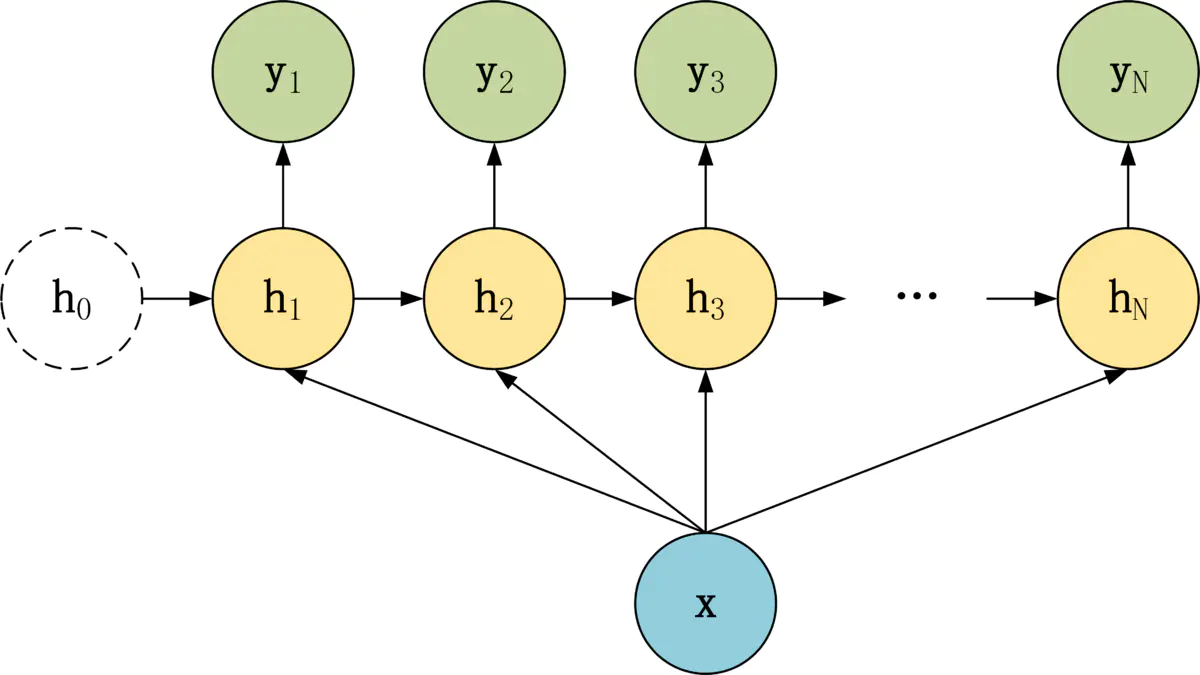
- N to 1
和1 to N相反,一般常见任务有:- 序列分类任务,如给定一段文本或语音序列,归类(情感分类,主题分类等)
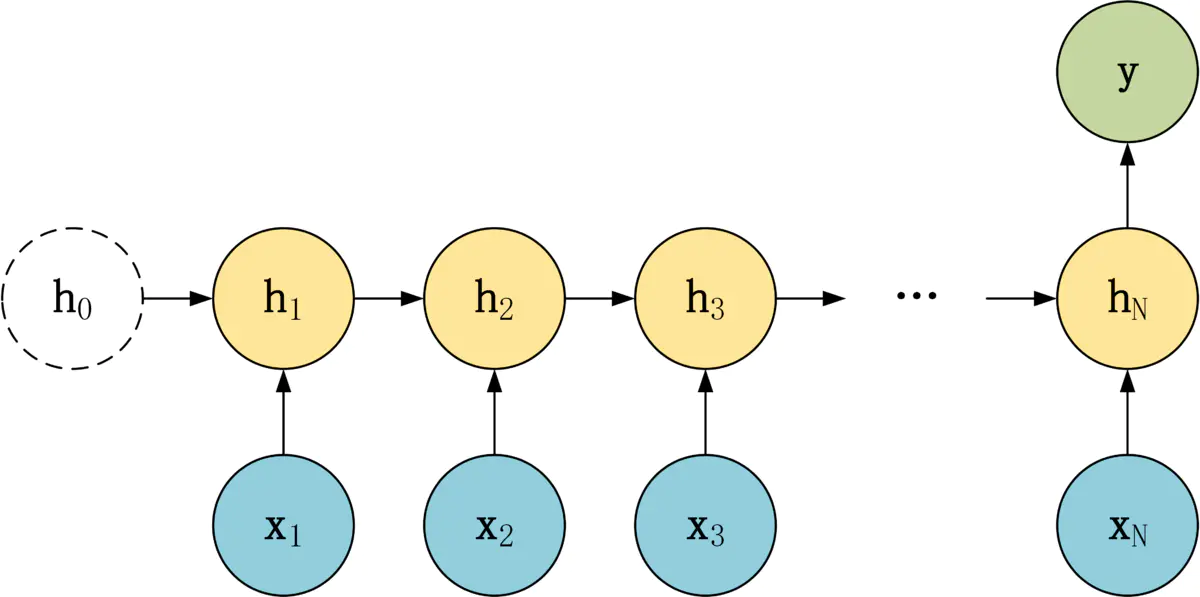
- 序列分类任务,如给定一段文本或语音序列,归类(情感分类,主题分类等)
2. Seq2Seq 模型
经过上面对几种RNN结构的分析,不难发现RNN结构大多对序列的长度比较局限,对于类似于机器翻译的任务,输入和输出长度并不对等,为N to M的结构,简单的RNN束手无策,因此便有了新的模型,Encoder-Decoder模型,也就是Seq2Seq模型。
模型一般由两部分组成:第一部分是Encoder部分,用于对输入的N长度的序列进行表征;第二部分是Decoder部分,用于将Encoder提取出的表征建立起到输出的M长度序列的映射。
1. 编码器 Decoder
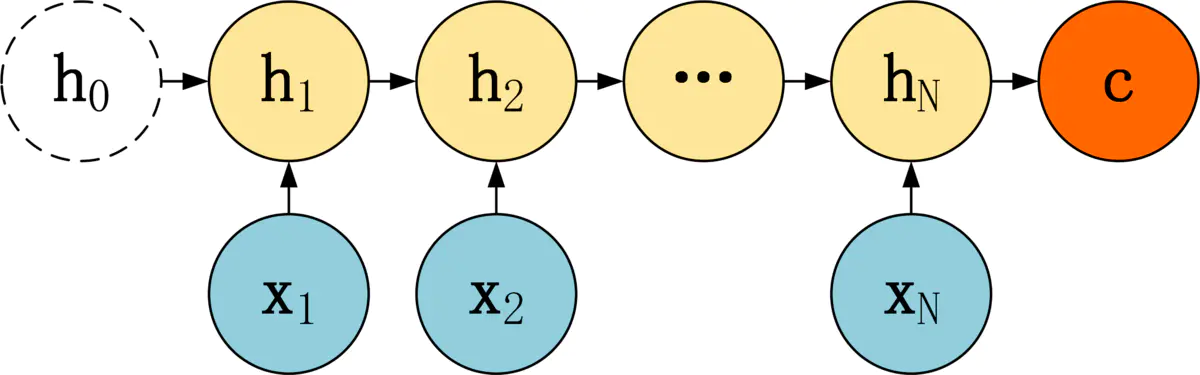
Encoder部分一般使用了普通RNN的结构。其将一个序列表征为一个定长的上下文向量c,计算方式有多种,如下:
- c = h N c=h_N c=hN
- c = f ( h N ) c=f(h_N) c=f(hN)
- c = f ( h 1 , h 2 , ⋯ , h N ) c=f(h_1, h_2, \cdots, h_N) c=f(h1,h2,⋯,hN)
2. 解码器 Decoder
相对于编码器而言,解码器的结构更多,下面介绍三种:
第一种
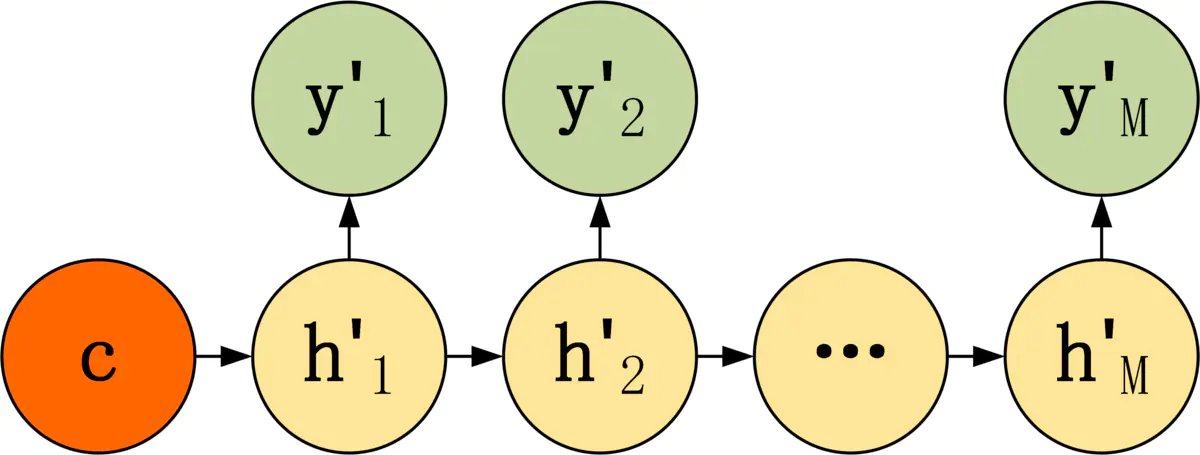
这种结构直接将Decoder得到的上下文向量作为RNN的初始隐藏状态输入到RNN结构中,后续单元不接受 c 的输入,计算公式如下:
- 隐藏状态的更新:
h 1 ′ = σ ( W c + b 1 ) h t ′ = σ ( W h t − 1 ′ + b 1 ) \mathbf {h’_1}=\sigma(\mathbf {Wc+b_1})\\ \mathbf {h’_t}=\sigma (\mathbf{Wh’_{t-1}+b_1}) h1′=σ(Wc+b1)ht′=σ(Wht−1′+b1) - 输出的计算: y t ′ = σ ( V h t ′ + b 2 ) \mathbf{y’_{t}} = \sigma(\mathbf{Vh’_t+b_2}) yt′=σ(Vht′+b2)
第二种

第二种将Encoder得到的上下文向量作为每个神经单元的输入,不再是只作为第一个单元的初始隐藏状态。计算公式如下:
- 隐藏状态: h t ′ = σ ( U c + W h t − 1 ′ + b 1 ) \mathbf {h’_t}=\sigma(\mathbf{Uc+Wh’_{t-1}+b_1}) ht′=σ(Uc+Wht−1′+b1)
- 输出: y t ′ = σ ( V h ′ t + b 2 ) \mathbf{y’_{t}} =\sigma(\mathbf{Vh’t+b_2}) yt′=σ(Vh′t+b2)
第三种
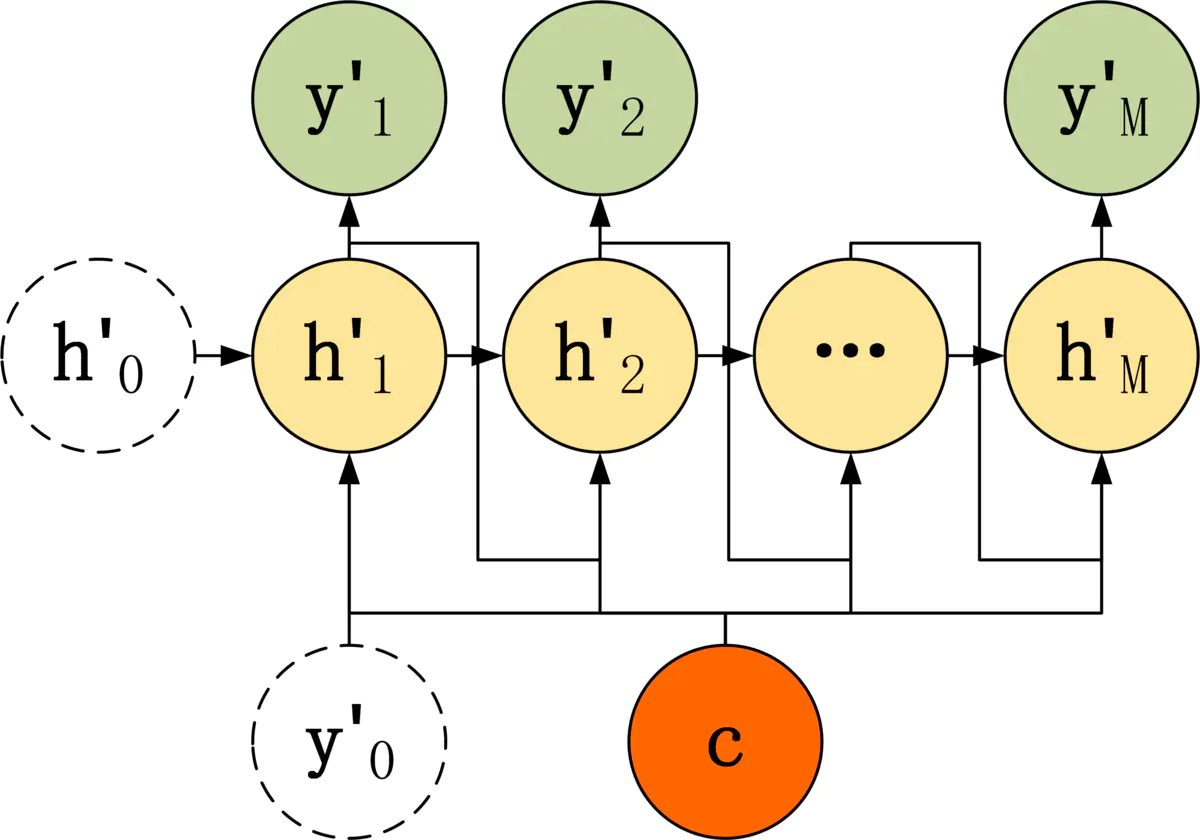
第三种在 c 的处理上和第二种类似,但是区别在于将前一个神经单元的输出作为当前神经单元的输出。计算公式如下:
- 隐藏状态: h t ′ = σ ( U c + W h t − 1 ′ + V y t − 1 ′ + b 1 ) \mathbf{h’_t}=\sigma(\mathbf{Uc+Wh’_{t-1}+Vy’_{t-1}+b_1}) ht′=σ(Uc+Wht−1′+Vyt−1′+b1)
- 输出: y t ′ = σ ( V h t ′ + b 2 ) \mathbf{y’_{t}} =\sigma(\mathbf{Vh’_t+b_2}) yt′=σ(Vht′+b2)
3. Seq2Seq中的Trick
1. Teacher Forcing
2. Attention 机制(很重要)
提出Attention机制之前,我们先来看下之前的结构有什么问题:
核心问题是当序列过长时,上述的Decoder输出的上下文向量 c 无法记住所有信息,会出现长序列梯度消失的问题。比如句子有100个词,那么c里面可能丢失了前几个词的信息。
Attention 机制是怎样的?
- 首先计算上一个神经元隐藏状态 h t − 1 h_{t-1} ht−1与Encoder每一个神经元隐藏状态的相似度,用 e t e_t et表示。 e t = [ a ( h t − 1 ′ , h 1 ) , ⋯ , a ( h t − 1 ′ , h N ) ] e_t=[a(h’_{t-1}, h_1), \cdots, a(h’_{t-1},h_N)] et=[a(ht−1′,h1),⋯,a(ht−1′,hN)],其中 a ( ⋅ ) a(\cdot) a(⋅)为某种相似度计算函数。
- “集中注意力”。对以上 e t e_t et使用softmax函数,得到Encoder每个隐藏状态在处理第 t 个词的时候的“注意力” α t \alpha_{t} αt。计算得到各个上下文向量: c t = ∑ i = 1 N α t i h i c_t=\sum_{i=1}^N\alpha_{ti}h_i ct=∑i=1Nαtihi
- 后面Decoder对 y 的计算与上面提到的第三种Decoder的计算方式几乎一致,区别就在于上下文向量 c 的变化。
3. 束搜索(Beam Search)
注意:Beam Search只用于测试,不用于训练过程。
当模型训练好后,给其输入一段话,其输出的每个单元的 y 给的是各个词的概率,我们如何根据概率选词且如何判断是否句子终止呢?
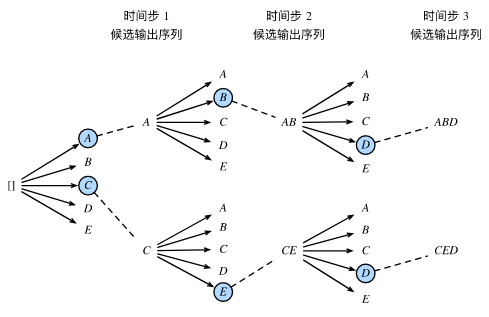
采取的方法是在每个时间步,选取当前时间步条件概率最大的k个词,作为该时间步的候选输出序列。如下图,k选择2,第一步p(A|c)和p(C|c)最大;第二步 P(AB|c),P(CE|c)最大;第三步P(ABD|c),P(CED|c)最大。
其中L为候选序列的长度, α \alpha α 一般选0.75. 这样一来,序列长的对应的系数更小,而由于取了对数,概率的对数是负数,如此变化后会使得长序列和短序列处于一个可比的情形。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/212129.html原文链接:https://javaforall.net


