
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章目录
0. 如何离线安装NLTK
- 使用pip安装NLTK,代码如下所示(需要注意的是这只是第一步):
pip install nltk
- 得到NLTK的存储目录,代码和截图如下所示:
import nltk
print(nltk.data.path)


- 下载nltk_data压缩包,链接为https://download.csdn.net/download/herosunly/15683254,并将其解压到上述存储目录中的一个,如/home/anaconda3/nltk_data,则将nltk_data压缩包移动到/home/anaconda3路径(即上述某个路径的上一级路径)下,使用unzip命令进行解压,命令如下图所示:
unzip nltk_data.zip
1. LookupError: Resource not found.
例如在运行下列代码时出现错误:
from nltk.tokenize import word_tokenize
tokenized_word = word_tokenize('I am a good boy')
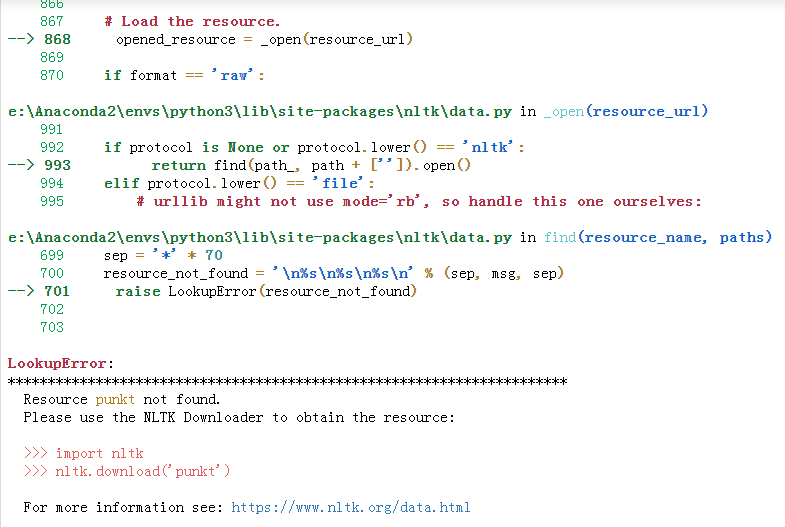

- 解决方法一:
import nltk
nltk.download('punkt')
但可能会出现远程主机强迫关闭了一个现有的连接的错误,此时我们就需要使用其他办法。
- 解决方法二:
请参考上文0. 如何离线安装NLTK的内容。
2. 分句、分词和停用词
- 分句
from nltk import sent_tokenize
sents = sent_tokenize('ZhangSan is a boy. And LiSi is a girl')
print(sents)
需要注意的是,只能对句号后有空格的句子进行分割。
- 分词
from nltk import word_tokenize
tokenized_word = word_tokenize('I love a good boy')
print(tokenized_word)
可以分句之后再进行分词。
- 停用词
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
3. 词性标注和词形还原
词形还原与词干提取类似, 但不同之处在于词干提取经常可能创造出不存在的词汇,词形还原的结果是一个真正的词汇。所以我们这里只介绍词形还原。但是词性还原又取决于词性,所以我们需要借助词性标注得到的结果。
3.1 词性标注
import nltk
text = nltk.word_tokenize('what does the fox say')
print(text)
print(nltk.pos_tag(text))
结果为:
['what', 'does', 'the', 'fox', 'say']
输出是元组列表,元组中的第一个元素是单词,第二个元素是词性标签
[('what', 'WDT'), ('does', 'VBZ'), ('the', 'DT'), ('fox', 'NNS'), ('say', 'VBP')]
|
Number
|
Tag
|
Description
|
| 1. | CC | Coordinating conjunction |
| 2. | CD | Cardinal number |
| 3. | DT | Determiner |
| 4. | EX | Existential there |
| 5. | FW | Foreign word |
| 6. | IN | Preposition or subordinating conjunction |
| 7. | JJ | Adjective |
| 8. | JJR | Adjective, comparative |
| 9. | JJS | Adjective, superlative |
| 10. | LS | List item marker |
| 11. | MD | Modal |
| 12. | NN | Noun, singular or mass |
| 13. | NNS | Noun, plural |
| 14. | NNP | Proper noun, singular |
| 15. | NNPS | Proper noun, plural |
| 16. | PDT | Predeterminer |
| 17. | POS | Possessive ending |
| 18. | PRP | Personal pronoun |
| 19. | PRP$ | Possessive pronoun |
| 20. | RB | Adverb |
| 21. | RBR | Adverb, comparative |
| 22. | RBS | Adverb, superlative |
| 23. | RP | Particle |
| 24. | SYM | Symbol |
| 25. | TO | to |
| 26. | UH | Interjection |
| 27. | VB | Verb, base form |
| 28. | VBD | Verb, past tense |
| 29. | VBG | Verb, gerund or present participle |
| 30. | VBN | Verb, past participle |
| 31. | VBP | Verb, non-3rd person singular present |
| 32. | VBZ | Verb, 3rd person singular present |
| 33. | WDT | Wh-determiner |
| 34. | WP | Wh-pronoun |
| 35. | WP$ | Possessive wh-pronoun |
| 36. | WRB | Wh-adverb |
3.2 词性还原(Lemmatize)
# { Part-of-speech constants
ADJ, ADJ_SAT, ADV, NOUN, VERB = "a", "s", "r", "n", "v"
# }
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos="v"))
print(lemmatizer.lemmatize('playing', pos="n"))
print(lemmatizer.lemmatize('playing', pos="a"))
print(lemmatizer.lemmatize('playing', pos="r"))
''' 结果为: play playing playing playing '''
4. 分句
由于word2vec本质上是对每个句子求词向量,所以我们需要对文章划分成句子。
from nltk.tokenize import sent_tokenize
text="""Hello Mr. Smith, how are you doing today? The weather is great, and city is awesome. The sky is pinkish-blue. You shouldn't eat cardboard"""
tokenized_text = sent_tokenize(text)
print(tokenized_text)
5. N-gram
nltk.ngrams(
sequence,
n,
pad_left=False,
pad_right=False,
left_pad_symbol=None,
right_pad_symbol=None,
)
如果是字符串想得到N-gram字符串,只需使用map函数即可,具体代码如下:
ngram = nltk.ngrams(s, n) // s is string, n is gram
ngram = map(''.join, ngram)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/213509.html原文链接:https://javaforall.net


