
马尔可夫决策过程:马尔科夫链+奖励+决策(动作)
由上面的定义式知,马尔可夫决策也等于马尔可夫奖励+决策。所以决策和奖励二者之间存在这样的转化关系:

一个明显的问题就是:马尔可夫决策过程和马尔可夫过程/奖励过程有什么区别呢?区别就是决策的存在,体现为是否有具体动作的选择。用图来说明这个问题:
注:上面右边这个图其实叫备份图,备份类似于自举之间的迭代关系,对某一个状态当前的价值和未来价值线性相关。对于备份有两种分类 同步备份:每一次迭代都会完全更新所有的状态。异步备份:通过某种方式,每一次迭代不需要更新所有的状态。
策略迭代流程:
策略迭代的目的是寻找最优策略,方法是不断更新策略。更新策略的方法是不断选择状态价值最高的策略。让状态价值变高的方法是选择正确的状态。这是反向过程,首先根据状态计算状态的价值,让价值收敛就是选择出具有最高价值的状态/确定了新策略的评估函数。利用评估函数,确定每一个状态选择每一个动作的价值。选择价值最高的动作,将这个动作作为策略。这个策略比之前的有所改进。
价值迭代流程:
价值迭代的目的是寻找最优策略和最大价值函数。进行价值函数更新时就直接选择最好的。策略迭代中利用的是收敛即可,这里是要尝试所有状态的所有动作,选择其中最大的价值。并将这个期望价值函数作为当前状态的价值函数,然后收敛就行。利用最有价值函数和状态转移概率计算出最优动作,这就是最优策略
参考:策略迭代与值迭代的区别_dadadaplz的博客-CSDN博客_值迭代和策略迭代区别
老规矩,课后题来!

2-1 折扣因子有三个作用:1)防止无穷奖励 2)倾向与当前奖励 3)表达不确定性
2-2 解析解求解的时候计算了矩阵的逆,矩阵的维度是状态数,状态数过多时,求解时间复杂度很高
2-3 贝尔曼方程的推导写了一遍,我觉得我掌握一种就够了(狗头保命)
2-4 决策过程比奖励过程多了一个决策的动作层
2-5 马尔可夫奖励比马尔可夫过程结构上多了每次状态转移的奖励
2-6 价值迭代和策略迭代,策略迭代只寻找最优策略,价值迭代寻找最优策略及最优价值函数

2-1 马尔可夫过程指状态转移过程,而且下一时刻状态只取决于当前状态,与当前状态前面的状态无关。马尔可夫决策过程指马尔可夫奖励过程+策略选择。 最重要的性质只有相邻状态间存在相关性
2-2 策略迭代和价值迭代
2-3 ?????
2-4
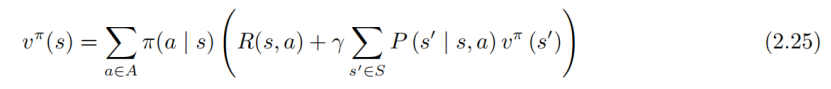

2-5 都是最优情况下,按照最优的唯一性,最佳价值函数和最优策略对应的应该是相同情况
2-6 当n越来越大时,方差应该是变大的。这点类比于MC和TD的关系,MC相当于n趋近于无穷,MC的方差更大。类似MC的期望更小,n越大,期望也会越小
学完MDP这一章,我们明确了要寻找最佳策略,给了策略迭代和价值迭代的方法。本文介绍了思想,但是它们具体是怎么实现的呢?且听下回分说。
因作者水平有限,如果错误之处,请在下方评论区指正,谢谢!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/213903.html原文链接:https://javaforall.net


