
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
问题:
在进行画出指数平滑移动平均线,遇到如下问题:
# pd.ewma(com=None, span=one) # 指数平均线。com:数据;span:时间间隔
AttributeError: module 'pandas' has no attribute 'ewma'
解决办法:
方法一:
换用下面的方法
# Series.ewm(com=None, span=None, halflife=None, alpha=None, min_periods=0, freq=None, adjust=True, ignore_na=False, axis=0)
# com : float, optional
# Specify decay in terms of center of mass, \(\alpha = 1 / (1 + com),\text{ for } com \geq 0\)
# span : float, optional
# Specify decay in terms of span, \(\alpha = 2 / (span + 1),\text{ for } span \geq 1\)
# halflife : float, optional
# Specify decay in terms of half-life, \(\alpha = 1 - exp(log(0.5) / halflife),\text{ for } halflife > 0\)
# alpha : float, optional
# Specify smoothing factor \(\alpha\) directly, \(0 < \alpha \leq 1\)
# New in version 0.18.0.
# min_periods : int, default 0
# Minimum number of observations in window required to have a value (otherwise result is NA).
# freq : None or string alias / date offset object, default=None (DEPRECATED)
# Frequency to conform to before computing statistic
# adjust : boolean, default True
# Divide by decaying adjustment factor in beginning periods to account for imbalance in relative weightings (viewing EWMA as a moving average)
# ignore_na : boolean, default False
# Ignore missing values when calculating weights; specify True to reproduce pre-0.15.0 behavior
stock_day["close"].ewm(span=30).mean().plot()
方法二:
在pandas 0.23.4版本中,已经不存在这种方法,回退到之前版本pandas 0.21.0就一切完美
pip install pandas==0.21
实例:
# 简单移动平均线(SMA),又称“算数移动平均线”,是指特定期间的收盘价进行平均化
# 例:5日的均线 SMA=(C1+ C2 + C3 + C4 + C5) / 5 # Cn为数据中第n天的数
# 计算移动平均线,对每天的股票的收盘价进行计算 close指标
# pd.rolling_mean(data, window=5) # 这种方法已经淘汰了
data.rolling(window=n).mean().plot() # window=n n日的平均数
# 加权移动平均线(WMA):为了提高最近股票(收盘价)数据的影响,防止被平均
# 1) 末日加权移动平均线:
MA(N) = (C1+ C2 + C3 + C4 + ... + Cn *2) / (n+1)
# 2) 线性加权移动平均线(给的权重比例太大,导致最近的时间序列数据影响过大,一般不选择):
MA(N) = (C1+ C2 * 2 + C3 * 3 + C4 * 4 + ... + Cn * n) / (1 + 2 + ... + n)
# 3) 指数平滑移动平均线(EWMA):
# 提高最近的数据的比重,不存在给的过大;
# 比重都是小数,所有天书的比重加起来等于1
y=[2 * x + (N - 1) * y' ]/ (N + 1) # x:当天的价格;N:第几天;y':上一次的EWMA结果
# pd.ewma(com=None, span=one) # 指数平均线。com:数据;span:时间间隔
# 股票时间序列数据处理
stock_day = pd.read_csv("./data/stock_day/stock_day.csv")
stock_day.sort_index()
stock_day["index"] = [i for i in range(stock_day.shape[0])]
val = stock_day[["index", "open", "close", "high", "low"]].values
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(20,8), dpi=80)
# K线图
candlestick_ochl(axes, val, width=0.2, colorup="r", colordown="g")
# 计算简单移动平均线,对每天的股票的收盘价进行计算 close指标
# pd.rolling_mean(stock_day["close"], window=5) # 这种方法在pandas 0.23.4 已经淘汰了
# stock_day["close"].rolling(window=5).mean().plot()
# stock_day["close"].rolling(window=10).mean().plot()
# stock_day["close"].rolling(window=30).mean().plot()
# stock_day["close"].rolling(window=60).mean().plot()
# stock_day["close"].rolling(window=120).mean().plot()
# 画出指数平滑移动平均线
# 方法一:
stock_day["close"].ewm(span=10).mean().plot()
# 方法二:pandas 0.21.0及以下版本的使用方法
# pd.ewma(stock_day["close"], span=10).plot()
plt.show()
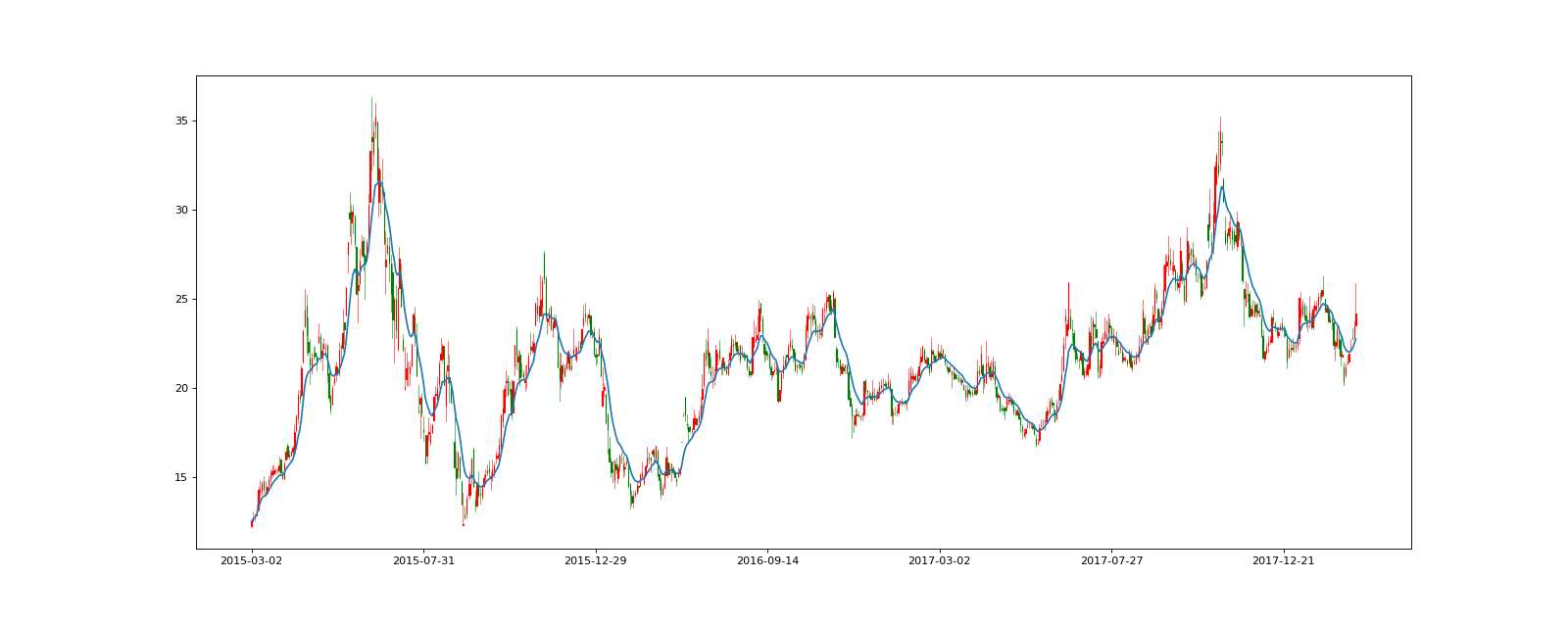

具体在pandas 0.23.4版本中还在继续查找其方法!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/215895.html原文链接:https://javaforall.net


