
DynamoDB是Amazon的一个高可用的键-值存储系统。用以提供一个“永远在线”可用存储。为了达到这个级别的可用性,DynamoDB在某些故障场景中将牺牲一致性。它大量使用对象版本和应用程序协助的冲突协调方式以提供一个开发人员可以使用的新颖的接口。
在一个分布式的存储系统中,除了数据持久化组件,系统还需要有以下的考虑:
- 负载均衡
- 成员(membership)和故障检测
- 故障恢复
- 副本同步
- 过载处理
- 状态转移
- 并发性和工作调度
- 请求marshaling
- 请求路由
- 系统监控报警
- 配置管理
- 。。。。。
描述解决方案的每一个细节不太可能,所以本文重点是核心技术在分布式系统DynamoDB中的使用:
- 划分(partitioning)
- 复制(replication)
- 版本(versioning)
- 会员(membership)
- 故障处理(failure handling)
- 伸缩性(scaling)
以下是DynamoDB使用的技术概要和优势:
| 问题 | 技术 | 优势 |
| 划分(partitioning) | 一致性哈希 | 增量可伸缩性 |
| 写的高可用性 | 矢量时钟与读取过程中的协调(reconciliation) | 版本大小与更新操作速率脱钩 |
| 暂时性的失败处理 | 草率仲裁(Sloppy Quorum)并暗示移交(hinted handoff) | 提供高可用性和耐用性的保证,即使一些副本不可用时。 |
| 永久故障恢复 | 使用Merkle树的反熵(Anti-entropy) | 在后台同步不同的副本 |
| 会员和故障检测 | Gossip的成员和故障检测协议 | 保持对称性并且避免了一个用于存储会员和节点活性信息的集中注册服务节点 |
划分算法(Partitioning)
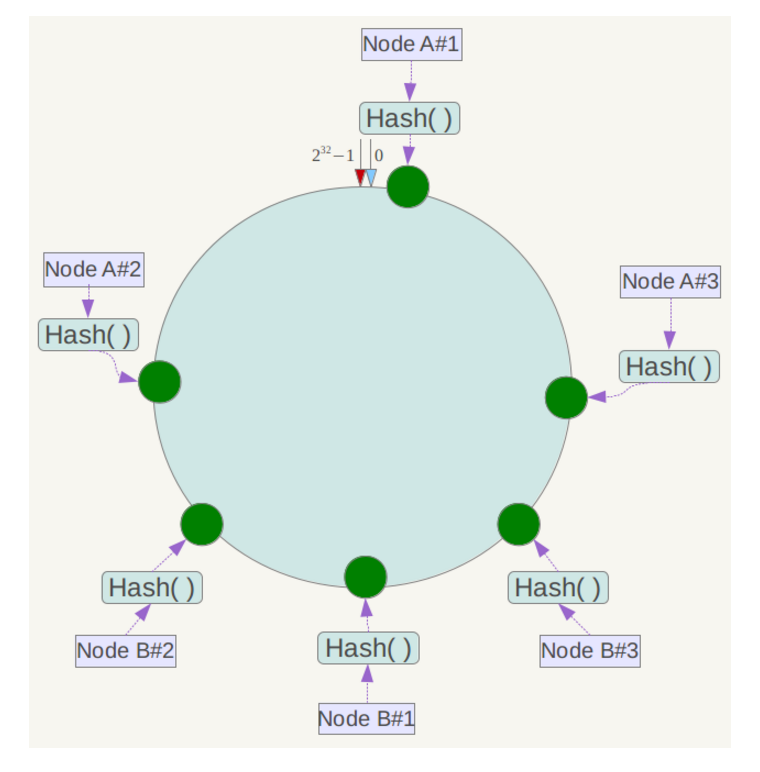
DynamoDB的关键设计要求之一是必须增量可扩展性。这就需要一个机制,用来将数据动态划分到系统中的节点(即存储主机)上去。DynamoDB的分区方案依赖于 一致性哈希 将负载分发到多个存储主机。DynamoDB采用了一致性哈希的变体:每个节点被分配到环多点而不是映射到环上的一个单点。
一致性Hash算法满足以下几个方面:
- 平衡性(Balance):即数据尽可能的平均分布到系统中的节点上。
- 单调性(Monotonicity):指如果已经有一些数据通过哈希分派到了相应的节点上,又有新的节点加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的节点中去,而不会被映射到旧的节点集合中的其他节点。
- 分散性(Spread):在分布式环境中,终端有可能看不到所有的节点,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到节点上时,由于不同终端所见的节点范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的节点上。这种情况显然是应该避免的,因为它导致相同内容被存储到不同节点中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
- 负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
- 平滑性(Smoothness):平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
一致性Hash的基本原理:

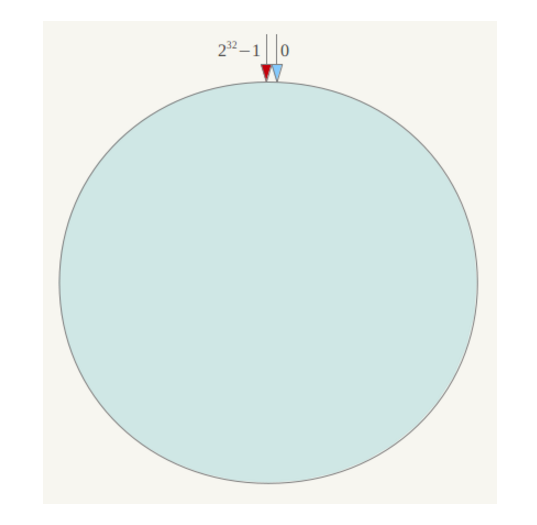
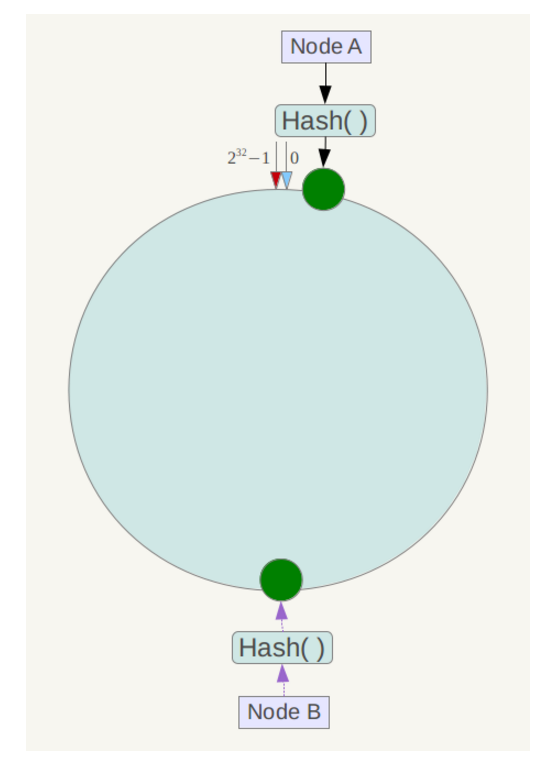
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
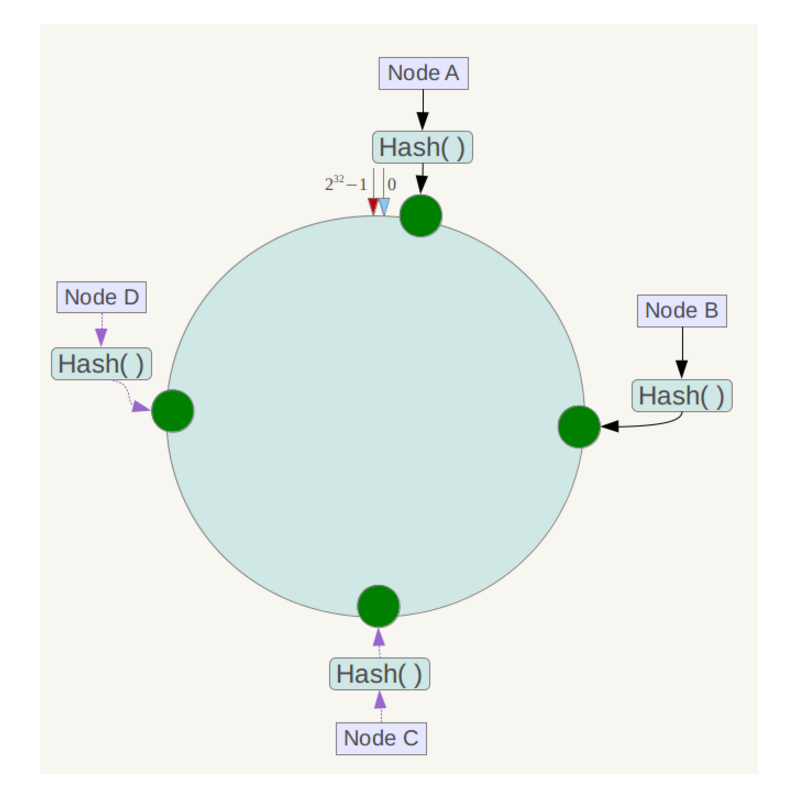
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
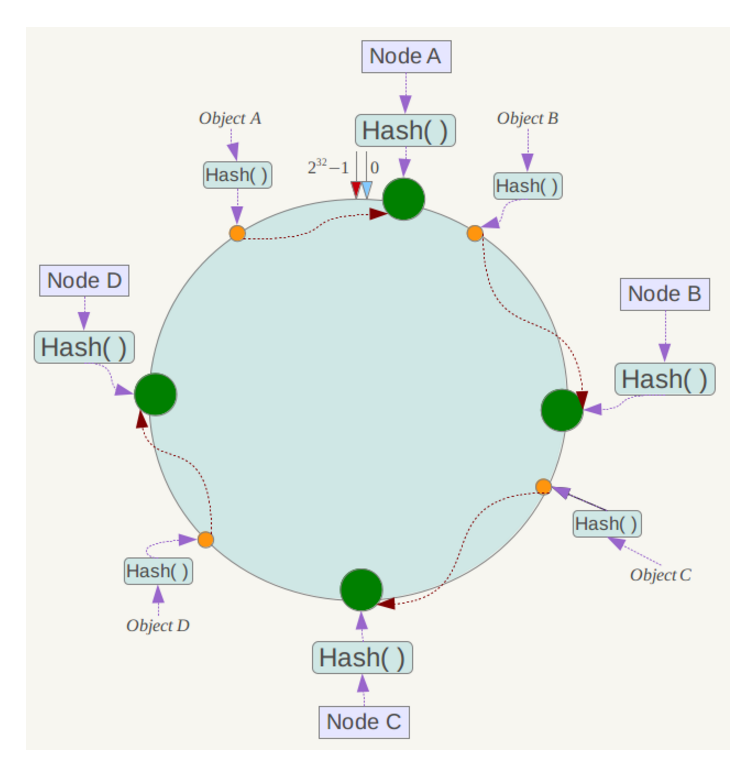
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
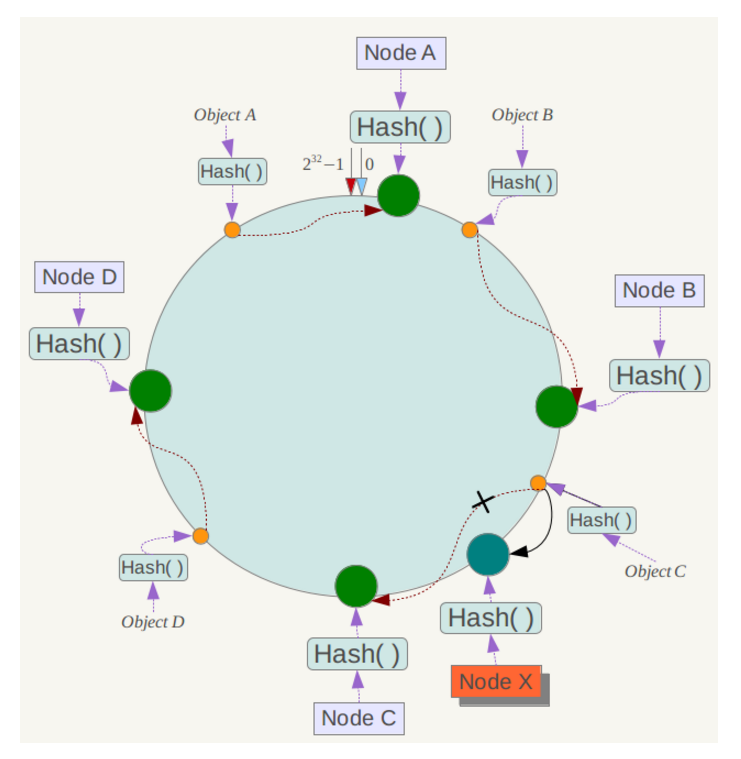
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下,
写的高可用性:复制(replication)
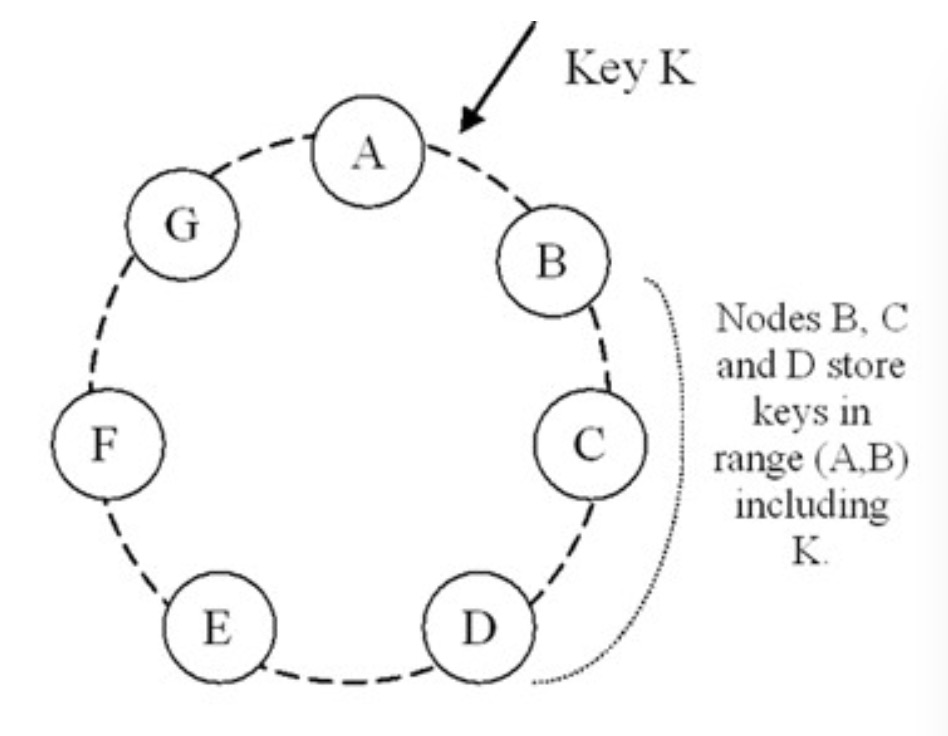
为了实现高可用性和耐用性,DynamoDB将数据复制到多台主机上。每个数据项被复制到N台主机。其中N是每实例(per-instance)的配置参数。每个键,K,被分配到一个协调器(coordinator)节点。协调器节点掌控其负责范围内的复制数据项。除了在本地存储范围内的每个Key外,协调器节点复制这些Key到环上顺时针方向的N-1后继节点。这样的结果是,系统中每个节点负责环上的从其自己到第 N 个前继节点间的一段区域。在下图中,节点 B 除了在本地存 储键 K 外,在节点 C 和 D 处复制键 K。节点 D 将存储落在范围(A,B],(B,C]和(C,D]上的所有键。
写的高可用性:版本化数据
DynamoDB提供最终一致性,从而允许更新操作可以异步的传播到所有的副本。put()调用可能在更新操作被所有的副本执行之前就 返回给调用者,这可能会导致一个场景:在随后的 get()操作可能会返回一个不是最新的对象。如果没有失败,那么更新操作的 传播时间将有一个上限。但是,在某些故障情况下(如服务器故障或网络 partitions),更新操作可能在一个较长时间内无法到达 所有的副本。
DynamoDB 使用矢量时钟来捕捉同一不同版本的对象的因果关系。矢量时钟实际上是一个(node,counter)对列表(即(节点, 计数器)列表)。矢量时钟是与每个对象的每个版本相关联。通过审查其向量时钟,我们可以判断一个对象的两个版本是平 行 分 枝 或 有 因 果 顺 序 。如果第一个时钟对象上的计数器在第二个时钟对象上小于或等于其他所有节点的计数器,那么第一个是 第二个的祖先,可以被人忽略。否则,这两个变化被认为是冲突,并要求协调。
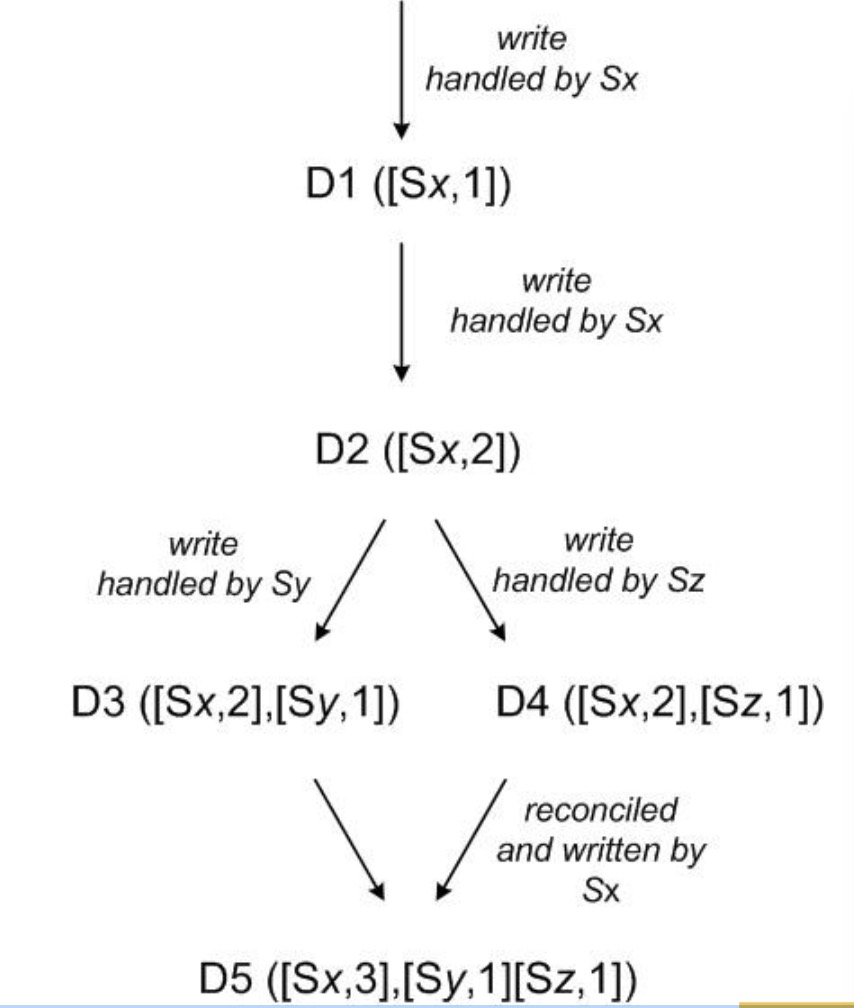
关于向量时钟一个可能的问题是,如果许多服务器协调对一个对象的写,向量时钟的大小可能会增长。实际上,这是不太可能 的,因为写入通常是由首选列表中的前 N 个节点中的一个节点处理。在网络分裂或多个服务器故障时,写请求可能会被不是首 选列表中的前 N 个节点中的一个处理的,因此会导致矢量时钟的大小增长。在这种情况下,值得限制向量时钟的大小。为此, Dynamo 采用了以下时钟截断方案:伴随着每个(节点,计数器)对,Dynamo 存储一个时间戳表示最后一次更新的时间。当向 量时钟中(节点,计数器)对的数目达到一个阈值(如 10),最早的一对将从时钟中删除。显然,这个截断方案会导至在协调时效 率低下,因为后代关系不能准确得到。不过,这个问题还没有出现在生产环境,因此这个问题没有得到彻底研究。
Vector clock只用于发现数据冲突,不能解决数据冲突。如何解决数据冲突因场景而异,具体方法有last write win,交给client端处理,通过quorum决议事先避免数据冲突等。
故障处理:暗示移交(Hinted Handoff)
Dynamo 如果使用传统的仲裁(quorum)方式,在服务器故障和网络分裂的情况下它将是不可用,即使在最简单的失效条件下也 将降低耐久性。为了弥补这一点,它不严格执行仲裁,即使用了“马虎仲裁”(“sloppy quorum”),所有的读,写操作是由首选 列表上的前 N 个健康的节点执行的,它们可能不总是在散列环上遇到的那前N个节点。
考虑在上图例子中 Dynamo 的配置,给定 N=3。在这个例子中,如果写操作过程中节点 A 暂时 Down 或无法连接,然后通常 本来在 A 上的一个副本现在将发送到节点 D。这样做是为了保持期待的可用性和耐用性。发送到 D 的副本在其原数据中将有一 个暗示,表明哪个节点才是在副本预期的接收者(在这种情况下A)。接收暗示副本的节点将数据保存在一个单独的本地存储 中,他们被定期扫描。在检测到了 A 已经复苏,D 会尝试发送副本到 A。一旦传送成功,D 可将数据从本地存储中删除而不会 降低系统中的副本总数。
使用暗示移交,Dynamo 确保读取和写入操作不会因为节点临时或网络故障而失败。需要最高级别的可用性的应用程序可以设 置 W 为 1,这确保了只要系统中有一个节点将 key 已经持久化到本地存储 , 一个写是可以接受(即一个写操作完成即意味着 成功)。因此,只有系统中的所有节点都无法使用时写操作才会被拒绝。然而,在实践中,大多数 Amazon 生产服务设置了更 高的 W 来满足耐久性极别的要求。 一个高度可用的存储系统具备处理整个数据中心故障的能力是非常重要的。数据中心由于断电,冷却装置故障,网络故障和自 然灾害发生故障。Dynamo 可以配置成跨多个数据中心地对每个对象进行复制。从本质上讲,一个 key 的首选列表的构造是基 于跨多个数据中心的节点的。这些数据中心通过高速网络连接。这种跨多个数据中心的复制方案使我们能够处理整个数据中心 故障。
处理永久性故障:副本同步
Hinted Handoff 在系统成员流动性(churn)低,节点短暂的失效的情况下工作良好。有些情况下,在 hinted 副本移交回原来 的副本节点之前,暗示副本是不可用的。为了处理这样的以及其他威胁的耐久性问题,Dynamo 实现了反熵(anti-entropy, 或叫副本同步)协议来保持副本同步。
为了更快地检测副本之间的不一致性,并且减少传输的数据量,Dynamo 采用 MerkleTree。MerkleTree 是一个哈希树 (Hash Tree),其叶子是各个 key 的哈希值。树中较高的父节点均为其各自孩子节点的哈希。该 merkleTree 的主要优点是树 的每个分支可以独立地检查,而不需要下载整个树或整个数据集。此外,MerkleTree 有助于减少为检查副本间不一致而传输的 数据的大小。例如,如果两树的根哈希值相等,且树的叶节点值也相等,那么节点不需要同步。如果不相等,它意味着,一些 副本的值是不同的。在这种情况下,节点可以交换 children 的哈希值,处理直到它到达了树的叶子,此时主机可以识别出“不 同步”的 key。MerkleTree 减少为同步而需要转移的数据量,减少在反熵过程中磁盘执行读取的次数。
Dynamo 在反熵中这样使用 MerkleTree:每个节点为它承载的每个 key 范围(由一个虚拟节点覆盖 key 集合)维护一个单独的 MerkleTree。这使得节点可以比较 key range 中的 key 是否是最新。在这个方案中,两个节点交换 MerkleTree 的根,对应 于它们承载的共同的键范围。其后,使用上面所述树遍历方法,节点确定他们是否有任何差异和执行适当的同步行动。方案的 缺点是,当节点加入或离开系统时有许多 key rangee 变化,从而需要重新对树进行计算。通过更精炼 partitioning 方案,这个问题得到解决。
会员和故障检测
环会员(Ring Membership)
Amazon 环境中,节点中断(由于故障和维护任务)常常是暂时的,但持续的时间间隔可能会延长。一个节点故障很少意味着一 个节点永久离开,因此应该不会导致对已分配的分区重新平衡(rebalancing)和修复无法访问的副本。同样,人工错误可能导致 意外启动新的 Dynamo 节点。基于这些原因,应当适当使用一个明确的机制来发起节点的增加和从环中移除节点。管理员使用 命令行工具或浏览器连接到一个节点,并发出成员改变(membership change)指令指示一个节点加入到一个环或从环中删除 一个节点。接收这一请求的节点写入成员变化以及适时写入持久性存储。该成员的变化形成了历史,因为节点可以被删除,重 新添加多次。一个基于 Gossip 的协议传播成员变动,并维持成员的最终一致性。每个节点每间隔一秒随机选择随机的对等节点, 两个节点有效地协调他们持久化的成员变动历史。
当一个节点第一次启动时,它选择它的 Token(在虚拟空间的一致哈希节点) 并将节点映射到各自的 Token 集(Token set)。该 映射被持久到磁盘上,最初只包含本地节点和 Token 集。在不同的节点中存储的映射(节点到 token set 的映射)将在协调成 员的变化历史的通信过程中一同被协调。因此,划分和布局信息也是基于 Gossip 协议传播的,因此每个存储节点都了解对等节 点所处理的标记范围。这使得每个节点可以直接转发一个 key 的读/写操作到正确的数据集节点。
外部发现
上述机制可能会暂时导致逻辑分裂的 Dynamo 环。例如,管理员可以将节点 A 加入到环,然后将节点 B 加入环。在这种情况
下,节点 A 和 B 各自都将认为自己是环的一员,但都不会立即了解到其他的节点(也就是A不知道 B 的存在,B 也不知道 A 的存在,这叫逻辑分裂)。为了防止逻辑分裂,有些 Dynamo 节点扮演种子节点的角色。种子的发现(discovered)是通过外 部机制来实现的并且所有其他节点都知道(实现中可能直接在配置文件中指定 seed node 的 IP,或者实现一个动态配置服 务,seed register)。因为所有的节点,最终都会和种子节点协调成员关系,逻辑分裂是极不可能的。种子可从静态配置或配置 服务获得。通常情况下,种子在 Dynamo 环中是一个全功能节点。
故障检测
Dynamo 中,故障检测是用来避免在进行 get()和 put()操作时尝试联系无法访问节点,同样还用于分区转移(transferring
partition)和暗示副本的移交。为了避免在通信失败的尝试,一个纯本地概念的失效检测完全足够了:如果节点 B 不对节点 A 的 信息进行响应(即使 B 响应节点 C 的消息),节点 A 可能会认为节点 B 失败。在一个客户端请求速率相对稳定并产生节点间通信 的 Dynamo 环中,一个节点 A 可以快速发现另一个节点 B 不响应时,节点 A 则使用映射到 B 的分区的备用节点服务请求,并 定期检查节点 B 后来是否后来被复苏。在没有客户端请求推动两个节点之间流量的情况下,节点双方并不真正需要知道对方是否可以访问或可以响应。
去中心化的故障检测协议使用一个简单的 Gossip 式的协议,使系统中的每个节点可以了解其他节点到达(或离开)。有关去中心 化的故障探测器和影响其准确性的参数的详细信息,早期 Dynamo 的设计使用去中心化的故障检 测器以维持一个失败状态的全局性的视图。后来认为,显式的节点加入和离开的方法排除了对一个失败状态的全局性视图的需 要。这是因为节点是是可以通过节点的显式加入和离开的方法知道节点永久性(permanent)增加和删除,而短暂的 (temporary)节点失效是由独立的节点在他们不能与其他节点通信时发现的(当转发请求时)。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/221665.html原文链接:https://javaforall.net


