
【全文翻译】MixMatch: A Holistic Approach to Semi-Supervised Learning
摘要
半监督学习已被证明是利用未标记数据来减轻对大型标记数据集的依赖的强大范例。在这项工作中,我们统一了当前的半监督学习主导方法,以产生一种新算法MixMatch,该算法猜测数据增强的未标记示例的低熵标记,并使用MixUp混合标记和未标记的数据。MixMatch可在许多数据集和标记的数据量上大幅度获取最新的结果。 例如,在具有250个标签的CIFAR-10上,我们将错误率降低4倍(从38%降至11%),而在STL-10上降低2倍。我们还演示了MixMatch如何帮助实现显着更好的准确性与隐私权衡,以实现差异化隐私。最后,我们进行消融研究,以弄清楚MixMatch的哪些成分对其成功最重要。我们发布实验中使用的所有代码。
1、介绍
- 通过实验,我们证明MixMatch在所有标准图像基准(第4.2节)上均获得了最新的结果,并将CIFAR-10的错误率降低了4倍;
- 我们在消融研究中进一步表明,MixMatch大于其各个部分的总和;
- 我们在第4.3节中演示了MixMatch对于差异化的私人学习非常有用,它使PATE框架中的学生获得最新的最新结果,同时增强了隐私保证和准确性。
简而言之,MixMatch为未标记的数据引入了统一的损失项,可以无缝地减少熵,同时保持一致性并保持与传统正则化技术的兼容性。
2、相关工作
为了为MixMatch奠定基础,我们首先介绍SSL的现有方法。我们主要关注那些基于MixMatch的最新技术。关于SSL技术的文献很多,我们在这里不予讨论(例如,“转换”模型,基于图的方法,生成模型等)。在文献49中提供了更全面的概述。在下文中,我们将参考通用模型p_model (x|y;θ),该模型为具有参数θ的输入x在类标签y上产生分布。
2.1 一致性正则化
2.2 熵最小
在许多半监督学习方法中,一个常见的基本假设是,分类器的决策边界不应穿过边缘数据分布的高密度区域。一种强制执行此方法的方法是,要求分类器对未标记的数据输出低熵预测。这在文献18中用损失项明确完成,该项使未标记数据x的p_model (x|y;θ)的熵最小。在文献31中,这种形式的熵最小化与VAT相结合以获得更强大的结果。“ Pseudo-Label”通过根据未标记数据的高可信度预测构建硬(1-hot)标记并将其用作标准交叉熵损失的训练目标,来隐式地最小化熵。MixMatch还通过在目标分布上针对未标记数据使用“锐化”功能来隐式实现熵最小化,如3.2节所述
2.3 传统正则化
正则化是指对模型施加约束的一般方法,以使其难以记忆训练数据,因此希望使其更好地泛化到看不见的数据。我们使用权重衰减对模型参数的L2范数进行惩罚。我们还使用MixMatch中的MixUp来鼓励示例之间的凸出行为。我们将MixUp既用作正则化程序(应用于标记的数据点),又将其作为半监督学习方法(应用于未标记的数据点)。MixUp先前已应用于半监督学习; 特别是,文献45的并行工作使用了MixMatch中使用的方法的子集。我们澄清了我们的消融研究中的差异(第4.2.3节)。
3、MixMatch
在本节中,我们将介绍我们提出的半监督学习方法MixMatch。MixMatch是一种“整体”方法,结合了第2节中讨论的SSL主导范式的思想和组件。给定批处理的X个标记示例(one-hot编码,代表L个可能的标签之一)和大小相同的U个无标记实例,MixMatch会生成一批经过处理的增强标记的示例X’和一批带有“猜测”标记U’的增强的未标记示例。然后将 $ U^{\prime}
$ 和 $ X^{\prime}$用于计算单独的标记和未标记损失项。更正式地说,半监督学习的组合损失L定义为
X ′ , U ′ = M i x M a t c h ( X , U , T , K , α ) \mathcal{X}^{\mathrm{\prime }},\mathrm{ }\mathcal{U}^{\mathrm{\prime }}=MixMatch\left( \mathcal{X},\mathcal{U},\mathrm{T},\mathrm{K},\mathrm{\alpha} \right) X′,U′=MixMatch(X,U,T,K,α)
L X = 1 ∣ X ′ ∣ ∑ x , p ∈ X ′ H ( p , p m o d e l ( y ∣ x ; θ ) ) \mathcal{L}_{\mathcal{X}}=\frac{1}{\left| \mathcal{X}^{\mathrm{\prime }} \right|}\sum_{x,p\in \mathcal{X}^{\mathrm{‘}}}{H\left( p,p_{model}\left( y \mid x;\theta \right) \right)} LX=∣X′∣1x,p∈X′∑H(p,pmodel(y∣x;θ))
L U = 1 L ∣ U ′ ∣ ∑ u , q ∈ U ′ ∥ q − p m o d e l ( y ∣ u ; θ ) ∥ 2 2 \mathcal{L}_{\mathcal{U}}=\frac{1}{L\left| \mathcal{U}^{\mathrm{\prime }} \right|}\sum_{u,q\in \mathcal{U}^{\mathrm{‘}}}{\left\| q-p_{model}\left( y \mid u;\theta \right) \right\| _{2}^{2}} LU=L∣U′∣1u,q∈U′∑∥q−pmodel(y∣u;θ)∥22
L = L X + λ U L U \mathcal{L}=\mathcal{L}_{\mathcal{X}}+\lambda _{\mathcal{U}}\mathcal{L}_{\mathcal{U}} L=LX+λULU
其中 H ( p , q ) H(p,q) H(p,q)是分布 p , q p,q p,q之间的交叉熵, T , K , α T,K,\alpha T,K,α和 λ u \lambda_u λu是下面描述的超参数,算法1 中提供了完整的MixMatch算法,图1中显示了标签猜测过程的示意图。接下来,我们描述MixMatch的每个部分。
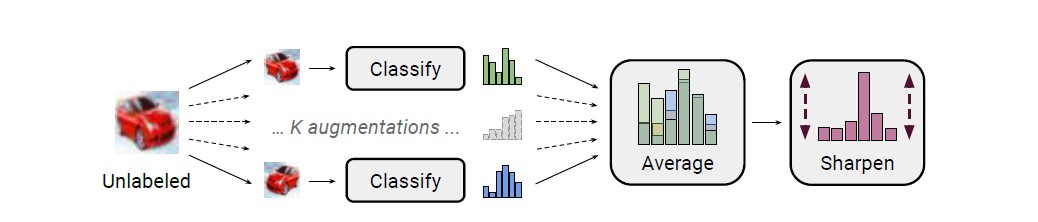
 Figure 1: MixMatch中使用的标签猜测过程图。随机数据增强被应用于未标记图像K次,并且每个增强图像都通过分类器进行馈送。然后,通过调整分布的温度来“锐化”这K个预测的平均值。有关完整说明,请参见算法1。
Figure 1: MixMatch中使用的标签猜测过程图。随机数据增强被应用于未标记图像K次,并且每个增强图像都通过分类器进行馈送。然后,通过调整分布的温度来“锐化”这K个预测的平均值。有关完整说明,请参见算法1。

3.1、数据增强
正如许多SSL方法中的典型做法一样,我们在标记和未标记的数据上都使用数据增强。对于这批标记数据X中的每个 x b x_b xb,我们生成一个转换后的版本 x ~ b = A u g m e n t ( x b ) \tilde{x}_b=Augment(x_b) x~b=Augment(xb)(算法1,第3行)。对于这批未标记数据U中的每个 u b u_b ub,我们生成K个增量 u ~ b , k = A u g m e n t ( u b ) , k ∈ ( 1 , . . . , K ) \tilde{u}_{b,k}=Augment(u_b),k\in(1,…,K) u~b,k=Augment(ub),k∈(1,...,K)(算法1,第5行)。通过以下小节中描述的过程,我们使用这些单独的增强为每个 u b u_b ub生成一个“猜测标签” q b q_b qb。
3.2、标签猜测
对于 U U U中每个未标记的示例,MixMatch使用模型的预测为该示例的标签生成一个“猜测”。稍后将这种猜测用于无监督损失项中。为此,我们通过 u b u_b ub的所有K个增量计算模型的预测类分布的平均值
q ˉ b = 1 K ∑ k = 1 K p model ( y ∣ u ^ b , k ; θ ) ∣ \bar{q}_{b}=\frac{1}{K} \sum_{k=1}^{K} \mathrm{p}_{\text {model }}\left(y \mid \hat{u}_{b, k} ; \theta\right) \mid qˉb=K1k=1∑Kpmodel (y∣u^b,k;θ)∣
在算法1中第7行。在一致性正则化方法中,通常使用数据扩充来获得未标记示例的人工目标。
锐化:在产生标签猜测时,我们执行了另一步,这受半监督学习中成功实现熵最小化的启发(在2.2节中讨论)。给定对增幅q ̅_b的平均预测,我们应用锐化函数来减少标签分布的熵。在实践中,对于锐化功能,我们使用调整此分类分布的“温度”的通用方法,即
Sharpen ( p , T ) i : = p i 1 T / ∑ j = 1 L p j 1 T \operatorname{Sharpen}(p, T)_{i}:=p_{i}^{\frac{1}{T}} / \sum_{j=1}^{L} p_{j}^{\frac{1}{T}} Sharpen(p,T)i:=piT1/j=1∑LpjT1
其中p是一些输入分类分布(具体来说在MixMatch中,p是在增强 q ˉ b \bar{q}_b qˉb上的平均类预测,如算法1,第8行所示),T是超参数。当T→0时, Sharpen ( p , T ) \operatorname{Sharpen}(p, T) Sharpen(p,T)的输出将接近Dirac(“单热”)分布。由于我们稍后将使用 q b = Sharpen ( q ˉ b , T ) q_b=\operatorname{Sharpen}(\bar{q}_b, T) qb=Sharpen(qˉb,T)作为模型对 u b u_b ub增大的预测的目标,因此降低温度会鼓励模型产生较低熵的预测。
3.3、MixUp
我们使用MixUp进行半监督学习,与SSL的以往工作不同,我们将带标签的示例和未带标签的示例与标签猜测混合在一起(如3.2节所述生成)。为了与我们的单独损失条款兼容,我们定义了MixUp的稍作修改的版本。对于两个带有相应标签概率 ( x 1 , p 1 ) , ( x 2 , p 2 ) (x_1,p_1 ),(x_2,p_2 ) (x1,p1),(x2,p2)的示例,我们通过
λ ∼ Beta ( α , α ) λ ′ = max ( λ , 1 − λ ) x ′ = λ ′ x 1 + ( 1 − λ ′ ) x 2 p ′ = λ ′ p 1 + ( 1 − λ ′ ) p 2 \begin{aligned} \lambda & \sim \operatorname{Beta}(\alpha, \alpha) \\ \lambda^{\prime} &=\max (\lambda, 1-\lambda) \\ x^{\prime} &=\lambda^{\prime} x_{1}+\left(1-\lambda^{\prime}\right) x_{2} \\ p^{\prime} &=\lambda^{\prime} p_{1}+\left(1-\lambda^{\prime}\right) p_{2} \end{aligned} λλ′x′p′∼Beta(α,α)=max(λ,1−λ)=λ′x1+(1−λ′)x2=λ′p1+(1−λ′)p2
其中α是超参数。Vanilla MixUp省略了 (9)(即设定 λ ′ = λ \lambda^\prime=\lambda λ′=λ)。鉴于已标记和未标记的示例在同一批次中串联在一起,我们需要保留批次的顺序以适当地计算各个损失成分。这是通过等式(9)实现的。确保 x ′ x^\prime x′比 x 2 x_2 x2更接近 x 1 x_1 x1。要应用MixUp,我们首先将带有标签的所有增强标签示例和带有其猜测标签的所有未标签示例收集到
X ^ = ( ( x ^ b , p b ) ; b ∈ ( 1 , … , B ) ) U ^ = ( ( u ^ b , k , q b ) ; b ∈ ( 1 , … , B ) , k ∈ ( 1 , … , K ) ) \begin{array}{l} \hat{\mathcal{X}}=\left(\left(\hat{x}_{b}, p_{b}\right) ; b \in(1, \ldots, B)\right) \\ \hat{\mathcal{U}}=\left(\left(\hat{u}_{b, k}, q_{b}\right) ; b \in(1, \ldots, B), k \in(1, \ldots, K)\right) \end{array} X^=((x^b,pb);b∈(1,…,B))U^=((u^b,k,qb);b∈(1,…,B),k∈(1,…,K))
(算法1,第10-11行)。然后,我们将这些集合合并,并将结果混洗以形成 W W W,它将用作MixUp的数据源(算法1,第12行)。对于 X ′ X^\prime X′中的第i个示例标签对,我们计算MixUp ( X ˉ i , W i ) (\bar{X}_i,W_i) (Xˉi,Wi)并将结果添加到集合 X ′ X^\prime X′中(算法1,第13行)。我们针对 i ∈ ( 1 , … , ∣ U ~ ∣ ) i\in (1,…,|\tilde{U}|) i∈(1,…,∣U~∣)计算 U i ′ = M i x U p ( U ~ i , W i + ∣ x ~ ∣ U_i^\prime=MixUp(\tilde{U}_i,W_{i+|\tilde{x}| } Ui′=MixUp(U~i,Wi+∣x~∣,有意地使用了W的其余部分,而在 X ′ X\prime X′构造中没有使用过 (算法1,第14行)。总而言之,MixMatch将X转换为 X ′ X^\prime X′这是带有数据增强和MixUp(可能与未标记的示例混合)的标记的示例的集合。类似地,将 U U U转换为 U ′ U^\prime U′,即每个未标记示例的多个扩增的集合,并带有相应的标记猜测。
3.4、损失函数
给定我们已处理的批次 X ′ X^\prime X′和 U ′ U^\prime U′’,我们使用等式(3)至(5)中所示的标准半监督损耗。公式(5)将标签和来自 X ′ X^\prime X′的模型预测之间的典型交叉熵损失与预测和来自 U ′ U^\prime U′的猜测标签的平方L2损失相结合。我们在等式(4)中使用此L2损失。(多类Brier得分),因为与交叉熵不同,它有界且对错误的预测较不敏感。由于这个原因,它经常被用作SSL中未标记的数据丢失以及预测不确定性的量度。我们不会像标准那样通过计算猜测的标签来传播梯度。
3.5、超参数
由于MixMatch结合了多种利用未标记数据的机制,因此引入了各种超参数-特别是锐化温度T,未标记扩增数K,MixUp中Beta的α参数以及无监督损失权重 λ U λ_U λU。在实践中,具有许多超参数的半监督学习方法可能会出现问题,因为使用较小的验证集很难进行交叉验证。但是,实际上,我们发现大多数MixMatch的超参数都是可以固定的,不需要根据每个实验或每个数据集进行调整。具体而言,对于所有实验,我们将T = 0.5且K =2。此外,我们仅在每个数据集的基础上更改α和 λ U λ_U λU。我们发现α= 0.75和 λ U λ_U λU=100是调谐的良好起点。在所有实验中,按照惯例,我们会在训练的前16,000步中将 λ U λ_U λU线性增加至最大值。
4 实验
我们在标准SSL基准测试(第4.2节)上测试MixMatch的有效性。我们的消融研究将MixMatch各个成分的贡献分开(第4.2.3节)。作为附加应用程序,我们将在第4.3节中考虑保护隐私的学习。
4.1、实现细节
除非另有说明,否则在所有实验中,我们均使用文献中的“ Wide ResNet-28”模型。除以下差异外,我们对模型和训练过程的实现与文献35的实现非常匹配(包括使用5000个示例选择超参数):首先,我们使用指数移动平均值,而不是降低学习率,而是对模型进行了评估。其参数的衰减率为0.999。其次,对于Wide ResNet-28模型,我们在每次更新时都应用0.0004的权重衰减。 最后,我们每 2 16 2^{16} 216个训练样本检查一个点,并报告最后20个检查点的中值错误率。例如,通过平均检查点或选择验证误差最小的检查点,可以简化分析过程,并可能会降低准确性。
4.2、半监督学习
首先,我们评估MixMatch在四个标准基准数据集上的有效性:CIFAR-10和CIFAR-100,SVHN和STL-10。在前三个数据集上评估半监督学习的标准做法是将大多数数据集视为未标记,而将一小部分用作标记数据。STL-10是专门为SSL设计的数据集,具有5,000个带标签的图像和100,000个未带标签的图像,这些图像是从与带标签的数据略有不同的分布中得出的。
4.3、基线模型
作为基准,我们考虑在第2节中介绍的中考虑的四种方法(Π模型,平均教师,虚拟对抗训练和伪标签)。我们还单独使用MixUp作为基准。MixUp被设计为用于监督学习的正则化器,因此我们将其应用于SSL进行修改,方法是将其应用于带有扩展标记的示例和带有其相应预测的扩展非标记示例。根据MixUp的标准用法,我们在MixUp生成的猜测标签和模型的预测之间使用了交叉熵损失。正如所主张的,我们在相同的代码库中重新实现了每种方法,并将它们应用于相同的模型(在4.1节中进行了描述),以确保公平地进行比较。我们重新调整了每种基线方法的超参数,与文献35中的方法相比,通常会导致边际精度提高,从而为测试MixMatch提供了更具竞争力的实验设置。
4.4、结果
4.5、消融实验
由于MixMatch结合了各种半监督学习机制,因此与文献中的现有方法有很多共通之处。 因此,我们研究了删除或添加组件的效果,以便进一步了解MixMatch性能的高低。具体来说,我们衡量的是
- 使用K个扩充的均值类别分布或针对单个扩充使用类别分布(即,设置K = 1)
- 消除温度锐化(即设置T = 1)
- 生成猜测标签时,使用模型参数的指数移动平均值(EMA),如平均指导老师所做的[44]
- 仅在标记的示例之间,仅在未标记的示例之间执行MixUp,并且不要在标记和未标记的示例之间进行混合
- 使用插值一致性训练,可以将其视为该消融研究的特例,其中仅使用未标记的混合,不应用锐化,并且EMA参数用于标签猜测。
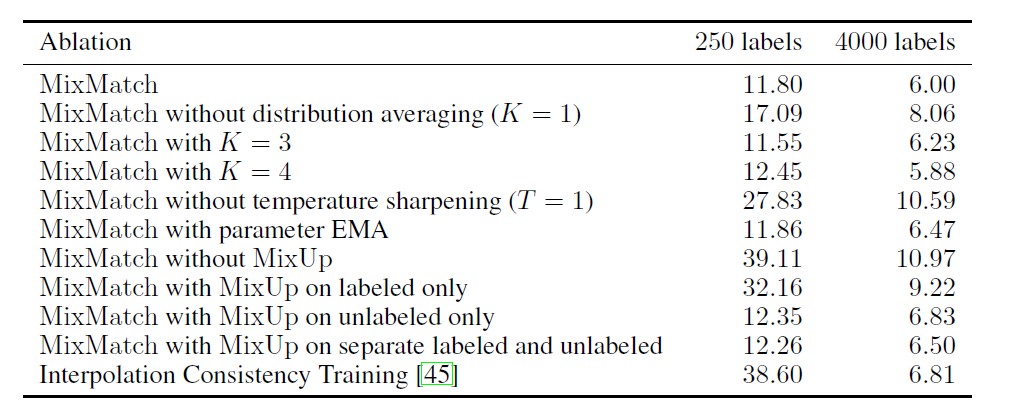
Table 4:消融研究结果。所有值均为带有250或4000个标签的CIFAR-10的错误率
4.6、隐私保护学习与推广
5 总结
我们介绍了MixMatch,这是一种半监督学习方法,它结合了当前SSL主流范式的思想和组成部分。 通过对半监督和隐私保护学习的广泛实验,我们发现在我们研究的所有设置中,MixMatch与其他方法相比,其表现均得到了显着改善,其错误率通常降低了两个或更多。在未来的工作中,我们有兴趣将半监督学习文献中的其他想法纳入混合方法,并继续探索哪些组件会产生有效的算法。另外,大多数现代半监督学习算法的工作都是根据图像基准进行评估的。我们有兴趣探索MixMatch在其他领域的有效性。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/225007.html原文链接:https://javaforall.net


