
分类任务中的不平衡问题
分类任务中的样本不平衡问题,主要是不同类别之间样本数量的不平衡,导致分类器倾向于样本较多的类别,在样本较少的类别上性能较差。
样本不均衡问题常常出现在呈长尾分布的数据中(long tailed data),如下图所示1。现实生活中很多数据都类似长尾分布,头部数据类别数据量多,尾部类别数据量少。由于尾部类别(tail classes)数据量少,模型学习到的表征信息不够丰富,导致模型并不能很好的表达尾部类。


(图片来源于1)
解决思路
解决分类任务中的样本不均衡问题,主要思路分为两大类:Re-Sampling 和 Cost-Sensitive Learning2。具体方法整理如下。
1、重采样类
对样本数量过少的类别进行“过采样”(oversampling),对样本数量过多的类别进行“欠采样”(undersampling),从而使样本类别之间量级接近。3
重采样的方法一般会导致样本分布变化,重采样后的样本类别之间比例不一定要保持1:1,这可能与实际应用中的数据分布不符。
重采样的应用方式有以下几种:
- 对多数类进行欠采样(如Random under-sampling、Tomek links4、Edited Nearest Neighbours5)
- 对少数类进行过采样(如SMOTE6)
- 结合过采样+欠采样(如SMOTE + Tomek links、SMOTE + ENN)
- 将重采样与集成方法结合(如Easy Ensemble classifier、Balanced Random Forest、Balanced Bagging)
重采样代码示例如下7,具体API可以参考scikit-learn提供的工具包8和文档9。
# 欠采样 from imblearn.under_sampling import RandomUnderSampler sampling_strategy = 0.8 rus = RandomUnderSampler(sampling_strategy=sampling_strategy) X_res, y_res = rus.fit_resample(binary_X, binary_y) ax = y_res.value_counts().plot.pie(autopct=autopct) _ = ax.set_title("Under-sampling") # 过采样 from imblearn.over_sampling import RandomOverSampler ros = RandomOverSampler(sampling_strategy=sampling_strategy) X_res, y_res = ros.fit_resample(binary_X, binary_y) ax = y_res.value_counts().plot.pie(autopct=autopct) _ = ax.set_title("Over-sampling") 仅采用重采样方法的缺点是:模型在过采样时容易过拟合,或者在欠采样时丢弃对特征学习有价值的实例。
2、平衡损失类
通过在训练过程中,对不平衡的类别给予不同的惩罚力度,使模型更容易学习到样本量少的类别。
比如,在分类任务中,给小样本类别的惩罚权重高,给大样本类别的惩罚权重低10。在sklearn中可以采用class_weight选项的“balanced”模式实现,使正则化参数的值自动调整与输入数据中的类频率成反比的权重,如n_samples / (n_classes * np.bincount(y))。11代码示例如下:
from sklearn.svm import SVC model=SVC(class_weight='balanced') model.fit(x,y) 但是,由于数据的高度不平衡性,直接用样本倒数重新加权损失并不一定能得到令人满意的结果。近年来还有很多工作围绕平衡损失的方法展开:
- Class-Balanced Loss这篇文章2提出一种新的理论框架来描述数据重叠,设计了一个在损失函数中加入与有效样本数成反比的类平衡重权项。代码开源:[github]
- Equalization Loss的这篇文章12提出一种简单的均衡损失,通过简单地忽略稀有类别的梯度来解决长尾稀有类别的问题。均衡损失保护稀有类别的学习在网络参数更新过程中处于劣势。因此,该模型能够为稀有类别的对象学习更好的判别特征。代码开源:[github]
3、集成方法类
集成类方法(boosting或bagging)通过训练多个分类器,然后结合这些分类器输出预测结果。常与重采样技术一起使用。
在每次训练时,使用小样本量类别的数据,同时从大样本量的类别随机抽取数据,这样反复多次会训练得到多个模型。在应用时,使用集成方法产生最终的预测结果。10
scikit-learn提供的相关实现有13:
- EasyEnsembleClassifier:分类器是在不同的平衡 boostrap 样本上训练的 AdaBoost 学习器的集合。平衡是通过随机欠采样实现的。
- RUSBoostClassifier:在执行提升迭代之前随机对数据集进行欠采样。
- BalancedBaggingClassifie:具有额外平衡的 Bagging 分类器。
- BalancedRandomForestClassifier:一个具有平衡的随机森林分类器。
4、异常检测、One-class分类等
对于两个数量差别悬殊的类别,尤其是负例数量很少的情况,可以考虑用异常检测算法(anomaly detection),或one-class分类方法,只对其中一类建模。
长尾分布问题的其他视角
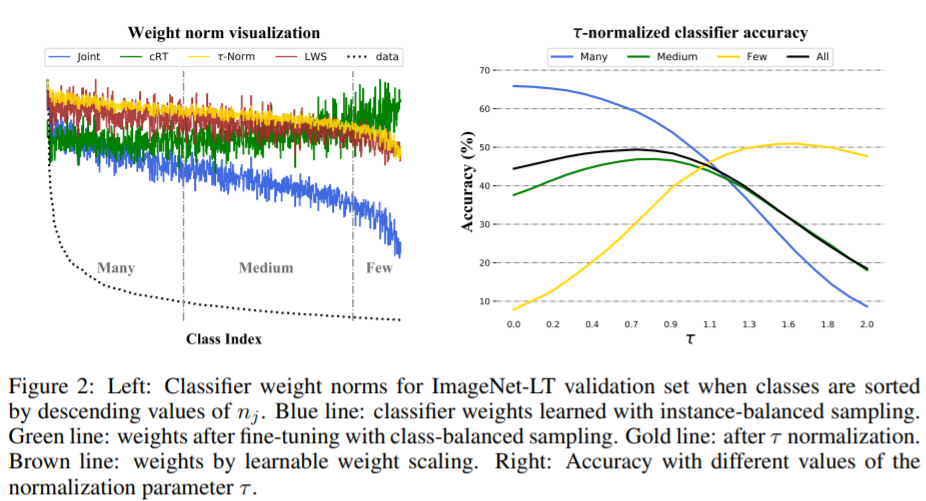
- ICLR2020 | Decoupling Representation and classifier for long-tailed recognition
这篇文章14通过将特征表达和分类器解耦开来,研究不同的平衡策略的影响,用最简单的实例平衡采样学习表示,并通过调整分类器来实现强大的长尾识别能力。
开源代码:[github]
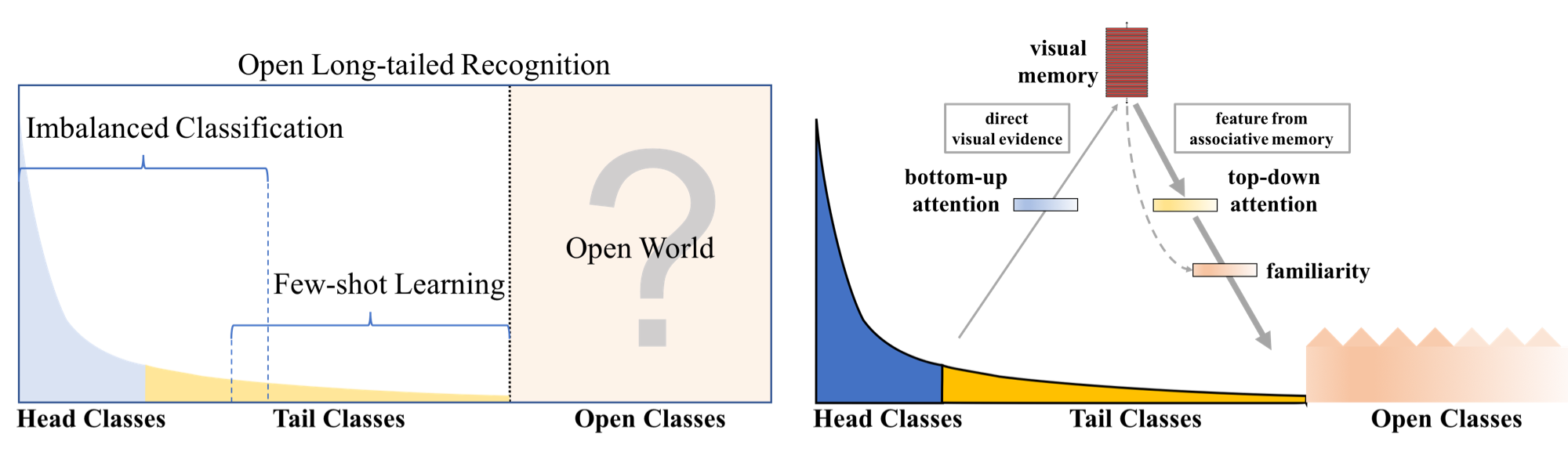
- CVPR2019 | Large-Scale Long-Tailed Recognition in an Open World
这篇文章1提出开放式长尾识别(Open Long-Tailed Recognition)。现实世界的数据通常具有长尾和开放分布,如下图所示1。一个实用的识别系统必须在多数类和少数类之间进行分类,从一些已知的实例中进行归纳,并在从未见过的实例中承认新颖性。这个任务需要在一个算法中处理 imbalanced classification, few-shot learning, 和 open-set recognition。
开源代码:[github]
- NIPS2020 | Rethinking the Value of Labels for Improving Class-Imbalanced Learning
这篇文章15通过理论推导和大量实验发现,当尾部类别数量极少时,采用重采样和代价敏感等方法也无法改善性能,而半监督和自监督均能显著提升不平衡数据下的学习表现16,如下图所示。
开源代码:[github]

- ECCV2020 | Feature Space Augmentation for Long-Tailed Data
这篇文章17提出一种通过使用从具有充足样本的类中学到的特征来增加特征空间中代表性不足的类的方法。如下图所示,使用类激活图将每个类的特征分解为类通用组件和类特定组件,然后在训练阶段通过将来自代表性不足的类的特定特征与来自混淆类的类通用特征相融合,在训练阶段动态生成代表性不足的类的新样本18。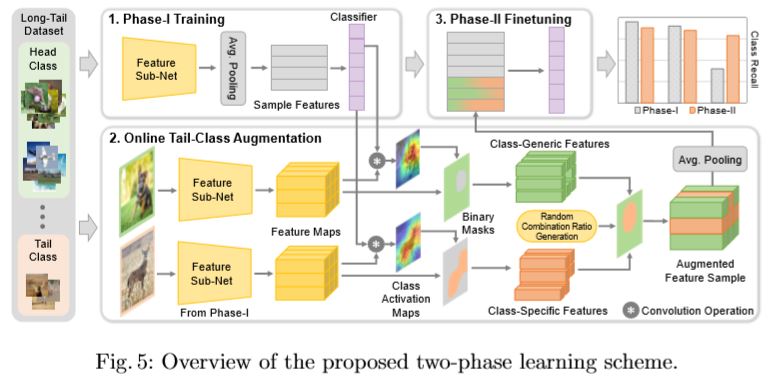
小结
本篇整理了分类任务中的样本不平衡问题的常用解决思路:
- 当数据量有一定规模时,数据重采样和平衡损失值得尝试。
- 如果各类别样本的数量都较少,可以考虑采用可解释性强的线性模型。
- 如果只有两个类别,且其中一类数量很悬殊,可以考虑用异常检测或One-class分类模型。
- 对于数量较少的尾部类别,可以考虑小样本学习、半监督和自监督等。
下一篇整理目标检测中的不平衡问题。
- https://liuziwei7.github.io/projects/LongTail.html ↩︎ ↩︎ ↩︎ ↩︎
- https://arxiv.org/pdf/1901.05555.pdf ↩︎ ↩︎
- https://en.wikipedia.org/wiki/Oversampling_and_undersampling_in_data_analysis ↩︎
- I. Tomek, “Two modifications of CNN,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 6, pp. 769-772, 1976. ↩︎
- D. Wilson, “Asymptotic Properties of Nearest Neighbor Rules Using Edited Data,” IEEE Transactions on Systems, Man, and Cybernetrics, vol. 2(3), pp. 408-421, 1972. ↩︎
- N. V. Chawla, K. W. Bowyer, L. O. Hall, W. P. Kegelmeyer, “SMOTE: Synthetic minority over-sampling technique,” Journal of Artificial Intelligence Research, vol. 16, pp. 321-357, 2002. ↩︎
- https://imbalanced-learn.org/stable/auto_examples/api/plot_sampling_strategy_usage.html#sphx-glr-auto-examples-api-plot-sampling-strategy-usage-py ↩︎
- https://github.com/scikit-learn-contrib/imbalanced-learn ↩︎
- https://imbalanced-learn.org/stable/index.html ↩︎
- https://www.zhihu.com/question/ ↩︎ ↩︎
- https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html ↩︎
- https://arxiv.org/abs/2003.05176v1 ↩︎
- https://imbalanced-learn.org/stable/references/ensemble.html ↩︎
- https://arxiv.org/abs/1910.09217 ↩︎
- https://arxiv.org/abs/2006.07529 ↩︎
- https://zhuanlan.zhihu.com/p/?utm_source=wechat_session&utm_medium=social&utm_oi=672#ref_6 ↩︎
- https://arxiv.org/abs/2008.03673 ↩︎
- https://blog.csdn.net/sinat_/article/details/ ↩︎
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/225033.html原文链接:https://javaforall.net


