
§8.5信息
8.5.1复合熵
前面(8.2.2)式得出了仅有一个随机变量情况下的熵公式(8.2)。如果抽样实验是由两个(或者多个)实验复合而成(对应于两个集合的笛卡尔积),就存在一个联合概率分布。例如掷一枚硬币还掷一次骰子,根据独立事件的概率的乘法,它们的每个结局的出现概率分布应当是0.5×(1/6)=0.0833 。这可以列成一个概率分布表
表(8.5)骰子不同点数与硬币的正面或者反面同时出现的概率
|
1点 |
2点 |
3点 |
4点 |
5点 |
6点 |
|
|
硬币正面 |
0.0833 |
0.0833 |
0.0833 |
0.0833 |
0.0833 |
0.0833 |
|
硬币反面 |
0.0833 |
0.0833 |
0.0833 |
0.0833 |
0.0833 |
0.0833 |
对于随机变量x和y的联合概率分布p(x,y)一般有表(8.6)。这个表对于两个变量是独立或者不是独立的都适用。
表(8.6) 变量x,y的联合概率p(x,y)分布表
|
y1 |
y2 |
… |
yj |
… |
ym |
|
|
x1 |
p(1,1) |
p(1,2) |
p(1,j) |
p(1,m) |
||
|
x2 |
p(2,2) |
p(2,2) |
p(2,j) |
p(2,m) |
||
|
… |
||||||
|
xi |
p(i,1) |
p(i,2) |
p(i,j) |
p(i,m) |
||
|
… |
||||||
|
xn |
p(n,1) |
p(n,2) |
p(n,j) |
p(n,m) |
它对应的熵称为复合熵,并且由下式计算
(8.6)
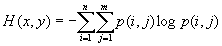
公式(8.6)就是根据两个离散随机变量的概率分布计算它的复合熵的公式。这里复合熵的符号H(x,y)仅表示这个熵是对于变量x,y 的,H 是一个值,不是x,y的函数。对于掷一枚硬币并且掷一次骰子组成的复合随机实验,其复合熵显然为-12(0.0833log20.0833)=7.89比特
复合熵的公式还可以推广到连续变量和多个变量的情况。
8.5.2条件熵
从某小学的学生中任选一人称他(她)的体重,其体重就是个随机变量,它就有个概率分布函数存在(不同的体重的出现概率不同)。如果仅对身高为1.2-1.3米的学生抽样称其体重,就得到另外一个概率分布函数。相对前一种概率分布,后者就是条件概率分布。条件就是已经知道了学生身高是1.2-1.3米。根据条件概率,利用熵公式计算的信息熵称为条件熵。
如果以x表示学生体重,以y表示身高,以 p(x∣y表示身高为y时的体重为x 的出现的概率,把熵公式用到这个特殊情况得到是熵显然应当是

上面得到的计算公式是针对y为一个特殊值y时求得的熵。考虑到y会出现各种可能值,如果问已知学生身高时(不特指某一身高,而是泛指身高已经知道)的体重的熵(不确定程度),它应当是把前面的公式依各种y的出现概率做加权平均。即
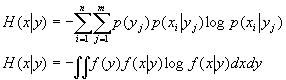
这就是条件熵的一般计算公式。上面的第二个公式是针对连续变量的,其中的f是概率密度分布函数。另外根据概率论的乘法定理p(x,y)=p(x)p(y∣x)
上面的公式也可以写成
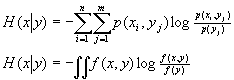
根据对数的性质,还可以把上面的公式改为
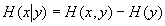
如果求x已知时y的条件熵,显然也会得到类似的公式,即还有
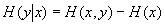
合并这两个公式有
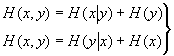
这个公式把复合熵、条件熵以及熵联系到一起了。它们也显示了熵的对称性。
条件熵仅能大于等于零而不会有负值,而且不大于原来的熵,即

它说明条件熵的最大值是无条件熵。在x与y独立无关时,条件熵与原熵值相等,即
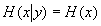
利用这些公式还可以得出复合熵小于等于对应的无条件熵的和,即
H(x,y)≤H(x)+H(y) (8.12)
这个公式表明两个(或者多个)随机变量的熵的和大于等于它们的复合熵。
在介绍复杂程度时曾经引入了“0+0可以>0”的问题。由于复杂程度与熵有对应关系,上面的公式是否与前面的结论有矛盾?我们说没有。公式(8.12)中熵的加号对应的并不是两个集合的并而是所谓笛卡尔积。而“0+0可以>0”问题对应的是两个集合(广义集合)的并运算,它不是乘积。利用熵概念也可以得到“0+0可以>0”的结论,但是它也是对应着两个广义集合的并,不是这里的笛卡尔积。
条件熵概念扩大了熵概念的应用范围,也为引入“信息”做了准备。。
8.5.3信息
信息是通过熵与条件熵的差计量的
掷一次骰子,由于六种结局(点)的出现概率相等,所以结局的不确定程度(熵)为log6 ,如果告诉你掷骰子的结局是单数或者双数,这显然是一个信息。这个信息消除了我们的一些不确定性。把消除的不确定性称为信息显然是妥当的。
说明这个问题可以通过计算无条件熵和条件熵来解决。这里的无条件熵就是log6 ,而已经知道结局是单数或者双数的条件熵可以根据前面的条件熵公式计算。为此先列出表(8.7)
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
单数 |
1/3 |
0 |
1/3 |
0 |
1/3 |
0 |
|
双数 |
0 |
1/3 |
0 |
1/3 |
0 |
1/3 |
这个表给出了不同的点数与单数或者双数同时出现的概率。它们代表不同情况时的条件概率。计算条件熵,用公式(8.7)计算比较方便。公式中的p(y有两种情况,一个指单数的出现概率,一个是双数的出现概率。它们显然都是1/2 ,因此公式(8.7)变成了
H=-6[(1/6)log(1/3)]=log3
于是条件熵H为log3 。
在不知道结局为单双数时,掷一次骰子的结局的不确定性为log6 ,在仅告诉你结局是单数或者双数时是没有全部解除你对结局的疑惑,但是它确实给了一些信息,这个信息(以I表示)就用无条件熵与条件熵的差来计量。于是有
I=log6-log3=log6/3=log2
如果对数的底是2,那么仅告诉你结局的单双数,而不告诉你绝对值,它提供的信息量就是1比特。
这个例子说明y提供的关于x的信息I,即
信息量I=(x的不确定性)- (得到了消息y以后x的不确定性)
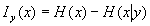
这就是计算信息的基本公式
信息量有很多性质。
如果令公式中的y=x,H(x∣y)变成了H(x∣x),其含义当然是x已知时x的条件熵,可是x 已知时它自己当然没有不确定性了。所以H(x∣x)=0 。把它带入信息公式,得到
也就是说x 值已知时所带来的信息恰好等于原来的不确定性。或者说x。这正是在一些场合下把熵直接称为信息的原因。遗憾的是有些人没有理解这个认识过程,而引出了信息是熵或者信息是负的熵的概念混乱。
如果条件熵与原熵值相等,H(x)=H(x∣y),显然信息等于零,即
I
这说明因素y 与x 无关,它当然也提供不了关于x 的任何信息。把公式(8.10)和信息公式(8.12)合并得到
Iy(x)≥0
它说明任何因素提供的信息不会小于零,信息没有负值。
利用关于复合熵的公式(8.9)与信息公式(8.12)可以得到
I(8.13)
它说明变量y含有的关于变量x的信息与变量x含有的关于变量y的信息是相同的。即变量之间含有的信息是对称的。
以上讨论的信息、信息熵都是指直接与概率联系的所谓信息论中的熵。
前文提到过,除了开方检验(CHI)以外,信息增益(IG,Information Gain)也是很有效的特征选择方法。但凡是特征选择,总是在将特征的重要程度量化之后再进行选择,而如何量化特征的重要性,就成了各种方法间最大的不同。开方检验中使用特征与类别间的关联性来进行这个量化,关联性越强,特征得分越高,该特征越应该被保留。
在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
因此先回忆一下信息论中有关信息量(就是“熵”)的定义。说有这么一个变量X,它可能的取值有n多种,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:

意思就是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大(因此我一直觉得我们的政策法规信息量非常大,因为它变化很多,基本朝令夕改,笑)。
对分类系统来说,类别C是变量,它可能的取值是C1,C2,……,Cn,而每一个类别出现的概率是P(C1),P(C2),……,P(Cn),因此n就是类别的总数。此时分类系统的熵就可以表示为:
![clip_image002[4]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B4%5D.gif "clip_image002[4]")
有同学说不好理解呀,这样想就好了,文本分类系统的作用就是输出一个表示文本属于哪个类别的值,而这个值可能是C1,C2,……,Cn,因此这个值所携带的信息量就是上式中的这么多。
信息增益是针对一个一个的特征而言的,就是看一个特征t,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即增益。系统含有特征t的时候信息量很好计算,就是刚才的式子,它表示的是包含所有特征时系统的信息量。
问题是当系统不包含t时,信息量如何计算?我们换个角度想问题,把系统要做的事情想象成这样:说教室里有很多座位,学生们每次上课进来的时候可以随便坐,因而变化是很大的(无数种可能的座次情况);但是现在有一个座位,看黑板很清楚,听老师讲也很清楚,于是校长的小舅子的姐姐的女儿托关系(真辗转啊),把这个座位定下来了,每次只能给她坐,别人不行,此时情况怎样?对于座次的可能情况来说,我们很容易看出以下两种情况是等价的:(1)教室里没有这个座位;(2)教室里虽然有这个座位,但其他人不能坐(因为反正它也不能参与到变化中来,它是不变的)。
对应到我们的系统中,就是下面的等价:(1)系统不包含特征t;(2)系统虽然包含特征t,但是t已经固定了,不能变化。
我们计算分类系统不包含特征t的时候,就使用情况(2)来代替,就是计算当一个特征t不能变化时,系统的信息量是多少。这个信息量其实也有专门的名称,就叫做“条件熵”,条件嘛,自然就是指“t已经固定“这个条件。
但是问题接踵而至,例如一个特征X,它可能的取值有n多种(x1,x2,……,xn),当计算条件熵而需要把它固定的时候,要把它固定在哪一个值上呢?答案是每一种可能都要固定一下,计算n个值,然后取均值才是条件熵。而取均值也不是简单的加一加然后除以n,而是要用每个值出现的概率来算平均(简单理解,就是一个值出现的可能性比较大,固定在它上面时算出来的信息量占的比重就要多一些)。
因此有这样两个条件熵的表达式:
![clip_image002[6]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B6%5D.gif "clip_image002[6]")
这是指特征X被固定为值xi时的条件熵,
![clip_image002[8]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B8%5D.gif "clip_image002[8]")
这是指特征X被固定时的条件熵,注意与上式在意义上的区别。从刚才计算均值的讨论可以看出来,第二个式子与第一个式子的关系就是:

具体到我们文本分类系统中的特征t,t有几个可能的值呢?注意t是指一个固定的特征,比如他就是指关键词“经济”或者“体育”,当我们说特征“经济”可能的取值时,实际上只有两个,“经济”要么出现,要么不出现。一般的,t的取值只有t(代表t出现)和 (代表t不出现),注意系统包含t但t 不出现与系统根本不包含t可是两回事。
(代表t不出现),注意系统包含t但t 不出现与系统根本不包含t可是两回事。
因此固定t时系统的条件熵就有了,为了区别t出现时的符号与特征t本身的符号,我们用T代表特征,而用t代表T出现,那么:

与刚才的式子对照一下,含义很清楚对吧,P(t)就是T出现的概率, 就是T不出现的概率。这个式子可以进一步展开,其中的
就是T不出现的概率。这个式子可以进一步展开,其中的

另一半就可以展开为:

因此特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:

公式中的东西看上去很多,其实也都很好计算。比如P(Ci),表示类别Ci出现的概率,其实只要用1除以类别总数就得到了(这是说你平等的看待每个类别而忽略它们的大小时这样算,如果考虑了大小就要把大小的影响加进去)。再比如P(t),就是特征T出现的概率,只要用出现过T的文档数除以总文档数就可以了,再比如P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的文档数除以出现了T的文档数就可以了。
从以上讨论中可以看出,信息增益也是考虑了特征出现和不出现两种情况,与开方检验一样,是比较全面的,因而效果不错。但信息增益最大的问题还在于它只能考察特征对整个系统的贡献,而不能具体到某个类别上,这就使得它只适合用来做所谓“全局”的特征选择(指所有的类都使用相同的特征集合),而无法做“本地”的特征选择(每个类别有自己的特征集合,因为有的词,对这个类别很有区分度,对另一个类别则无足轻重)。
看看,导出的过程其实很简单,没有什么神秘的对不对。可有的学术论文里就喜欢把这种本来很直白的东西写得很晦涩,仿佛只有读者看不懂才是作者的真正成功。
咱们是新一代的学者,咱们没有知识不怕被别人看出来,咱们有知识也不怕教给别人。所以咱都把事情说简单点,说明白点,大家好,才是真的好。
转自:http://www.cnblogs.com/xiedan/archive/2010/04/03/1703722.html
转载于:https://www.cnblogs.com/shixisheng/p/7152818.html
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/226275.html原文链接:https://javaforall.net


