
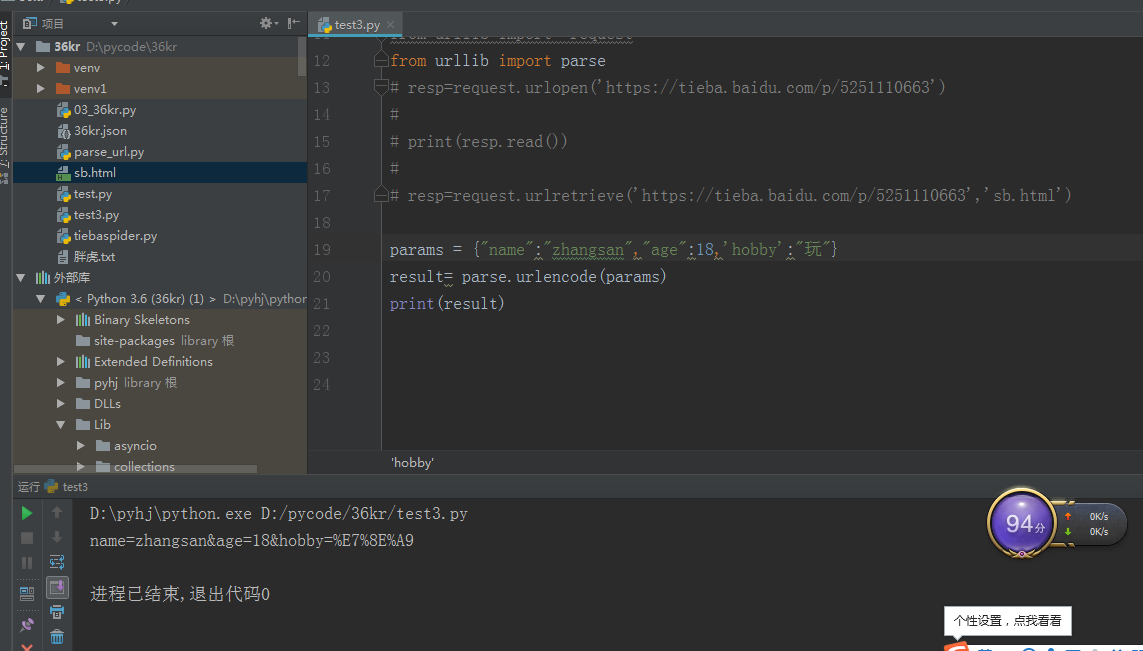
from urllib import request
#访问这个地址
# resp=request.urlopen('https://tieba.baidu.com/p/5251110663')
#
# print(resp.read())
#可以保存页面 和图片
resp=request.urlretrieve('https://tieba.baidu.com/p/5251110663','sb.html')
编解码




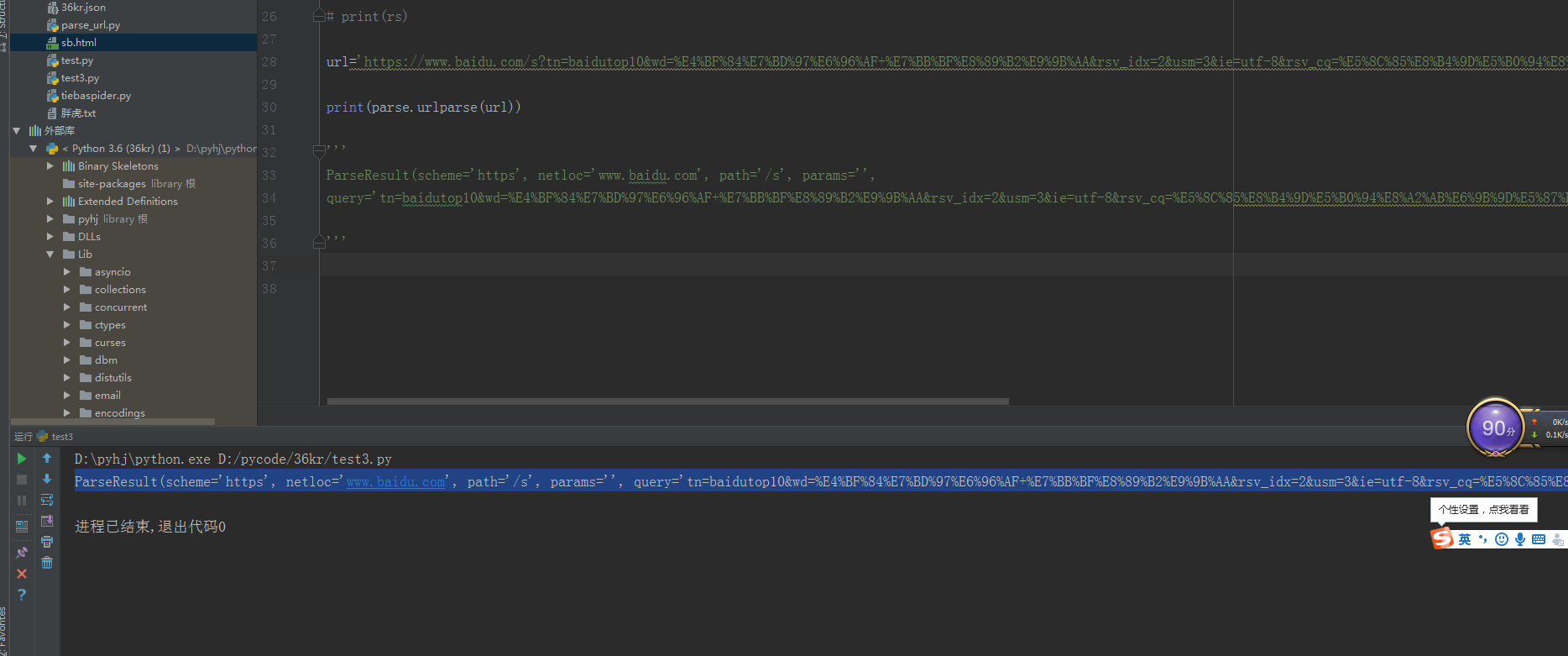
urlparse



版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/230062.html原文链接:https://javaforall.net


