
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
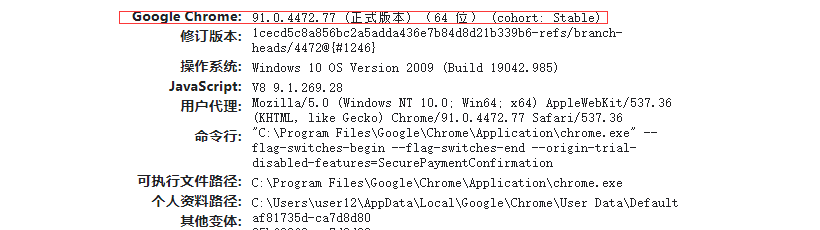
一、查看chrome版本
浏览器:chrome://version/

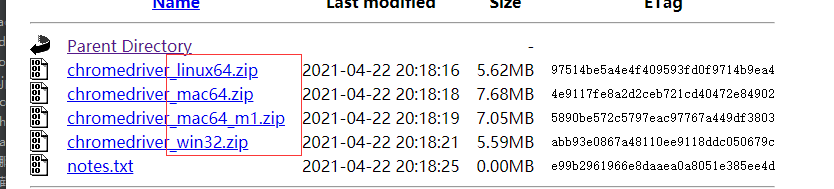
二、下载传送门
url:http://chromedriver.storage.proxy.ustclug.org/index.html
根据自己的版本进行下载
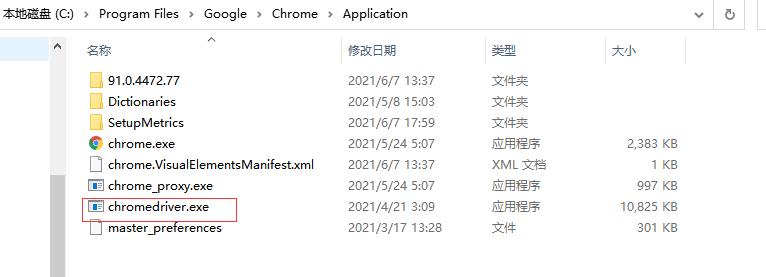
放入C:\Program Files\Google\Chrome\Application
三、由于携程是js加密看一下
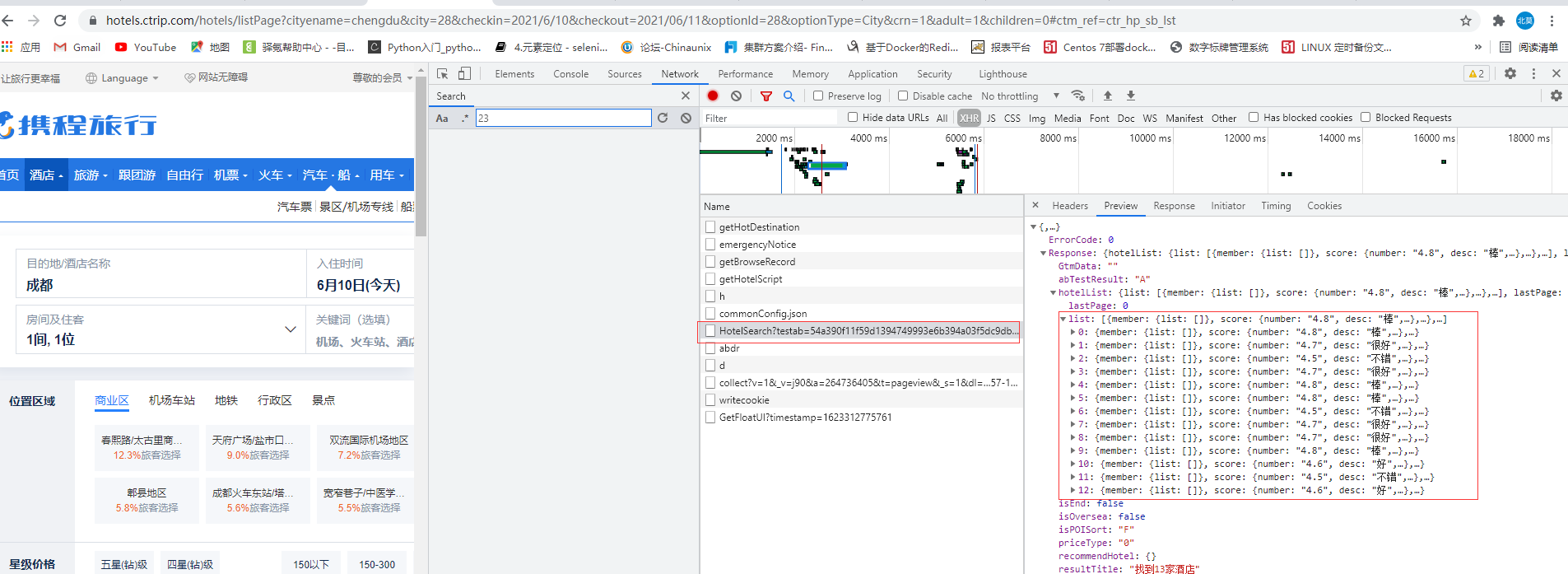

这里可以看到testab后面加密字符串,base64位加密(通过接口timestamp,appid等混合),我使用自动化爬取抓数据。
四、自动化抓取(selenium)
url='https://hotels.ctrip.com/hotels/list?city=28&checkin=2021/06/11&checkout=2021/06/12&optionId=28&optionType=City&directSearch=0&display=%E6%88%90%E9%83%BD&crn=1&adult=1&children=0&searchBoxArg=t&travelPurpose=0&ctm_ref=ix_sb_dl&domestic=1&'
'
city:城市ID
checkin:入住时间
checkout:退房时间
开始操作:
1、导入相关的库
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
2、加载chromedriver路径
path='D:\WebDriver\chromedriver_win32\chromedriver.exe'
driver=webdriver.Chrome(executable_path=path)
3、打开网页
url='https://hotels.ctrip.com/hotels/list? city=28&checkin=2021/06/11&checkout=2021/06/12&optionId=28&optionType=City&directSearch=0&display=%E6%88%90%E9%83%BD&crn=1&adult=1&children=0&searchBoxArg=t&travelPurpose=0&ctm_ref=ix_sb_dl&domestic=1&'
driver.get(url)
4、通过xpath点击搜索
driver.maximize_window() #最大化浏览器
找到QQ登陆图标
driver.implicitly_wait(30)
driver.find_element_by_xpath("//*[@id='loginbanner']/div[2]/a[2]").click()
5、通过QQ授权登陆
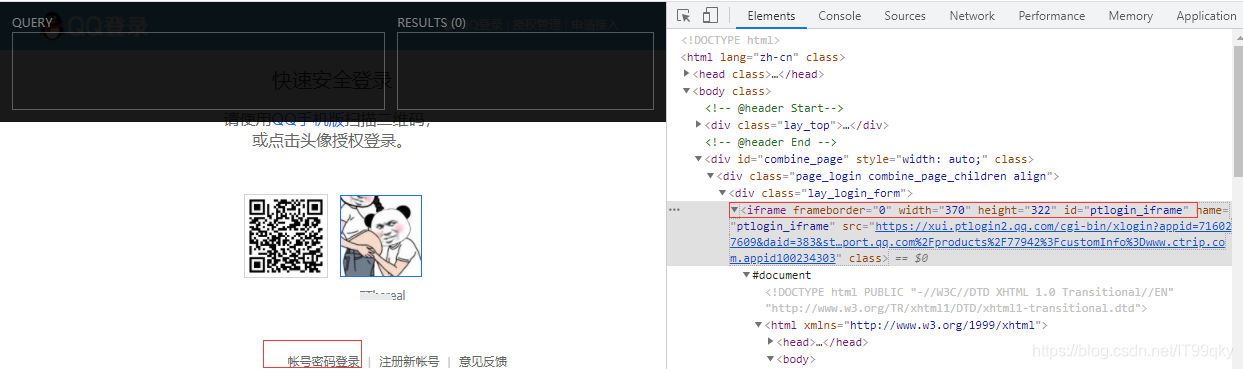
这里直接用xpath定位是定位不到,为什么呢?
是因为账户输入登陆在一个子iframe里面的,如果直接定位里面的元素是定位不到的,所以需要先切换到这个子iFrame
#跳转到QQ页面点击账号密码登陆,前提是绑定手机号
time.sleep(2)
windows=driver.window_handles # 此行代码用来新窗口
driver.switch_to.window(windows[1])
time.sleep(2)
driver.maximize_window()
driver.switch_to.frame('ptlogin_iframe')
element=driver.find_element_by_xpath('//*[@id="switcher_plogin"]')
ActionChains(driver).move_to_element(element).perform()
driver.find_element_by_id('switcher_plogin').click()
time.sleep(2)
#自适应等待,输入QQ账号
driver.find_element_by_id('u').send_keys('username')
#自适应等待,输入QQ密码
driver.find_element_by_id('p').send_keys('password')
time.sleep(3)
#自适应等待,点击授权登陆
driver.find_element_by_id('login_button').click()
time.sleep(2)
6、我们可以看见携程是拉取翻页,怎么解决,小问题,骚操作
获取页面高度
js = "return action=document.body.scrollHeight"
height = driver.execute_script(js)
7、xpath定位查看元素
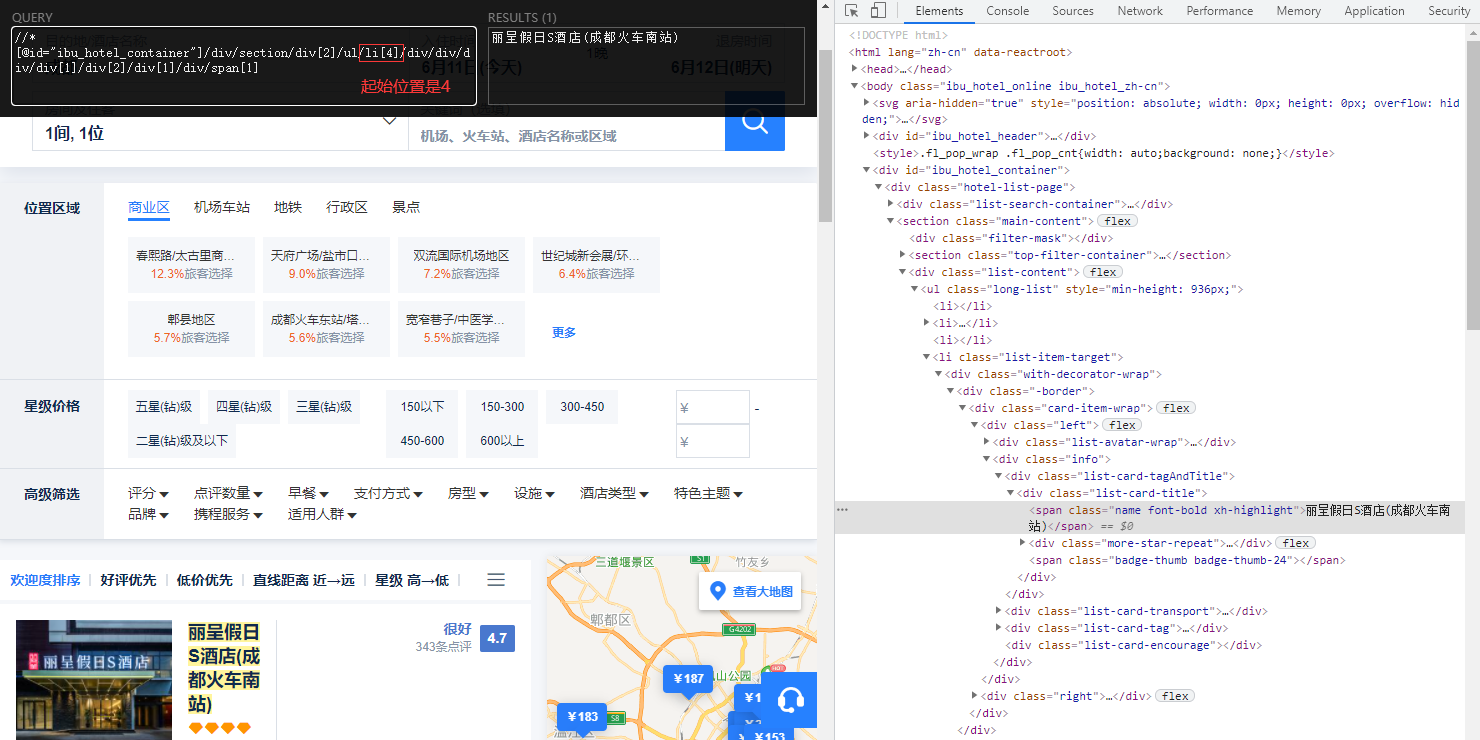
这里出现广告酒店注意,写if判断,不然价格会报错
#注意li标签是顺序,会变化自己找。
for j in range(5,21):
# 获取页面初始高度
js = "return action=document.body.scrollHeight"
height = driver.execute_script(js)
# get_attribute(‘textContent’)获取"标签里面内容"文字
name=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[1]/div[2]/div[1]/div/span[1]").get_attribute("textContent").replace('\n', '').replace('\t', '')
shangquan=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[1]/div[2]/div[2]/p/span[1]/span").get_attribute('textContent')
x=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]//div[1]/p[1]/span[2]").get_attribute("textContent")
if x == None:
price=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]//div[1]/p[1]/span").get_attribute("textContent")
else:
price=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]//div[1]/p[1]/span[2]").get_attribute("textContent")
percent=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[1]/div/div[2]/span").get_attribute("textContent")
people=driver.find_element_by_xpath("//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[1]/div/div[1]/p[2]/a").get_attribute("textContent")
addresses = "成都"
time.sleep(1)
# 将滚动条调整至页面底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
#模拟点击浏览器点击搜索更多
dianji=driver.find_element_by_xpath('//*[@id="ibu_hotel_container"]/div/section/div[2]/ul/div[2]/div/span')
dianji.click()
time.sleep(2)
print(name,shangquan,price,percent,people,addresses)
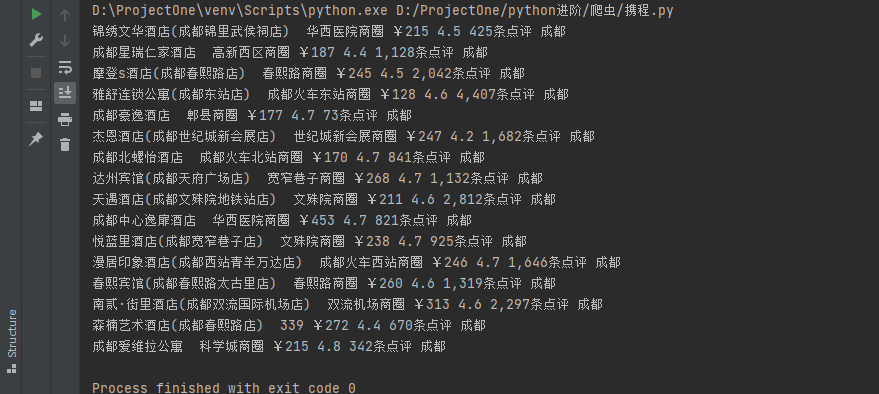
8、需要完整代码私聊,后期会做js抠出来。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/230823.html原文链接:https://javaforall.net


