
注:下文中的“桥接”、“转调”、“绑定”等词基本都是同一个概念。
log4j-over-slf4j和slf4j-log4j12是跟java日志系统相关的两个jar包,当它们同时出现在classpath下时,就可能会引起堆栈溢出异常。异常信息大致如下(摘自slf4j官网文档Detected both log4j-over-slf4j.jar AND slf4j-log4j12.jar on the class path, preempting StackOverflowError):
Exception in thread "main" java.lang.StackOverflowError at java.util.Hashtable.containsKey(Hashtable.java:306) at org.apache.log4j.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:36) at org.apache.log4j.LogManager.getLogger(LogManager.java:39) at org.slf4j.impl.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:73) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:249) at org.apache.log4j.Category.<init>(Category.java:53) at org.apache.log4j.Logger..<init>(Logger.java:35) at org.apache.log4j.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:39) at org.apache.log4j.LogManager.getLogger(LogManager.java:39) at org.slf4j.impl.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:73) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:249) at org.apache.log4j.Category..<init>(Category.java:53) at org.apache.log4j.Logger..<init>(Logger.java:35) at org.apache.log4j.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:39) at org.apache.log4j.LogManager.getLogger(LogManager.java:39) subsequent lines omitted...
现有日志体系
分析这个异常出现的具体原因之前,有必要先快速了解一下现有的Java日志体系。下图是现有Java日志体系的一个示意:

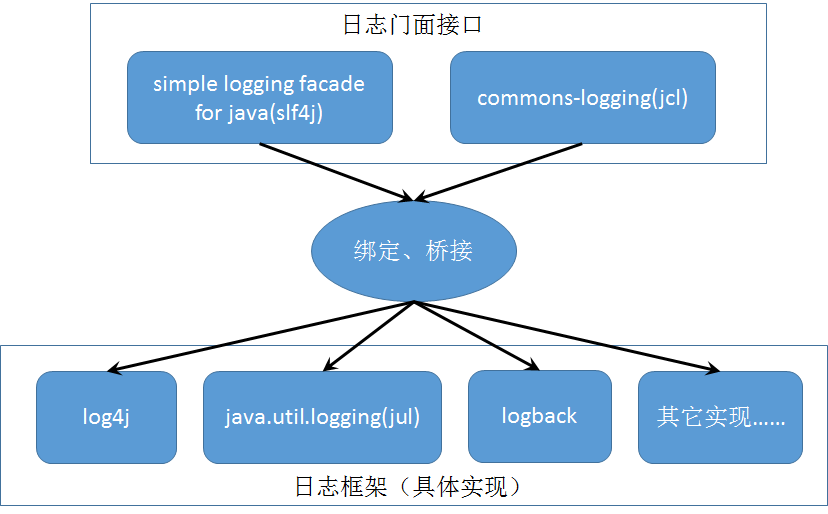
上图不是非常精准,但是能够比较清晰地展示现有Java日志体系的主体架构。Java日志体系大体可以分为三个部分:日志门面接口、桥接器、日志框架具体实现。
Java日志框架有很多种,最简单的是Java自带的java.util.logging,而最经典的是log4j,后来又出现了一个比log4j性能更好的logback,其他的日志框架就不怎么常用了。应用程序直接使用这些具体日志框架的API来满足日志输出需求当然是可以的,但是由于各个日志框架之间的API通常是不兼容的,这样做就使得应用程序丧失了更换日志框架的灵活性。
比直接使用具体日志框架API更合理的选择是使用日志门面接口。日志门面接口提供了一套独立于具体日志框架实现的API,应用程序通过使用这些独立的API就能够实现与具体日志框架的解耦,这跟JDBC是类似的。最早的日志门面接口是commons-logging,但目前最受欢迎的是slf4j。
日志门面接口本身通常并没有实际的日志输出能力,它底层还是需要去调用具体的日志框架API的,也就是实际上它需要跟具体的日志框架结合使用。由于具体日志框架比较多,而且互相也大都不兼容,日志门面接口要想实现与任意日志框架结合可能需要对应的桥接器,就好像JDBC与各种不同的数据库之间的结合需要对应的JDBC驱动一样。
需要注意的是,前面说过,上图并不精准,这只是主要部分,实际情况并不总是简单的“日志门面接口–>桥接器–>日志框架”这一条单向线。实际上,独立的桥接器有时候是不需要的,而且也并不是只有将日志门面API转调到具体日志框架API的桥接器,也存在将日志框架API转调到日志门面API的桥接器。
说白了,所谓“桥接器”,不过就是对某套API的伪实现。这种实现并不是直接去完成API所声明的功能,而是去调用有类似功能的别的API。这样就完成了从“某套API”到“别的API”的转调。如果同时存在A-to-B.jar和B-to-A.jar这两个桥接器,那么可以想象当应用程序开始调用A或者B的API时,会发生什么事。这就是最开始引出的那个stack overflow异常的基本原理。
slf4j的转接绑定
上面只是从整体上大概说了下Java现有日志体系,还看无法详细说明问题所在,需要进一步了解一下slf4j与具体日志框架的桥接情况。
slf4j桥接到具体日志框架
下图来自slf4j官网文档Binding with a logging framework at deployment time:
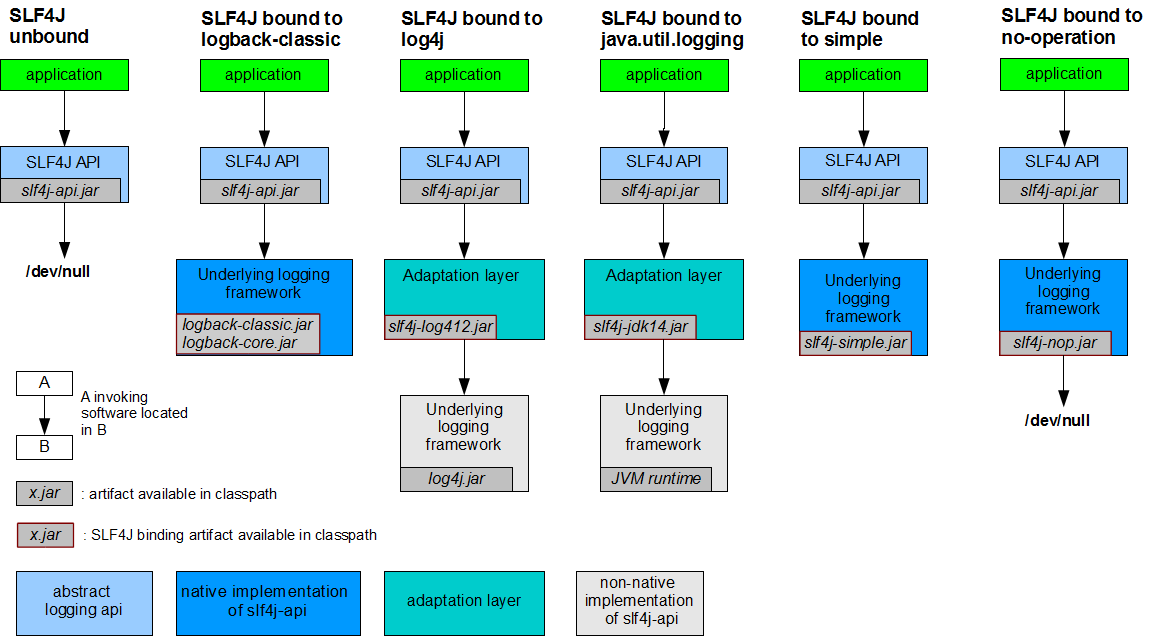
可以看到slf4j与具体日志框架结合的方案有很多种。当然,每种方案的最上层(绿色的应用层)都是统一的,它们向下都是直接调用slf4j提供的API(浅蓝色的抽象API层),依赖slf4j-api.jar。然后slf4j API向下再怎么做就非常自由了,几乎可以使用所有的具体日志框架。注意图中的第二层是浅蓝色的,看左下角的图例可知这代表抽象日志API,也就是说它们不是具体实现。如果像左边第一种方案那样下层没有跟任何具体日志框架实现相结合,那么日志是无法输出来的(这里不确定是否可能会默认输出到标准输出)。
图中第三层明显就不如第一、二层那么整齐划一了,因为这里已经开始涉及到了具体的日志框架。
首先看第三层中间的两个湖蓝色块,这是适配层,也就是桥接器。左边的slf4j-log4j12.jar桥接器看名字就知道是slf4j到log4j的桥接器,同样,右边的slf4j-jdk14.jar就是slf4j到Java原生日志实现的桥接器了。它们的下一层分别是对应的日志框架实现,log4j的实现代码是log4j.jar,而jul实现代码已经包含在了JVM runtime中,不需要单独的jar包。
再看第三层其余的三个深蓝色块。它们三个也是具体的日志框架实现,但是却不需要桥接器,因为它们本身就已经直接实现了slf4j API。slf4j-simple.jar和slf4j-nop.jar这两个不用多说,看名字就知道一个是slf4j的简单实现,一个是slf4j的空实现,平时用处也不大。而logback之所以也实现了slf4j API,据说是因为logback和slf4j出自同一人之手,这人同时也是log4j的作者。
第三层所有的灰色jar包都带有红框,这表示它们都直接实现了slf4j API,只是湖蓝色的桥接器对slf4j API的实现并不是直接输出日志,而是转去调用别的日志框架的API。
其它日志框架API转调回slf4j
如果只存在上面这些从sfl4j到其他日志框架的桥接器,可能还不会出什么问题。但是实际上还有另外一类桥接器,它们的作用跟上面的恰好相反,它们将其它日志框架的API转调到slf4j的API上。下图来自slf4j官网文档Bridging legacy APIs:
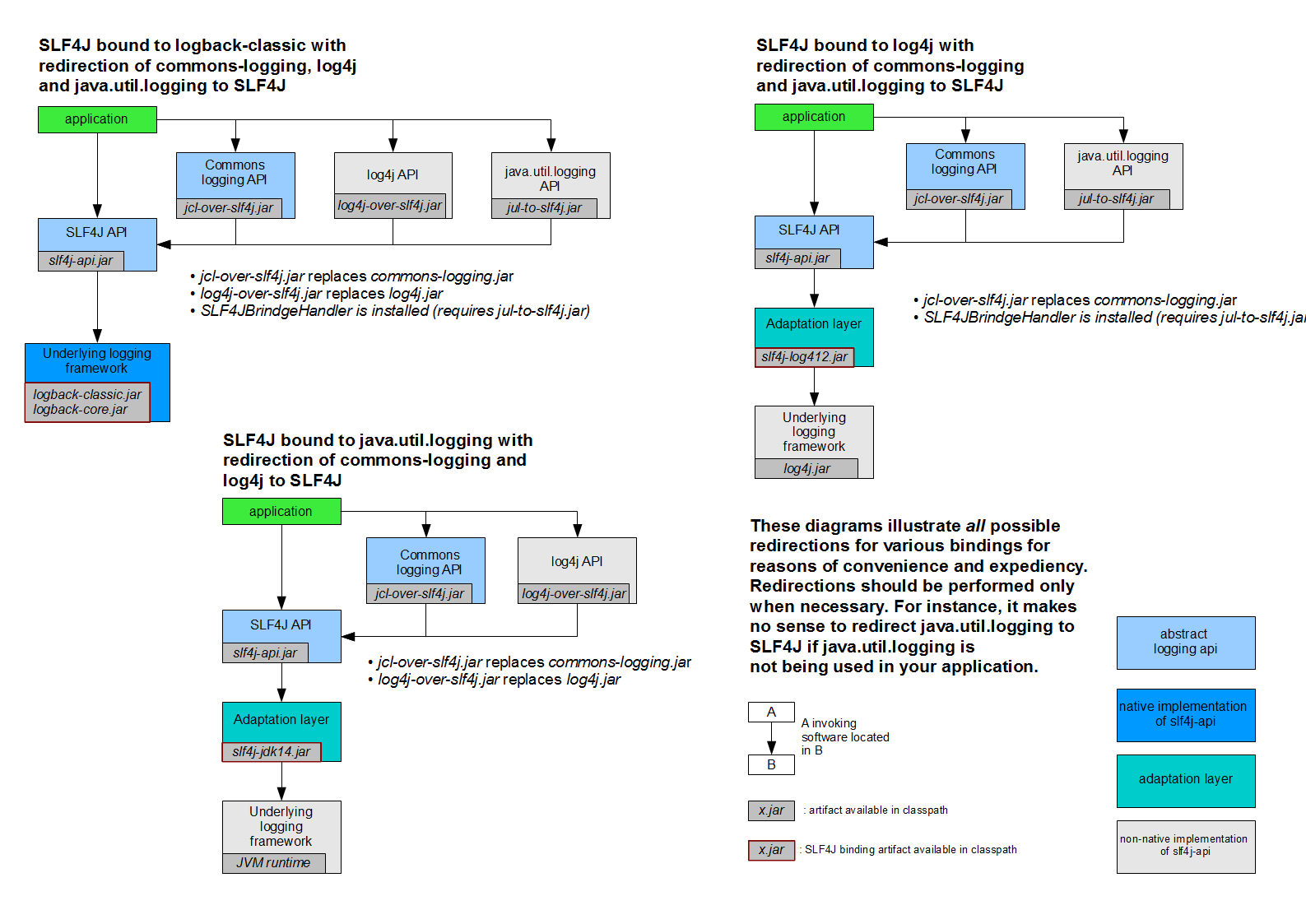
上图展示了目前为止能安全地从别的日志框架API转调回slf4j的所有三种情形。
以左上角第一种情形为例,当slf4j底层桥接到logback框架的时候,上层允许桥接回slf4j的日志框架API有log4j和jul。jcl虽然不是什么日志框架的具体实现,但是它的API仍然是能够被转调回slf4j的。要想实现转调,方法就是图上列出的用特定的桥接器jar替换掉原有的日志框架jar。需要注意的是这里不包含logback API到slf4j API的转调,因为logback本来就是slf4j API的实现。
看完三种情形以后,会发现几乎所有其他日志框架的API,包括jcl的API,都能够随意的转调回slf4j。但是有一个唯一的限制就是转调回slf4j的日志框架不能跟slf4j当前桥接到的日志框架相同。这个限制就是为了防止A-to-B.jar跟B-to-A.jar同时出现在类路径中,从而导致A和B一直不停地互相递归调用,最后堆栈溢出。目前这个限制并不是通过技术保证的,仅仅靠开发者自己保证,这也是为什么slf4j官网上要强调所有合理的方式只有上图的三种情形。
到这里,在开始所展示的那个异常的原理基本已经清楚了。此外,通过上图还可以看出可能会出现类似异常的组合不仅仅是log4j-over-slf4j和slf4j-log4j12,slf4j官网还指出了另外一对:jcl-over-slf4j.jar和slf4j-jcl.jar
代码示例
前面的分析都是理论上的,实际代码中即便同时使用了log4j-over-slf4j和slf4j-log4j12,也未必一定会出现异常。下面的代码调用slf4j的API输出日志,slf4j底层桥接到log4j:
package test; public class HelloWorld { public static void main(String[] args) { org.apache.log4j.BasicConfigurator.configure(); org.slf4j.Logger logger = org.slf4j.LoggerFactory .getLogger(HelloWorld.class); logger.info("Hello World"); } }配置classpath上的jar包为(注意log4j在log4j-over-slf4j之前):
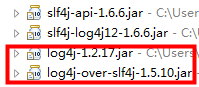
在这种情况下运行测试程序是能够正常输出日志的,不会出现stack overflow异常。但是如果调整classpath上的jar顺序为:
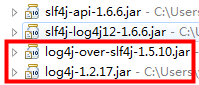
再运行测试程序就出现类似于本文最开始的stack overflow异常了,可以看到明显的周期性重复:

序列图分析
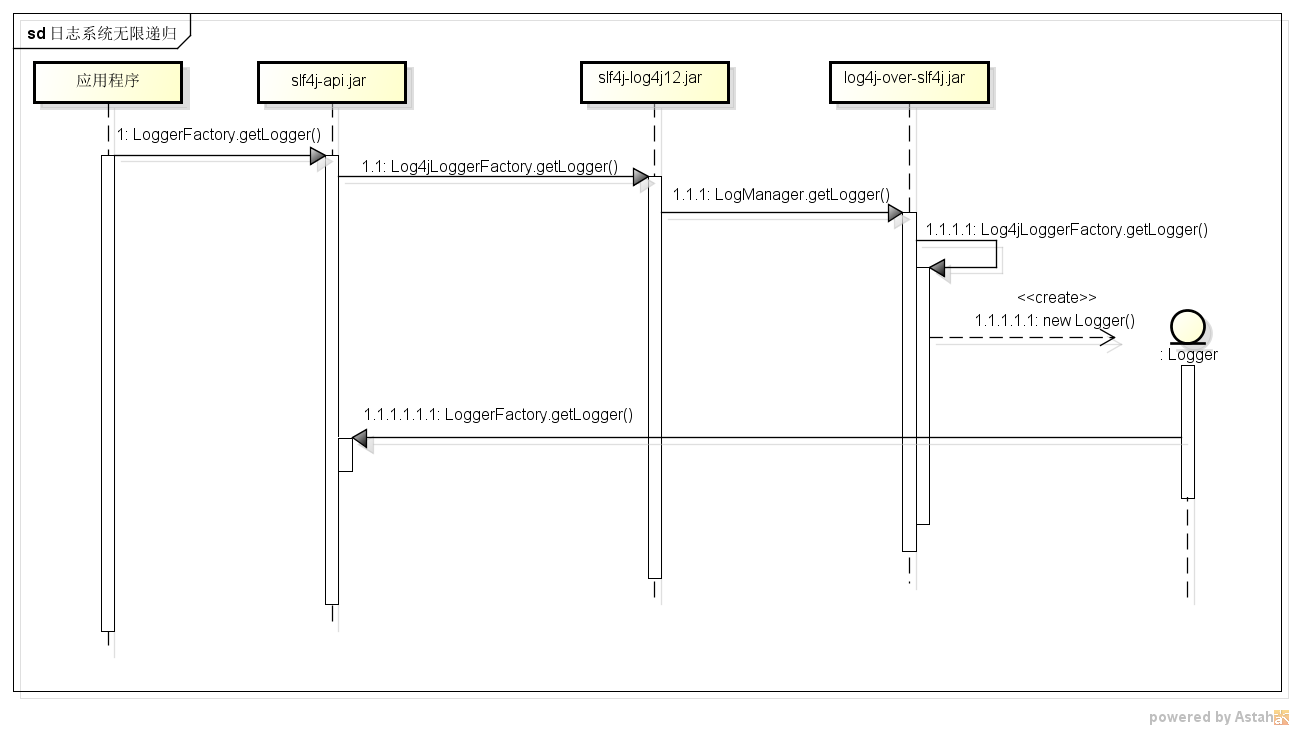
上图是堆栈溢出的详细调用过程序列图。从调用1开始,依次调用1.1、1.1.1……最后到了1.1.1.1.1.1(图中最后一个调用)的时候,发现它跟1是完全一样的,那么后续的过程就是完全一样的重复了。
需要特别说明的是最开始的导火索并不只有图中所示的LoggerFactory.getLogger()一种,应用程序中能够触发堆栈溢出异常的直接调用还有好几种其它的,比如前面示例代码中触发异常的实际上是第一条语句org.apache.log4j.BasicConfigurator.configure(),但后续的互相无限递归调用过程基本都是跟上图相同的过程。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/231265.html原文链接:https://javaforall.net

![使用R中merge()函数合并数据[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
