
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
以 LeetCode102 作为例子:
题目描述
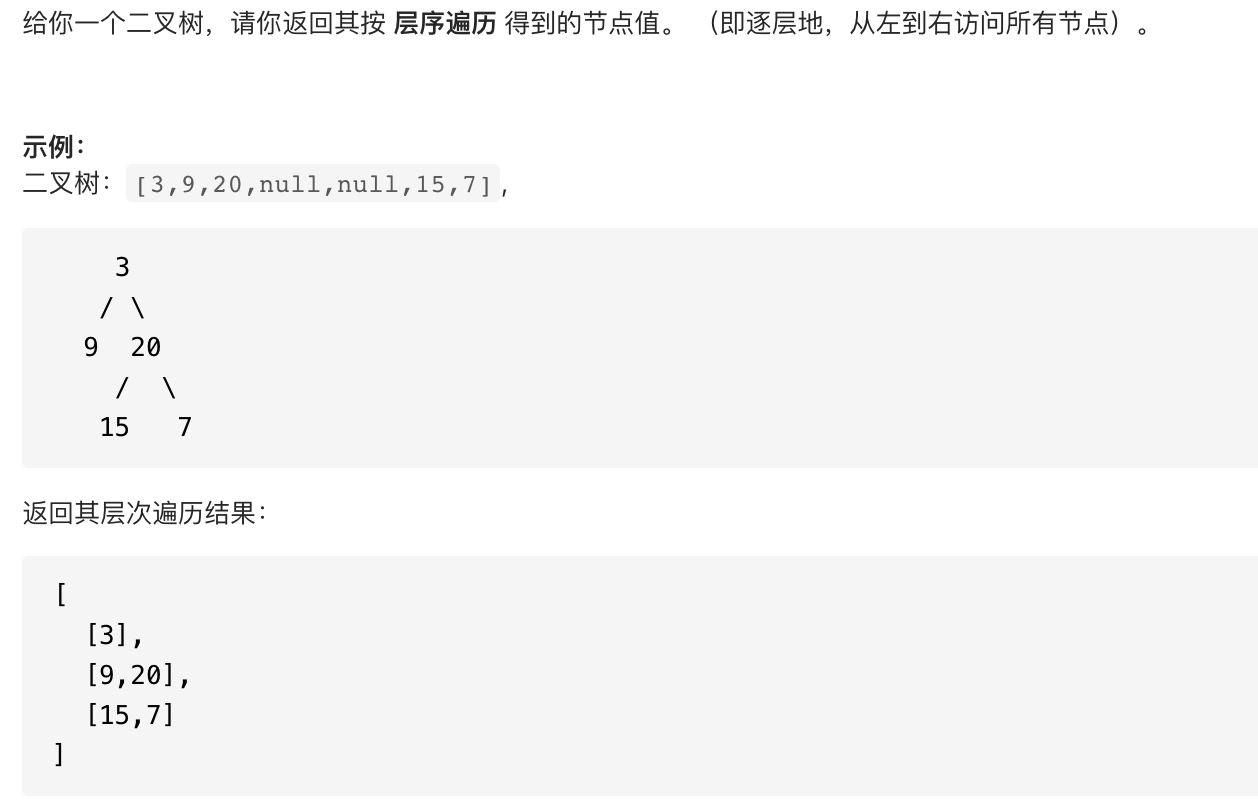

思路描述
层序遍历需要用到的数据结构是队列。需要考虑的问题是:如何标识当前节点的层数。
有以下三种方法:
方法 1
将每个节点表示为一个二元组 (node, level),这种方法效率太低,不考虑。感兴趣可以参考
方法 2
遍历完一层节点后,在队列中插入一个标记节点NULL,这个标记节点没有具体意义,只是标识某一层已经遍历结束。
这种方法的缺点在于,假如想要在层序遍历过程中,有元素为 NULL,那么标记节点就会出现混淆。
这种方法的代码我经常用,如下:
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) return result;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
queue.offer(null);
List<Integer> layer = new ArrayList<>();
while (!queue.isEmpty()) {
if (queue.peek() == null) {
result.add(layer);
queue.poll();
if (queue.isEmpty()) break;
queue.offer(null);
layer = new ArrayList<>();
continue;
}
TreeNode poll = queue.poll();
layer.add(poll.val);
if (poll.left != null) queue.offer(poll.left);
if (poll.right != null) queue.offer(poll.right);
}
return result;
}
}
方法 3
方法 3 是按层进行操作队列,每次循环不是取出一个节点,而是取出一整层节点。
我们可以用一种巧妙的方法修改 BFS:
- 首先根元素入队
- 当队列不为空的时候
- 求当前队列的长度 s_is
- 依次从队列中取 s_is 个元素进行拓展,然后进入下一次迭代
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/solution/er-cha-shu-de-ceng-xu-bian-li-by-leetcode-solution/
来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
代码如下:
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> ret = new ArrayList<List<Integer>>();
if (root == null) {
return ret;
}
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(root);
while (!queue.isEmpty()) {
List<Integer> level = new ArrayList<Integer>();
int currentLevelSize = queue.size();
for (int i = 1; i <= currentLevelSize; ++i) {
TreeNode node = queue.poll();
level.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
ret.add(level);
}
return ret;
}
}
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/solution/er-cha-shu-de-ceng-xu-bian-li-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/231285.html原文链接:https://javaforall.net


