
BLEU 就是用来衡量机器翻译文本与参考文本之间的相似程度的指标,取值范围在0-1, 取值越靠近1表示机器翻译结果越好。
最初的BLEU

根据这个例子和上述的算法, 可以很容易的计算当前文本的precision. 整个candidate doc 的单词长度为7, 而且每一个单词都在reference doc里面出现过, 所以此时累加值为7, 因此准去度为:

P=7/7=1
但是实际上这个翻译非常不理想, 这也是最初的BLEU评估指标不完善的地方, 当遇到出现较多常见词汇时, 翻译质量不高的译文还能够得到较高的precision, 因此也诞生了后续的改良型BLEU计算指标的算法.
改良型BLEU(n-gram)
改良型BLEU. 上面提到的计算BLEU的方法是以单个词为基准进行计算. 改良型的BLEU引入将多个词组合在一起形成一个gram的思想, 比如最初版的Bleu的计算可以看做一个单词构成的gram(这是一种特殊情况), 这种特殊组合被叫做uni-gram, 两个单词的组合叫做bi-gram 以此类推. 因此就可以构成1个单词长度到n个单词长度的多种单词组合(每一种单词长度可能存在不同的组合). 每一种长度的gram都可以计算出一个相应的precision PnPn. 对于该种长度gram 的precision我们还需要把它们整合起来, 一般使用加权集合平均的方法将nn个计算出的precision整合成一个precision. 因此BLEU指标. 公式的推导过程如下:

短译句的惩罚因子
上面的算法已经足够可以有效的翻译评估了,然而N-gram的匹配度可能会随着句子长度的变短而变好,因此会存在这样一个问题:一个翻译引擎只翻译出了句子中部分句子且翻译的比较准确,那么它的匹配度依然会很高。为了避免这种评分的偏向性,BLEU在最后的评分结果中引入了长度惩罚因子(Brevity Penalty)。


对于n-gram:
- 对candidate和references分别分词(n-gram分词)
- 统计candidate和references中每个word的出现频次
- 对于candidate中的每个word,它的出现频次不能大于references中最大出现频次
这一步是为了整治形如the the the the the这样的candidate,因为the在candidate中出现次数太多了,导致分值为1。为了限制这种不正常的candidate,使用正常的references加以约束。 - candidate中每个word的出现频次之和除以总的word数,即为得分score
- score乘以句子长度惩罚因子即为最终的bleu分数
这一步是为了整治短句子,比如candidate只有一个词:the,并且the在references中出现过,这就导致得分为1。也就是说,有些人因为怕说错而保持沉默。
BLEU
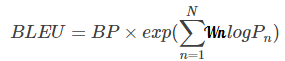
BLEU的原型系统采用的是均匀加权,即Wn=1/N 。N的上限取值为4,即最多只统计4-gram的精度。
由于各N-gram统计量的精度随着阶数的升高而呈指数形式递减,所以为了平衡各阶统计量的作用,对其采用几何平均形式求平均值然后加权,再乘以长度惩罚因子,得到最后的评价公式:
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/231421.html原文链接:https://javaforall.net


