
0x10 插桩
0x11 afl-gcc
afl-gcc 是 gcc/clang 的替代编译器。afl-gcc 其实就是 gcc 的包装,使用 afl-gcc 依赖 afl-as,因此需要知道 afl 的安装路径。afl 的默认安装路径是 /usr/local/lib/afl/,通过编译的方式,可以更改安装路径,更改之后,可以通过 AFL_PATH 设置环境变量。
如果设置了 AFL_HARDEN,afl-gcc 可以用更多的编译选项编译目标程序,这样可以检测到更加可靠的内存问题。比如,通过 AFL_USE_ASAN 打开 ASAN (地址消杀器)
查看 afl-gcc 源码
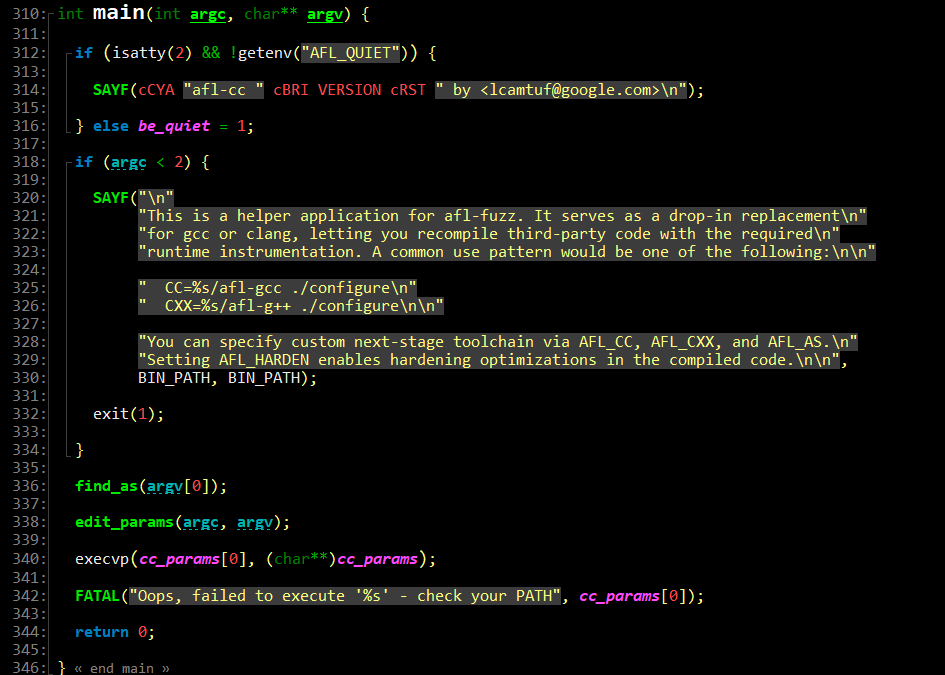

find_as(argv[0]); //找到gcc/clang/llvm编译器 edit_params(argc, argv); //处理参数 execvp(cc_params[0], (char**)cc_params); //执行程序 cc_params 的赋值是在 edit_params 函数中完成的,根据用户输入的参数,选择不同的编译器,同时也会自动加入一些编译选项。直接查看 edit_params,发现代码比较复杂,那么可以在代码中,加入打印日志的代码1,看看 afl-gcc 实际参数
for (int i = 0; i < sizeof(cc_params); ++i) {
SAYF("%s ", *(cc_params + i)); } 这时,再使用 afl-gcc 编译一个简单的程序

可以看到,afl-gcc 其实就是 gcc 的包装,只是会自动加上 -B /usr/local/lib/afl -g -O3
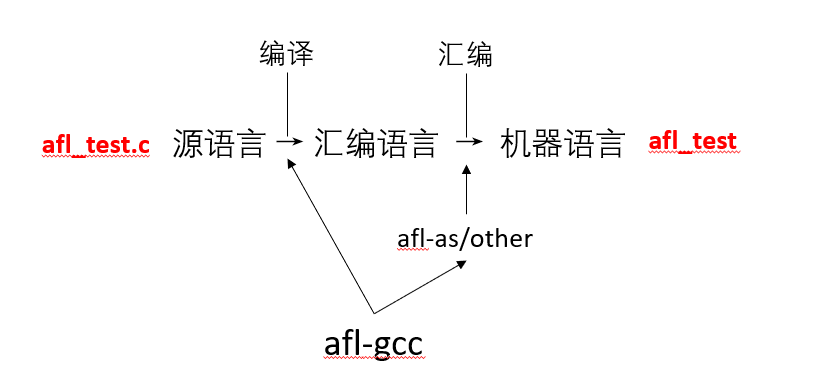
-B <目录> 将 <目录> 添加到编译器的搜索路径中 -g 生成调试信息 -O3 编译优化 编译器会根据 -B 添加的路径中,搜索后续的汇编和链接器,从下图可以看出,实际的汇编器是 afl-as

关于 ASAN
(Address-Sanitizier,地址销杀器)
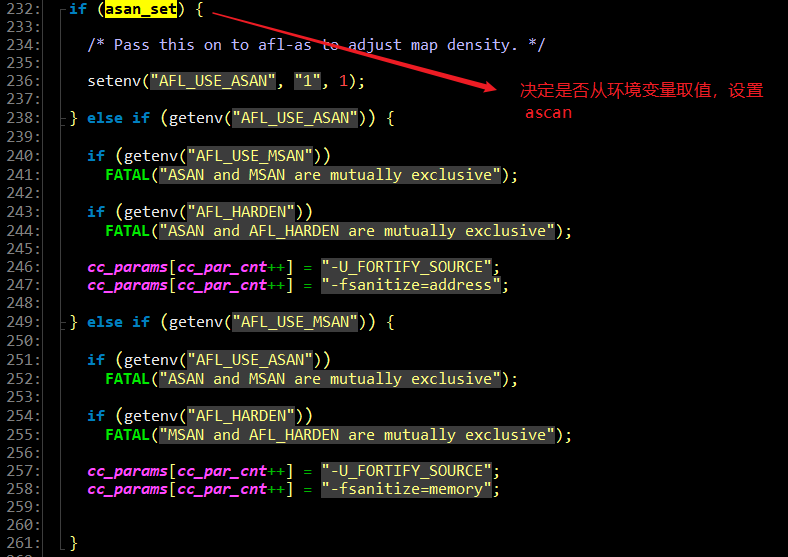
因此,如果要开启 ASAN,只需要修改源码中的 asan_set=1,或者设置环境变量 export AFL_USE_ASAN=1
afl 插桩点2
总结:afl-gcc.c 用于生成 afl-gcc 文件,其实质是 gcc 的包装,并非一个独立的改进的 gcc 编译器。其指定了编译器的搜索路径,编译器默认优先使用该路径中的汇编器和链接器,即 afl-as,因此,实际的插桩工作发生在汇编的时候。
0x12 afl-as
afl-as 用于预处理编译器生成的汇编文件,并插入 afl-as.h 文件中提供的二进制指令。使用 afl-gcc / afl-clang,工具链会自动调用 afl-as 汇编器。
afl-as.c 源码:使用 gettimeofday 获得系统时间,当前时间作为种子生成随机数,该随机数用来标识分支 key。函数 add_instrumentation 用于真正的插桩
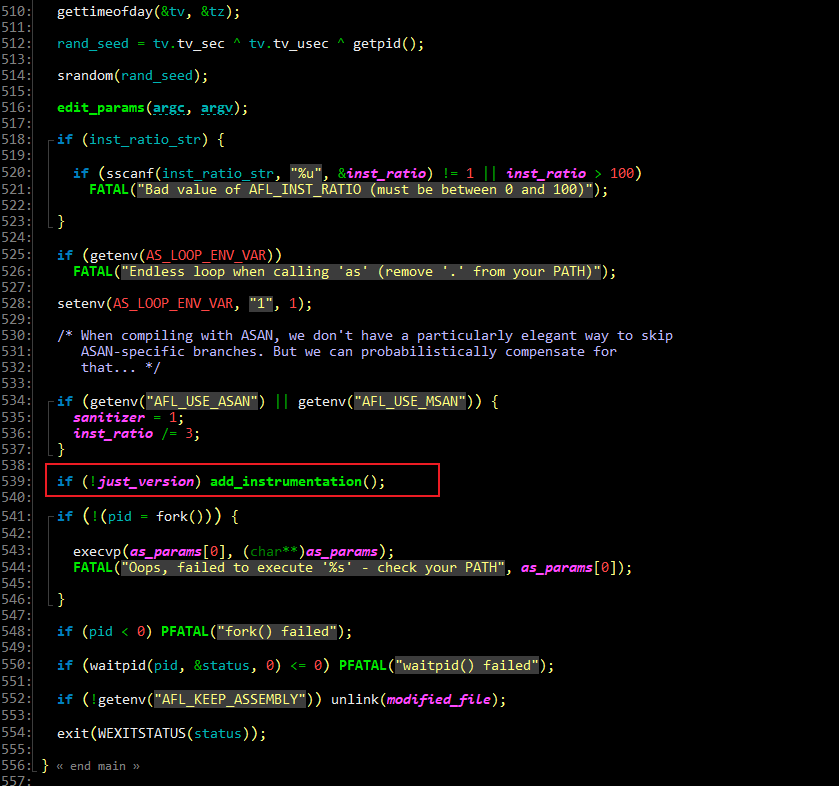
函数 add_instrumentation 在合适的地方插入指令。查看该函数的源码
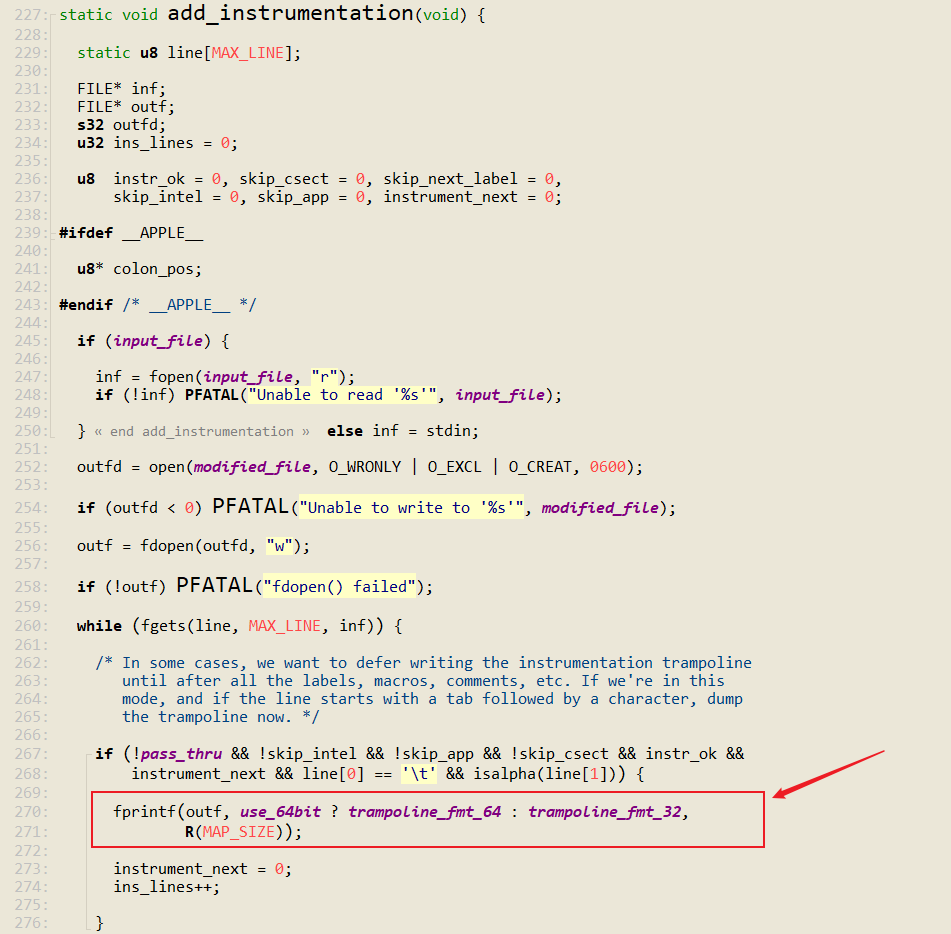
插桩位置
插桩条件的代码如下3
if (!pass_thru && !skip_intel && !skip_app && !skip_csect && instr_ok && instrument_next && line[0] == '\t' && isalpha(line[1])) - 首先需要明确的一点是,afl-as 只对代码进行插桩,
instr_ok就是用来检测当前文件行是否是代码段。如果是代码,则 instr_ok = 1 - 其次,afl-as 需要在每个基本块(basic block)中插桩,而判断是否是basic block 的结果就存放在
instrument_next中
判断是否是 basic block 的方法有两种:
- 查找标识符;
- 判断条件跳转指令
basic block 标识符包含了冒号和点号,以点开头,中间是数字和字母(个人理解:可以理解为每个函数的开头,就是标识符),因此通过判断标识符就能找到 basic block
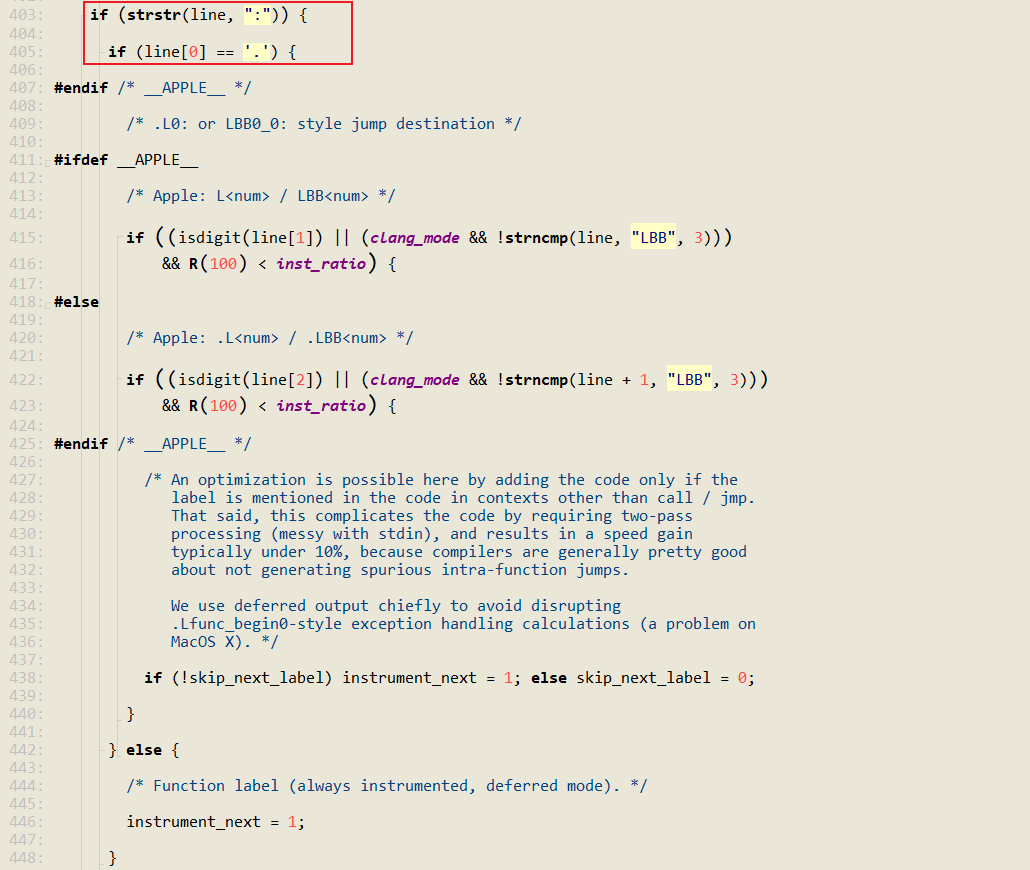
另外就是最为典型的条件分支,根据跳转,找到相应的基本块

注意,并非所有基本块都需要插桩,于是函数 add_instrumentation 也包含了不需要插桩的逻辑代码,不需要插桩的代码: Intel汇编、源代码内嵌汇编代码。

插桩内容
执行的插桩代码实际上是
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); 根据当前系统是否是 64 位,选择相应的汇编代码,例如,如果编译 32 位程序,则插入的代码是 trampoline_fmt_32 ,该变量的定义是在 afl-as.h 文件中
static const u8* trampoline_fmt_32 = "\n" "/* --- AFL TRAMPOLINE (32-BIT) --- */\n" "\n" ".align 4\n" "\n" "leal -16(%%esp), %%esp\n" "movl %%edi, 0(%%esp)\n" "movl %%edx, 4(%%esp)\n" "movl %%ecx, 8(%%esp)\n" "movl %%eax, 12(%%esp)\n" "movl $0x%08x, %%ecx\n" "call __afl_maybe_log\n" "movl 12(%%esp), %%eax\n" "movl 8(%%esp), %%ecx\n" "movl 4(%%esp), %%edx\n" "movl 0(%%esp), %%edi\n" "leal 16(%%esp), %%esp\n" "\n" "/* --- END --- */\n" "\n"; 这段汇编主要做了以下工作
- 保存 edi 等寄存器
- 将 ecx 的值设置为 fprintf() 所要打印的变量(key)内容
- 调用方法__afl_maybe_log()
- 恢复寄存器
实际验证
同样的,我们在源码中,插入打印的代码,获得 afl-as 实际执行的命令,如下图所示,可以看出,只是一个正常的 as 命令,那么实际到底插桩了哪些指令呢?

从反编译的代码看到插桩的是 _afl_maybe_log,并且会在每个基本块上插入插桩的函数,每个插桩函数会有一个唯一的参数,代表路径 id
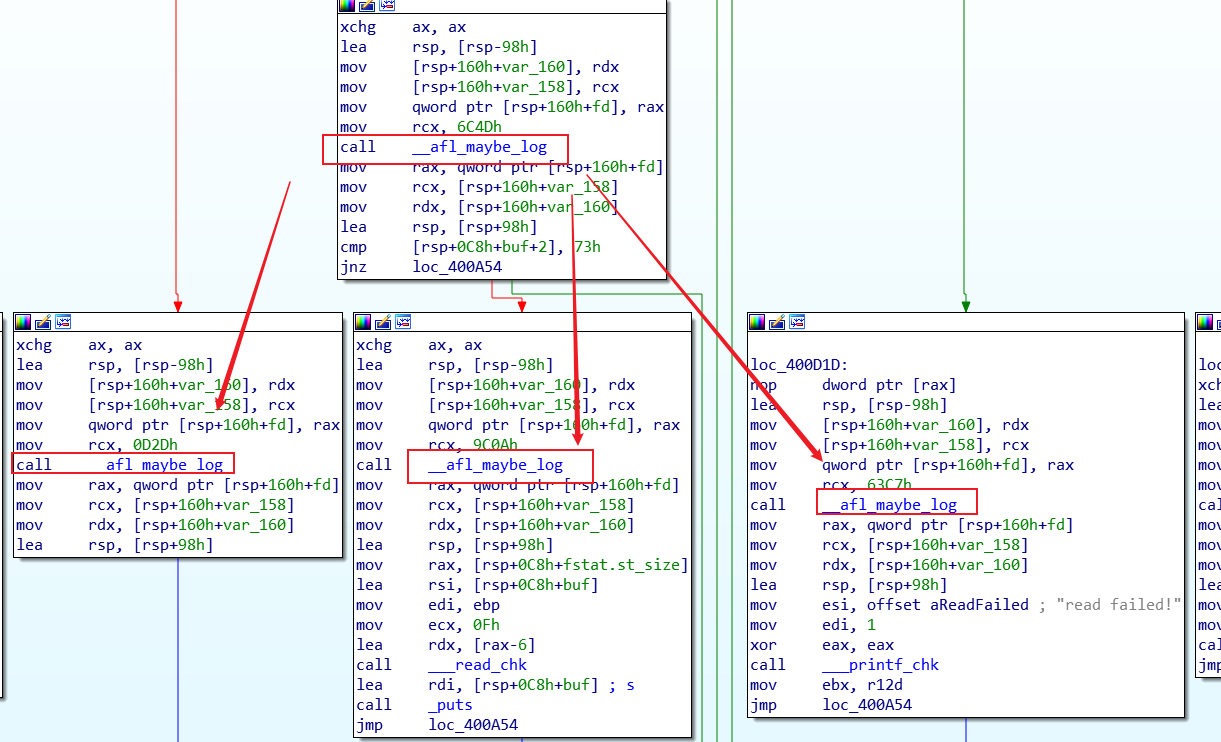
总结:afl-as 在汇编阶段,在每个基本块(不包括 intel 以及内联汇编)内插入 _afl_maybe_log 用于统计代码覆盖率。
0x20 fork server
源码经过插桩,每个基本块上已经具有标识符,就可以进行 fuzzing 了。fuzzer 要求在短时间内,运行多个目标程序,喂入变异后的测试用例,监测目标进程状态。如果频繁调用 execve() 系统调用,会消耗大量的系统资源

为了提高效率,afl-fuzz 在执行一个目标程序后,启动 fork server,由 fork server 负责 fork 进程,fuzzer 本身不负责 fork 进程的任务,fuzzer 通过管道,与 fork server 通信。这样做的好处是,fuzzer 不会频繁调用 execve,也不会进行载入目标文件和库、解析符号地址等重复性工作4。
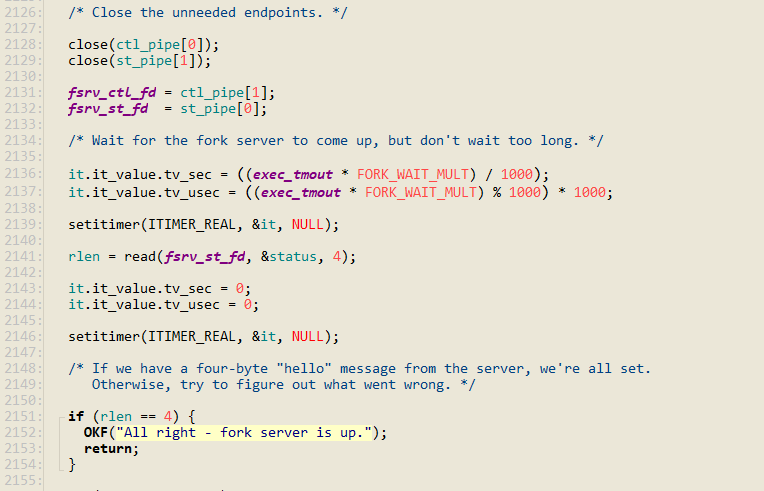
forksrv_pid = fork(); fuzzer fork 出一个子进程,此时,父进程为 fuzzer 本身,子进程就是 fork server。
int st_pipe[2], ctl_pipe[2]; 父子进程通过管道进行通信,这里定义了两个管道,一个用于传递状态,一个用于传输控制命令。
子进程即 fork server,初始化管道,并最终执行 execve() 目标程序

执行
execv(target_path, argv); 父进程读取管道的状态,判断是否 fork 成功
0x30 变异
AFL 维护了一个 testcases 队列,每次从队列中取出一个用例进行变异。主要有以下几种变异策略5
bitflip:按位翻转,每次都是比特位级别的操作,从 1bit 到 32bit ,从文件头到文件尾,会产生一些有意思的额外重要数据信息;arithmetic: 与位翻转不同的是,从 8bit 级别开始,而且每次进行的是加减操作,而不是翻转;interest: 把一些有意思的东西“interesting values”对文件内容进行替换;dictionary: 用户提供的字典里有token,用来替换要进行变异的文件内容,如果用户没提供就使用 bitflip 自动生成的 token;havoc: 进行很大程度的杂乱破坏,规则很多,基本上换完就是面目全非的新文件了;splice: 通过将两个文件按一定规则进行拼接,得到一个效果不同的新文件;
前 4 项属于非 dumb mode(-d) 和主 fuzzer(-M) 会进行的操作(dump 即 AFL 也支持无脑变异,即没有规律的变异),由于其变异方式没有随机性,所以也称为 deterministic fuzzing;havoc 和 splice 是随机的,是所有 fuzzing 都会进行的操作,无论是否是 dumb mode 或者主从 fuzzer,都会进行此步骤。
0x31 BITFLIP
根据翻转量/步长,按位翻转的策略有以下几种
- bitflip 1/1,每次翻转1个bit,按照每1个bit的步长从头开始
- bitflip 2/1,每次翻转相邻的2个bit,按照每1个bit的步长从头开始
- bitflip 4/1,每次翻转相邻的4个bit,按照每1个bit的步长从头开始
- bitflip 8/8,每次翻转相邻的8个bit,按照每8个bit的步长从头开始,即依次对每个byte做翻转
- bitflip 16/8,每次翻转相邻的16个bit,按照每8个bit的步长从头开始,即依次对每个word做翻转
- bitflip 32/8,每次翻转相邻的32个bit,按照每8个bit的步长从头开始,即依次对每个dword做翻转
自动检测 token
这一点,从源码来看,不是很容易理解,但是根据代码的注释很容易明白了
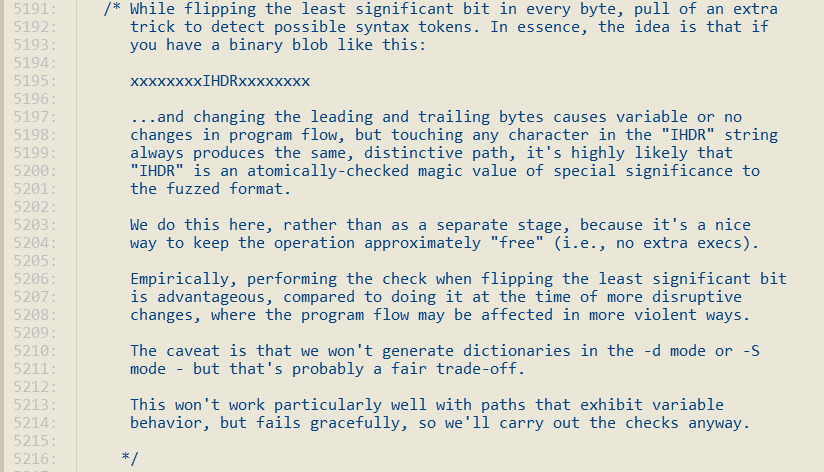
在执行 bitflip 1/1 时,如果连续翻转多个字节后的用例,都能让程序走到新的代码路径,那么就称连续翻转的字节是一个 token。举个例子,xxxxxxxxIHDRxxxxxxxx,任意改变 IHDR 四个字符中的一个,都会让程序走到新的分支,IHDR 就是一个神仙值 —— token
token 的长度和数量已经在头文件 config.h 中进行了预定义,如果想改变,只需要修改这些宏定义,重新编译源码
/* Maximum number of auto-extracted dictionary tokens to actually use in fuzzing (first value), and to keep in memory as candidates. The latter should be much higher than the former. */ #define USE_AUTO_EXTRAS 50 #define MAX_AUTO_EXTRAS (USE_AUTO_EXTRAS * 10) 生成 effector map
bitflip 8/8 的时候,多了一个 effector map,eff_map 长度为 EFF_ALEN(len),这里重点解释以下这个数组的作用,以及为什么出现在 bitflip 8/8

在进行位翻转的时候,翻转后的用例让程序执行到不同的路径,该 byte 就在 effector map 中,置为 1,代表本次翻转有效。否则,为 0 ,表示无效。这种做法的好处是,如果该 byte 的翻转不会带来执行路径的变化,那么该 byte 很有可能是 data,而非 size/length/flag 这样能够明显改变程序流程的参数。 随后的一些变异会参考 effector map,从而绕过一些无用的位,节省资源。
bitflip 8/8 以后会进行启发式判断,随后的变异也是基于 8/8,在此插入 effector map,效果可能会更好。
/* Minimum input file length at which the effector logic kicks in: */ #define EFF_MIN_LEN 128 /* Maximum effector density past which everything is just fuzzed unconditionally (%): */ #define EFF_MAX_PERC 90 dump mode 或者从 fuzzer 不会使用 effector map,默认情况下,如果文件小于128 bytes,那么所有字符都是“有效”的;同样地,如果AFL发现一个文件有超过90%的bytes都是“有效”的,那么也不差那10%了,大笔一挥,干脆把所有字符都划归为“有效”。
0x32 ARITHMETIC INC/DEC
位翻转之后,就开始进入 arithmetic,其实就是加减运算。与 bitflip 类似,arithmetic 也根据位长度和步长分为几个阶段
- arith 8/8,每次8bit进行加减运算,8bit步长从头开始,即对每个byte进行整数加减变异;
- arith 16/8,每次16bit进行加减运算,8bit步长从头开始,即对每个word进行整数加减变异;
- arith 32/8,每次32bit进行加减运算,8bit步长从头开始,即对每个dword进行整数加减变异
跳过 arithmetic 变异的情况
- 在 eff_map 数组中对byte进行了 0/1 标记,如果一个整数的所有 bytes 都被判为无效,那么就认为整数无效,跳过此数的变异;
- 如果加减某数之后效果与之前某bitflip效果相同,认为此次变异在上一阶段已经执行过,此次不再执行

0x33 INTERESTING VALUES
替换一些有趣的数据到原文件中
- interest 8/8,每次8bit进行加减运算,8bit步长从头开始,即对每个byte进行替换;
- interest 16/8,每次16bit进行加减运算,8bit步长从头开始,即对每个word进行替换;
- interest 32/8,每次32bit进行加减运算,8bit步长从头开始,即对每个dword进行替换

什么样的数据才算是有趣的数据呢?源码的 290~297 给出了答案
/* Interesting values, as per config.h */ static s8 interesting_8[] = {
INTERESTING_8 }; static s16 interesting_16[] = {
INTERESTING_8, INTERESTING_16 }; static s32 interesting_32[] = {
INTERESTING_8, INTERESTING_16, INTERESTING_32 }; 注释中也表明 Interesting values 预定义在 config.h 头文件中
/* List of interesting values to use in fuzzing. */ #define INTERESTING_8 \ -128, /* Overflow signed 8-bit when decremented */ \ -1, /* */ \ 0, /* */ \ 1, /* */ \ 16, /* One-off with common buffer size */ \ 32, /* One-off with common buffer size */ \ 64, /* One-off with common buffer size */ \ 100, /* One-off with common buffer size */ \ 127 /* Overflow signed 8-bit when incremented */ #define INTERESTING_16 \ -32768, /* Overflow signed 16-bit when decremented */ \ -129, /* Overflow signed 8-bit */ \ 128, /* Overflow signed 8-bit */ \ 255, /* Overflow unsig 8-bit when incremented */ \ 256, /* Overflow unsig 8-bit */ \ 512, /* One-off with common buffer size */ \ 1000, /* One-off with common buffer size */ \ 1024, /* One-off with common buffer size */ \ 4096, /* One-off with common buffer size */ \ 32767 /* Overflow signed 16-bit when incremented */ #define INTERESTING_32 \ -LL, /* Overflow signed 32-bit when decremented */ \ -, /* Large negative number (endian-agnostic) */ \ -32769, /* Overflow signed 16-bit */ \ 32768, /* Overflow signed 16-bit */ \ 65535, /* Overflow unsig 16-bit when incremented */ \ 65536, /* Overflow unsig 16 bit */ \ , /* Large positive number (endian-agnostic) */ \ /* Overflow signed 32-bit when incremented */ 这些有趣的数都是一些边界条件,很有可能造成溢出的数。注意:1、这里仍然需要使用 effector map 来判断当前字节是否需要变异;2、如果当前 interesting value 在之前的 bitflip、arithmetic 已经覆盖过,则不再变异。
0x34 DICTIONARY STUFF
此时已是deterministic fuzzing 的结尾,有以下几个阶段
- user extras (over),从头开始,将用户提供的tokens依次替换到原文件中
- user extras (insert),从头开始,将用户提供的tokens依次插入到原文件中
- auto extras (over),从头开始,将自动检测的tokens依次替换到原文件中
当设置了-x选项,用户在词典中设置的 token 才能在相应的子阶段中执行。自动检测的 tokens 是第一个阶段 bitflip 生成的。
0x35 RANDOM HAVOC
havoc,即 “浩劫”,此阶段正式进入随机阶段,多轮变异的组合,此阶段较为复杂,但是只要记住,这个阶段的变异十分庞大,结果也不可预知。
0x36 SPLICING
slice,拼接,故名思意,splice是将两个seed文件拼接得到新的文件,并对这个新文件继续执行 havoc 变异。
上述两个随机阶段,变异结果未知,随机性很强,所以,无需知道算法的细节,大概理解一下即可。
0x37 cycles
一波变异结束后的文件,会在队列结束后下一轮中继续变异下去。AFL状态栏右上角的 cycles done 意味着完成的循环数,每次循环是对整个队列的再一次变异,不过只有第一次 cycle 才会进行 deterministic fuzzing ,之后循环的只有随机性变异了。
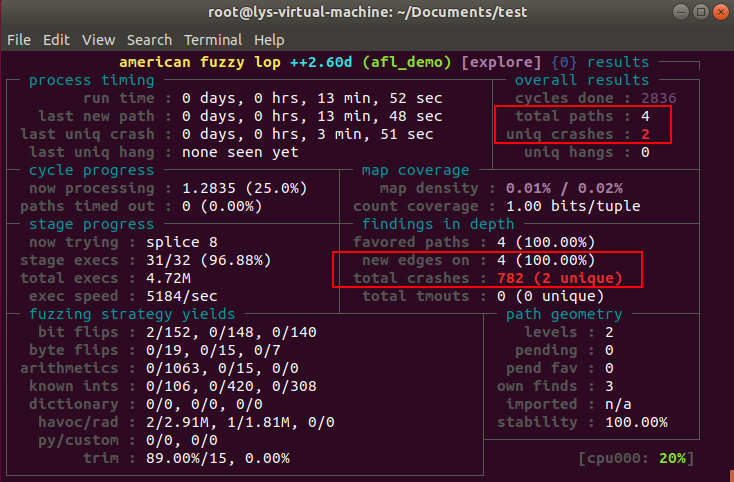
上图表明,已经完成 2836 次的变异循环了。
0x40 总结
AFL 作为 C/C++ 白盒 fuzzer 的鼻祖,为后来许多优秀的 fuzzer 提供了技术支持,衍生了很多 fuzzer 工具,本文只是站在巨人的肩膀上,参考了大量的博客,重新审计了部分源码,很多细节并没有深究,但对理解 AFL 的思想还是有一定作用的。从整个 AFL 的思想来看,其通过插桩计算代码覆盖率、测试用例的变异都是核心代码,变异策略会根据反馈进行动态调整,体现其强大的启发式思维,AFL 也有完全随机的变异,二者结合,也不奇怪为啥在此基础上衍生了那么多强大的 fuzzer 工具了。
- AFL源码分析笔记(一) https://xz.aliyun.com/t/4628 ↩︎
- AFL 的代码插桩问题 https://www.dazhuanlan.com/2019/12/09/5dee53eec54a3/) ↩︎
- AFL 源码码插桩分析 https://www.dazhuanlan.com/2020/03/04/5e5f13ab06638/ ↩︎
- AFL(American Fuzzy Lop)实现细节与文件变异 https://paper.seebug.org/496/ ↩︎
- 【AFL(五)】文件变异策略 https://www.cnblogs.com/wayne-tao/p/12019499.html ↩︎
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/231901.html原文链接:https://javaforall.net


