
DQN,Deep Q Network,是强化学习中一种强大的算法,Deep Mind团队凭借该算法,让计算机打败了人类围棋,刷新了人们对人工智能的认知。强烈推荐莫烦大神的强化学习入门课程,本文主要参考莫烦大神的课程进行总结。
论文:《Playing Atari with Deep Reinforcement Learning》https://arxiv.org/abs/1312.5602
参考代码:https://github.com/DiaoXY/DQN_tf
一、概述
现在的强化学习可以分为三类:policy gradient,value-base,Actor-Critic。其中DQN是value-base的代表,以DDPG为代表的Actor-Critic算法中既有value-base,也有policy网络。
Policy gradient的强化学习方法,通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动,每个动作都有可能被选择。value-base的强化学习方法输出的是所有动作的价值,选择最高价值对应的动作。对于连续动作空间,policy gradient可以利用一个概率分布在连续动作中选取特定动作,而value-base方法更适合离散动作空间。Actor-Critic方法结合了上述两种方法的优势,设定actor基于概率做出动作,critic会对做出的动作给出动作的价值,actor会根据critic给出的评分来修改行为的概率,加速了policy gradient的学习过程。
二、Q-Learning
2.1 Q-Learning决策过程
存在一张状态动作准则表Q值表,每次选择动作时,参照该表来选择某状态下对应Q值最大的动作即可。例如下表,假设我们现在处在状态S1,动作a2的价值要比a1高,所以我们做出判断,选择动作a2,执行完动作a2后我们处在状态S2,重复上面的操作,选择S2对应Q值最大的动作,重复上述决策过程。
| 状态/动作 | a1 | a2 | 。。。 |
| S1 | -1 | 2 | 。。。 |
| S2 | 2 | 4 | 。。。 |
| 。。。 | 。。。 | 。。。 | 。。。 |
2.2 Q-Learning的更新
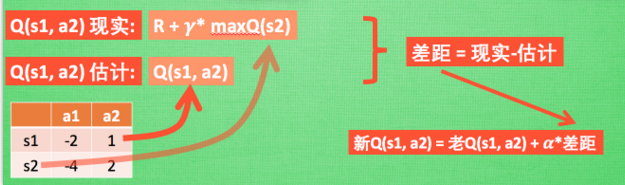
在上述过程中,处在状态S1时,由于Q(s1,a2)大于Q(s1,a1),所以执行动作a2后,获得对应的奖励 R,此时处于状态s2,这时开始更新用于决策的Q表,这个过程中我们并没有在实际中采取任何行为, 而是再想象自己在 s2 上采取了每种行为, 分别看看两种行为哪一个的 Q 值大, 比如说 Q(s2, a2) 的值比 Q(s2, a1) 的大, 所以我们把大的 Q(s2, a2) 乘上一个衰减值 gamma (比如是0.9) 并加刚刚到达状态S2时的奖励 R , 我们将这个{R+gamma*Q(s2,a2)}作为我现实中 Q(s1, a2) 的值, 但是我们之前是根据 Q 表估计 Q(s1, a2) 的值. 所以有了现实和估计值, 我们就能更新Q(s1, a2) , 根据 估计与现实的差距, 将这个差距乘以一个学习效率 alpha 累加上老的 Q(s1, a2) 的值 变成新的值{新Q(s1,a2)=老Q(s1,a2)+alpha*(现实与估计的差距)}. 但时刻记住, 我们虽然用 maxQ(s2) 估算了一下 s2 状态, 但还没有在 s2 做出任何的行为, s2 的行为决策要等到更新完了以后再重新另外做. 这就是 off-policy 的 Q learning 是如何决策和学习优化决策的过程.。

三、DQN算法
DQN是一种结合神经网络和Q-Learning的算法。在原始的Q-Learning方法中,采用表格的形式来存储每个状态对应各个动作的Q值,记为Q(s,a),如果所有的Q值都应采用表格的形式保存的话,那是一件非常耗时且占用内存的事情。所以我们希望通过函数的形式来计算Q值,因此采用机器学习中神经网络来完成Q值的计算,将状态和动作作为神经网络的输入,经过神经网络分析就可以得到该状态下的每个动作对应的Q值,然后按照Q-Learning方法的决策原则,选择拥有最大Q值的动作作为下一步的动作。
3.1 DQN中的神经网络训练
强化学习不同于深度学习中,有大量带有“正确答案”的标签的样本,所以在训练神经网络时,只能通过Q-Learning方法的reward来构造“标签”。采用双网络的结构,一个估计网络(当前训练的网络)产生当前Q值,即Q估计;一个目标网络产生目标Q值,即Q现实。则神经网络的目标就是使得Q现实与Q估计的差值最小。
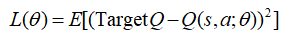
其中表示估计网络中的网络参数,表示估计网络中当前状态s的Q估计值,TargetQ表示目标网络中的目标Q值,计算如下
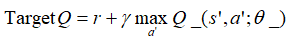
_表示目标网络参数,TargetQ表示目标网络产生的Q值,s’表示下一个状态,a’表示s’状态下对用最大Q值的动作。TargetQ对应的“标签”中的正确值,其实目标网络和估计网络的结构完全一样,不过蚕食更新速度不一样,目标网络中参数要比估计网络中的参数“旧”一点。通过Loss Function来训练更新当前网络,也就是估计网络的参数,经过N次迭代之后,将估计网络中的参数复制到目标网络中,因此目标网络在一段时间内的网络参数不会发生改变,可以有效地降低估计Q值与目标Q值的相关性,提高算法的收敛性。
3.2 Experience replay经验回放机制
DQN算法是一种off-policy的离线算法,可以学习过去经历过的经验。DQN设置了一个经验池,用于存放过期经历的一系列的状态、动作、奖励值和下一个状态,在每次DQN网络更新时,通过随机抽取(minibatch)的方式进行学习,不仅可以打乱经历间的相关性,还可以提高学习效率。
2013版DQN算法如下

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/233091.html原文链接:https://javaforall.net

![divmod的使用[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
