
多模态(Multimodal) AI 大模型的是指能够处理和理解多种不同类型(模态)数据的人工智能模型。 这些模型能够从不同来源的输入中获取信息,并通过综合这些信息来做出更全面、更准确的判断和预测。常见的模态包括:
- 文本: 书面或口头语言。
- 图像: 照片、图画、图标等。
- 音频: 声音、音乐、语音。
- 视频: 动态图像序列,通常包含音频。
- …
多模态的 AI 大模型能够将这些不同模态的数据进行融合处理。例如,能够理解图像中的内容并结合文本信息生成描述,或者结合语音和图像来识别视频中的对千问 Qwen 教程象或场景。
多模态 AI 大模型的核心能力与特点如下:
1、跨模态理解与关联: 这是最核心的能力。模型不仅能理解每种模态内部的信息,更能理解不同模态信息之间的关联。例如:
- 理解一张图片描绘的内容,并用文字描述出来(看图说话)。
- 根据一段文字描述,生成符合描述的图像(文生图)。
- 理解视频中发生了什么,并回答相关问题(视频问答)。
- 分析医学影像(图像模态)并结合病历报告(文本模态)做出诊断建议。
- 理解语音指令(音频模态)并操控智能家居设备(可能需要关联传感器模态)。
2、跨模态生成: 模型可以基于一种模态的信息,生成另一种模态的内容。例如:
- 文生图:输入文字描述,生成图片。
- 图生文:输入图片,生成描述、故事或回答问题。
- 文生视频:输入文字描述,生成短视频。
- 语音合成:输入文字,生成逼真的语音(文生音频)。
- 音乐生成:根据描述或情绪生成音乐。
3、信息互补与增强: 不同模态的信息可以相互补充,提供更全面、更准确的理解。例如,一段视频配上文字解说,理解起来比单独看视频或单独看文字更清晰。多模态模型能自动利用这种互补性。
4、更接近人类感知世界的方式: 人类天生就是多模态的。我们通过眼睛看(图像/视频)、耳朵听(音频)、嘴巴说和阅读(文本)等多种方式来感知和理解世界。多模态大模型的目标就是模拟这种更自然、更全面的感知和理解方式。
为了能够上手感受一下,我们登录到阿里百炼 的 “模型广场” 中,找一款多模态 AI 大模型,我这里挑选的是 “全模态 | 通义千问-Omni-Turbo” 模型,如下图所示,Qwen-Omni 系列模型支持输入多种模态的数据,包括视频、音频、图片、文本,并输出音频与文本,而且它兼容 OpenAI 接口调用方式。
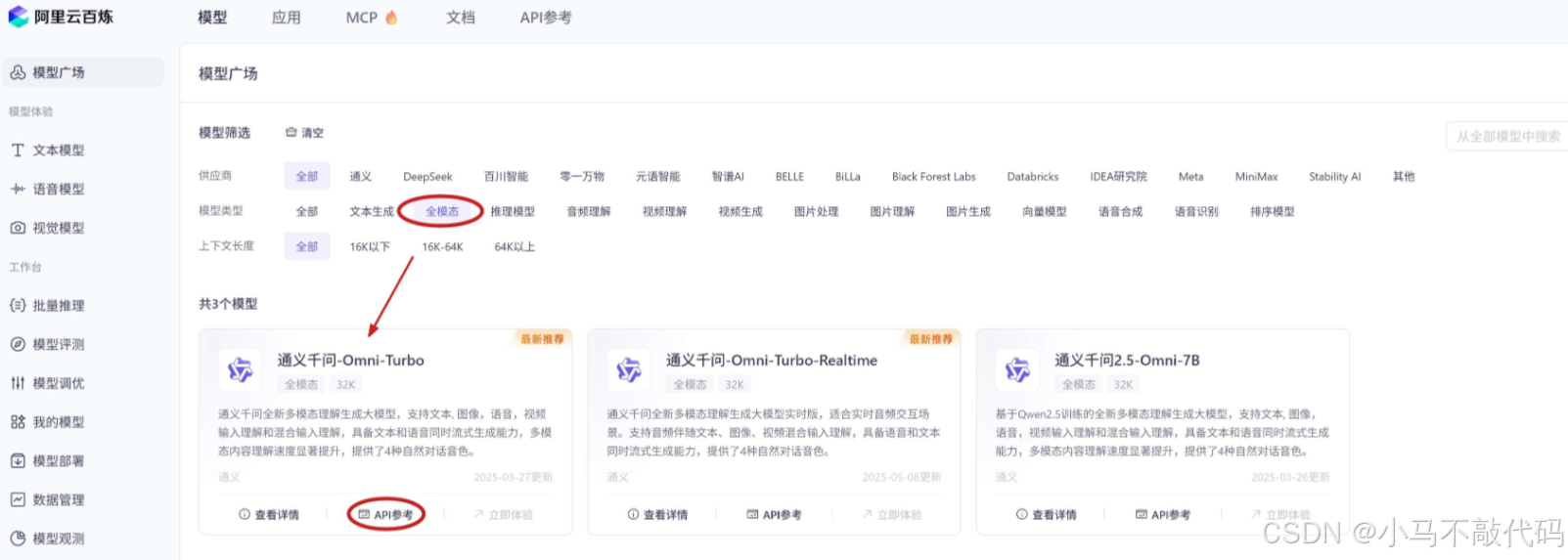

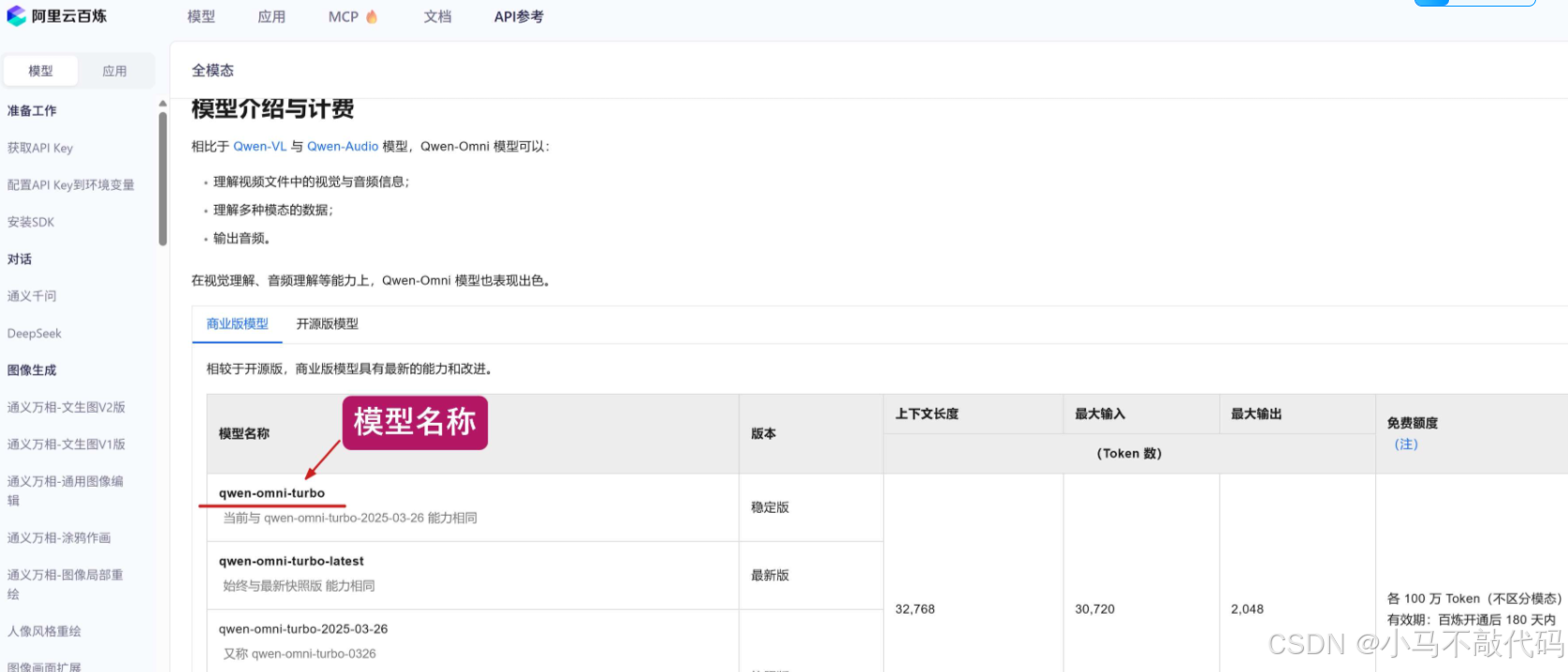
点击 “API参考”,查看模型文档,复制其模型名称 qwen-omni-turbo :
此配置对接的是阿里的百练大模型 (支持openai )
增加依赖
编辑 application.yml 文件,编辑 openai 节点下的模块名称,将其修改为 qwen-omni-turbo :
解释一下上述代码的处理流程:
- 创建一个 Media 媒体资源,声明其类型为 png 图片,并指定资源所在路径;
- 创建一个附加选项 Map 字典,比如指定 temperature 温度值,这是可选的,可以不添加任何参数;
- 构建 UserMessage 多模态消息,包括提示词、输入的图片等等;
- 构建 Prompt 构建提示词;
- 流式调用 qwen-omni-turbo 模型,注意,此模型只支持流式调用,不支持同步调用;
发布者:Ai探索者,转载请注明出处:https://javaforall.net/257788.html原文链接:https://javaforall.net


