
我们正式发布并开源 千问 Qwen 教程 Qwen3-VL!这是千问家族目前最强大的视觉语言模型,整体能力接近 Gemini-2.5-Pro,并在多个方向实现部分超越。
✨能力亮点:
视觉智能体(Visual Agent):Qwen3-VL 能操作电脑和手机界面:识别 GUI 元素、理解按钮功能、调用工具、执行任务,在 OS World 等 benchmark 上达到世界顶尖水平。
视觉 Coding 能力大幅提升:实现图像生成代码以及视频生成代码,例如看到设计图,能自动代码生成 http://Draw.io 图表,甚至输出完整的 HTML/CSS/JS 代码,真正实现“所见即所得”的视觉编程。
空间感知能力大幅提升:支持判断物体方位、视角变化、遮挡关系,能实现 3D grounding,为复杂场景下的空间推理和具身场景打下基础。
长上下文支持:全系列模型原生支持 256K token 的上下文长度,并可扩展至 100 万 token。这意味着,无论是几百页的技术文档、整本教材,还是长达数小时的会议录像或教学视频,都能完整输入、全程记忆、精准检索。
超长视频理解:不仅能理解长达两小时的视频内容,还能根据时间戳精确定位“什么时候发生了什么”,并支持连续帧中对物体的追踪与行为分析。
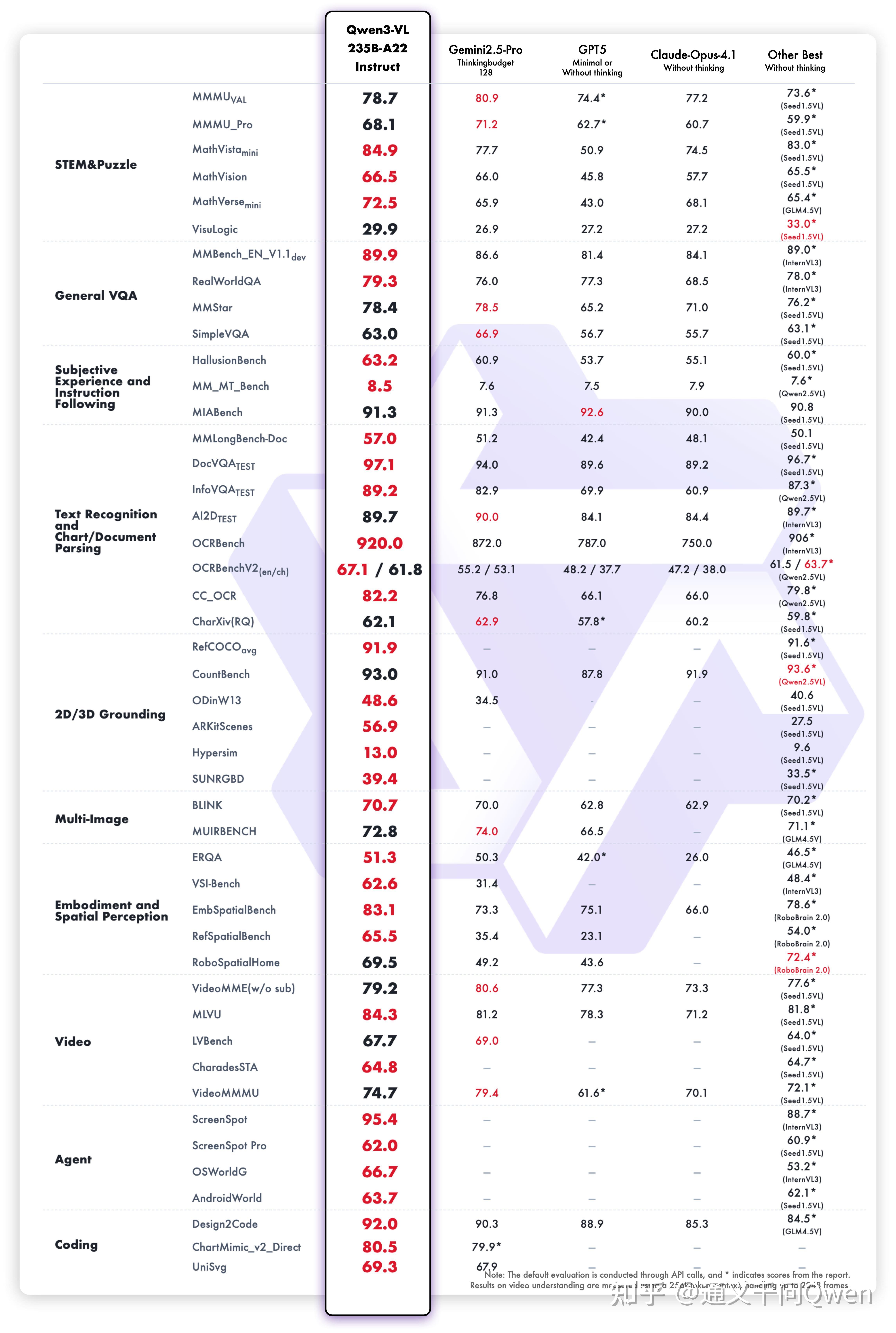
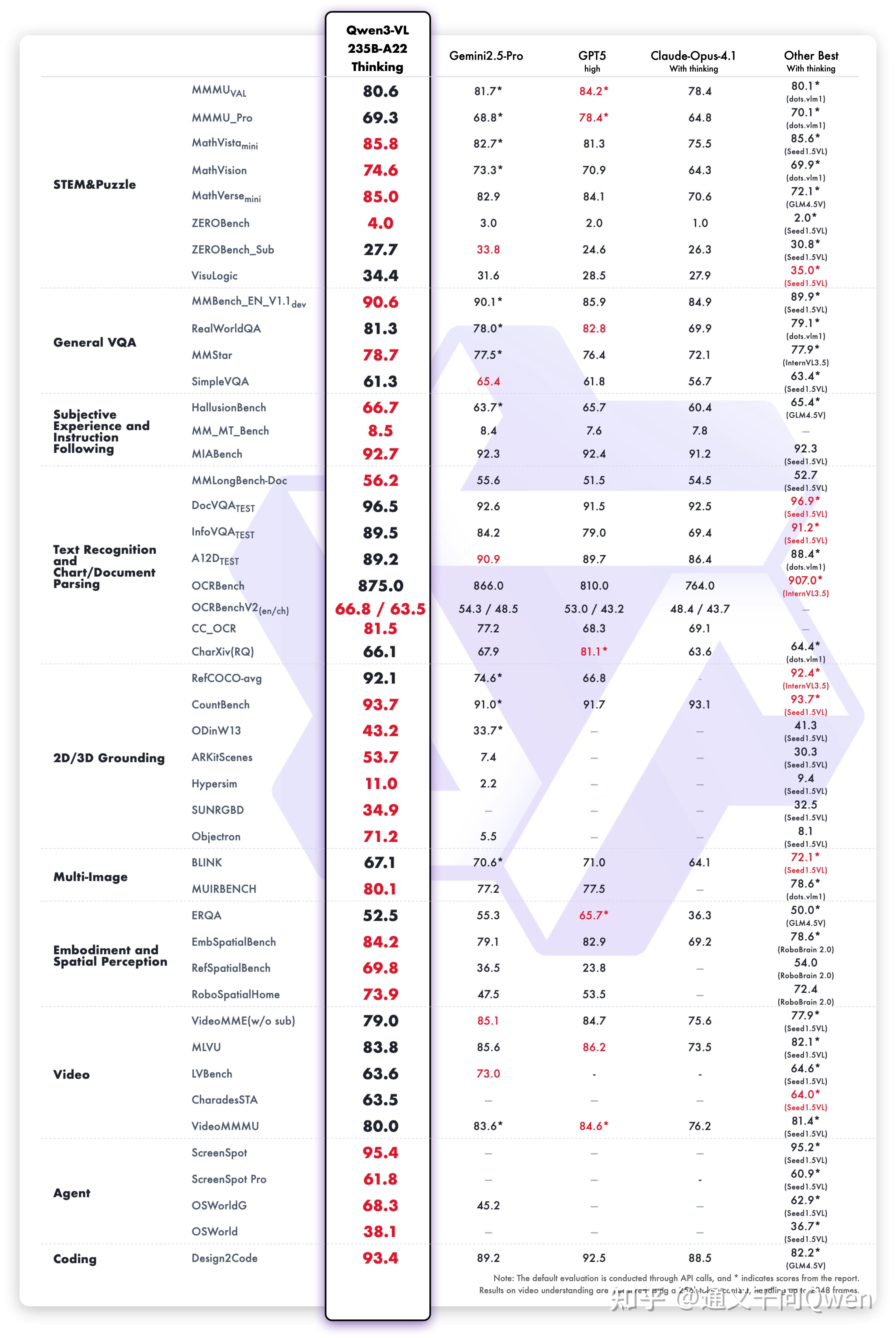
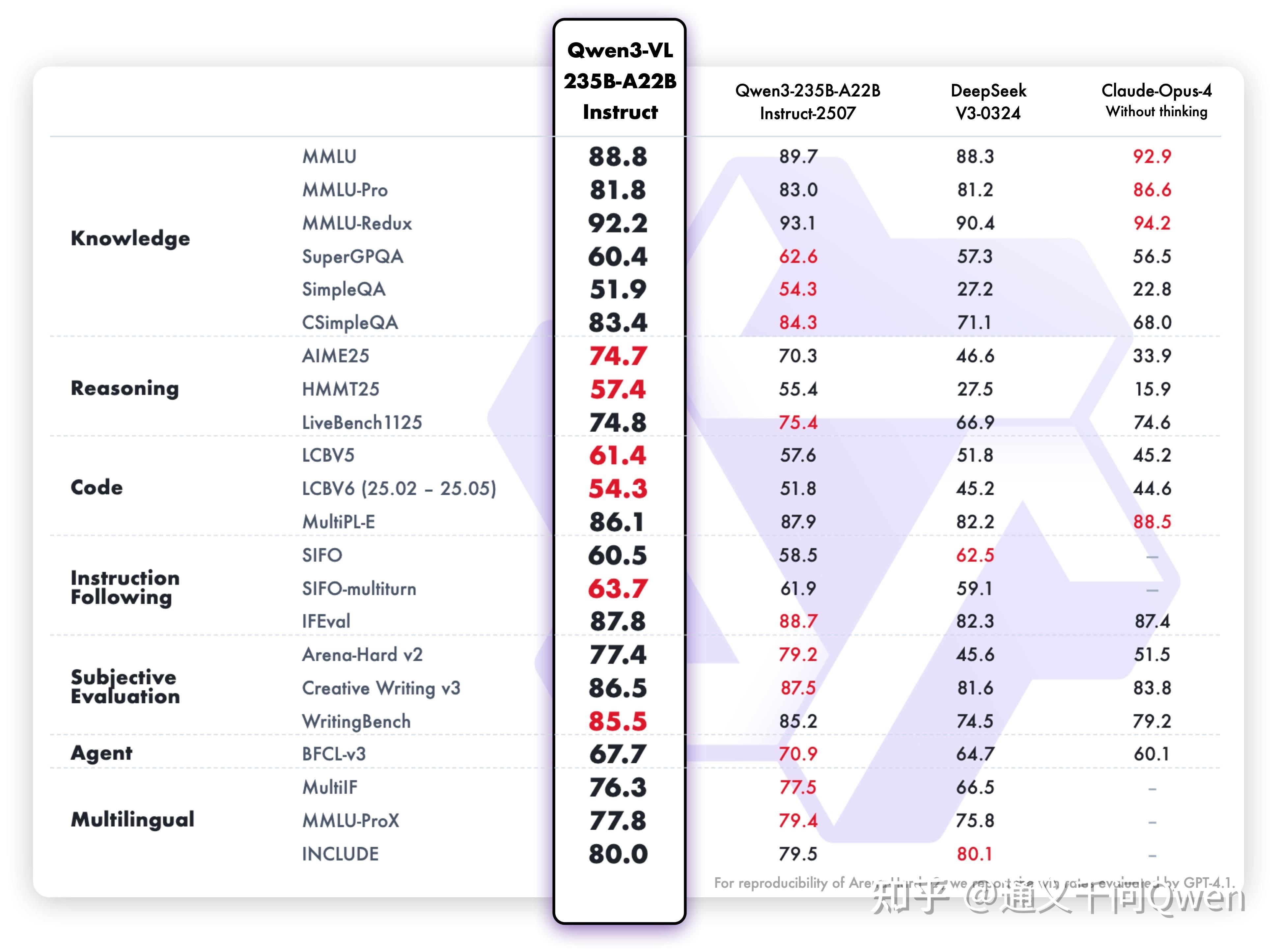
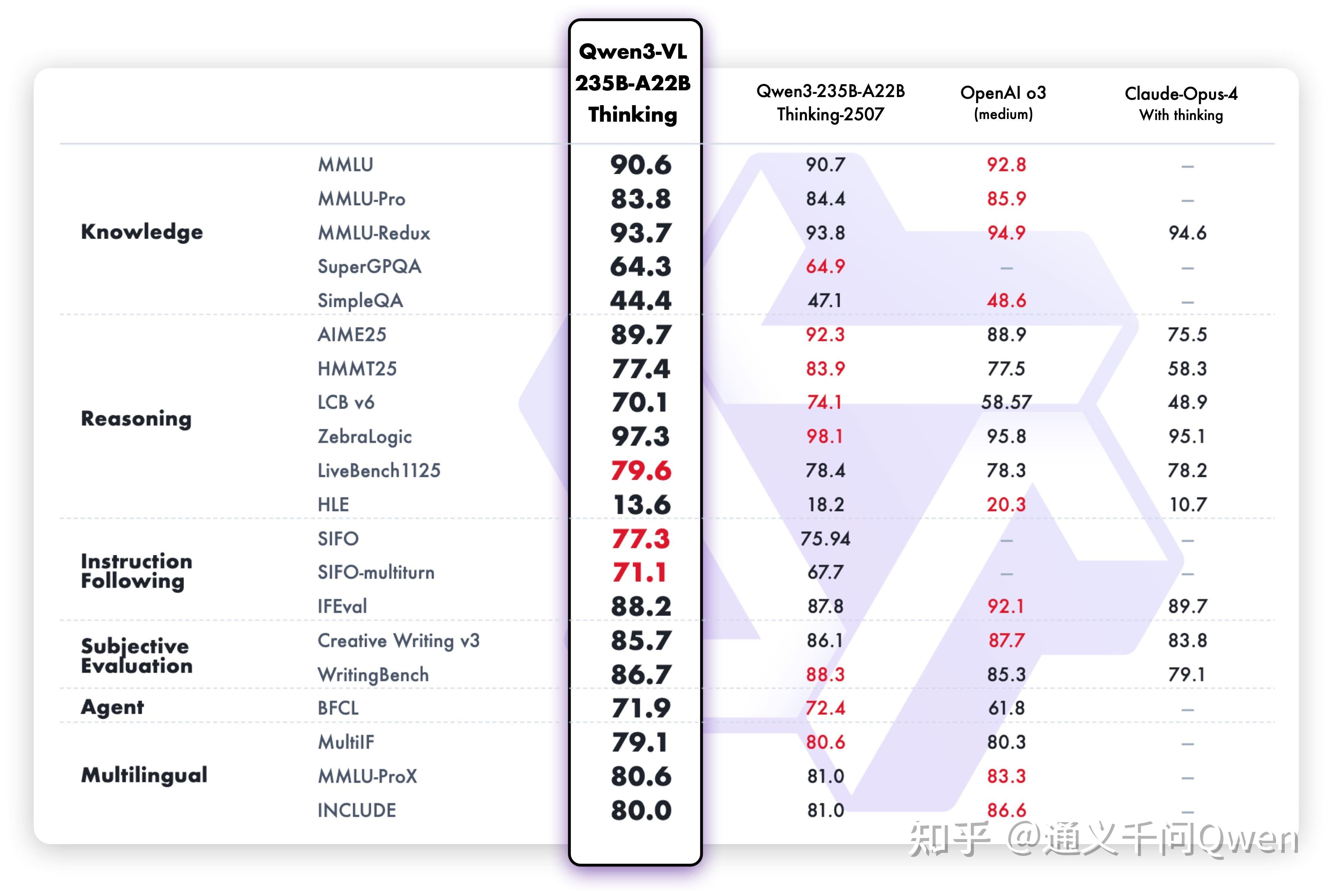
多模态思考能力显著增强:Thinking 模型重点优化了 STEM 与数学推理能力,在 MathVista、MathVision、CharXiv 等权威评测中达到 SOTA 水平。
视觉感知与识别能力全面升级:识别更丰富的对象类别,从名人、动漫角色、商品、地标,到动植物等,覆盖日常生活与专业领域的“万物识别”需求。
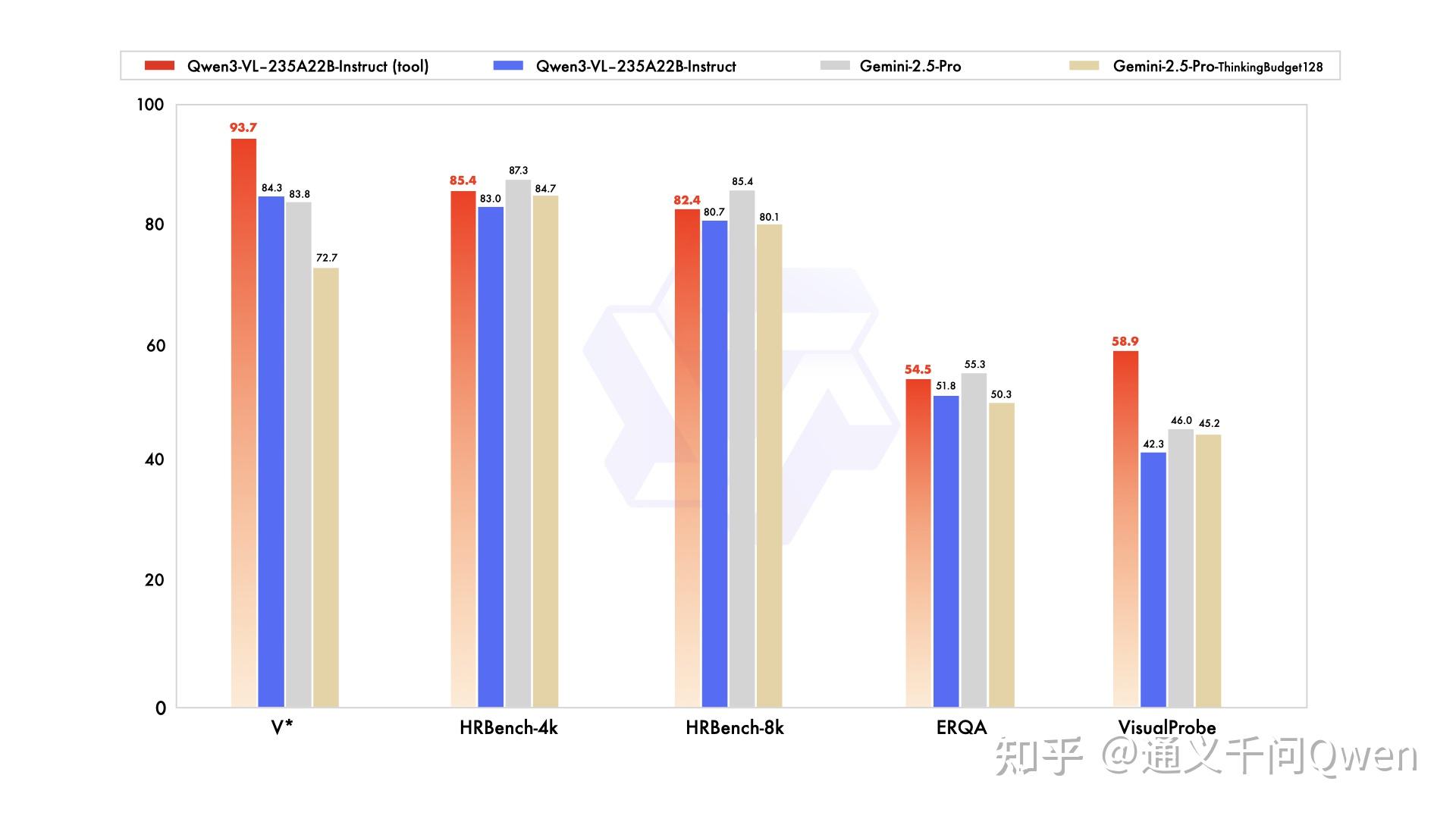
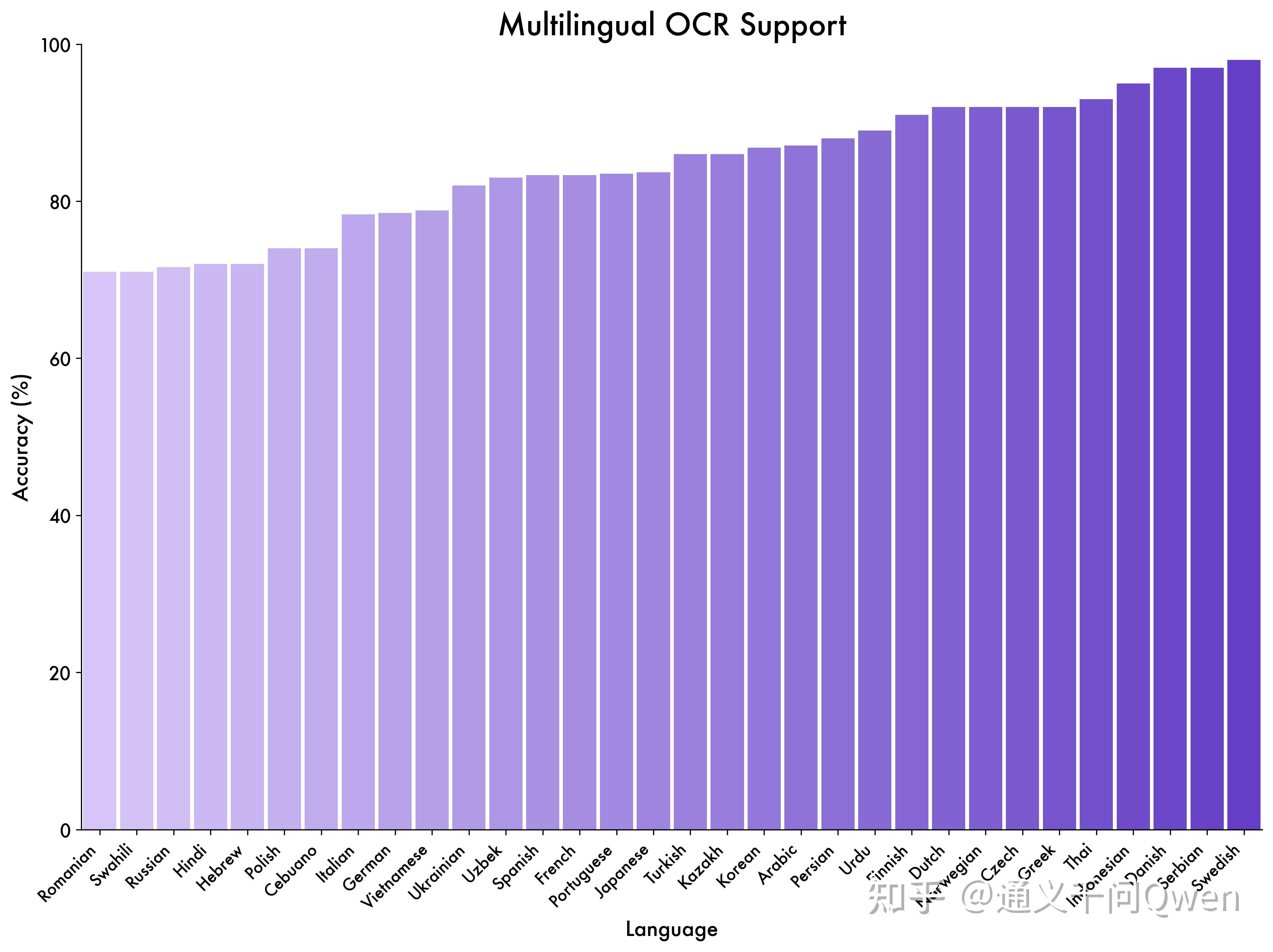
OCR 能力重大升级:支持语言从 19 种扩展到 32 种;在复杂光线、模糊、倾斜等实拍挑战性场景下表现更稳定;对生僻字、古籍字、专业术语的识别准确率显著提升;超长文档理解和精细结构还原能力进一步提升。

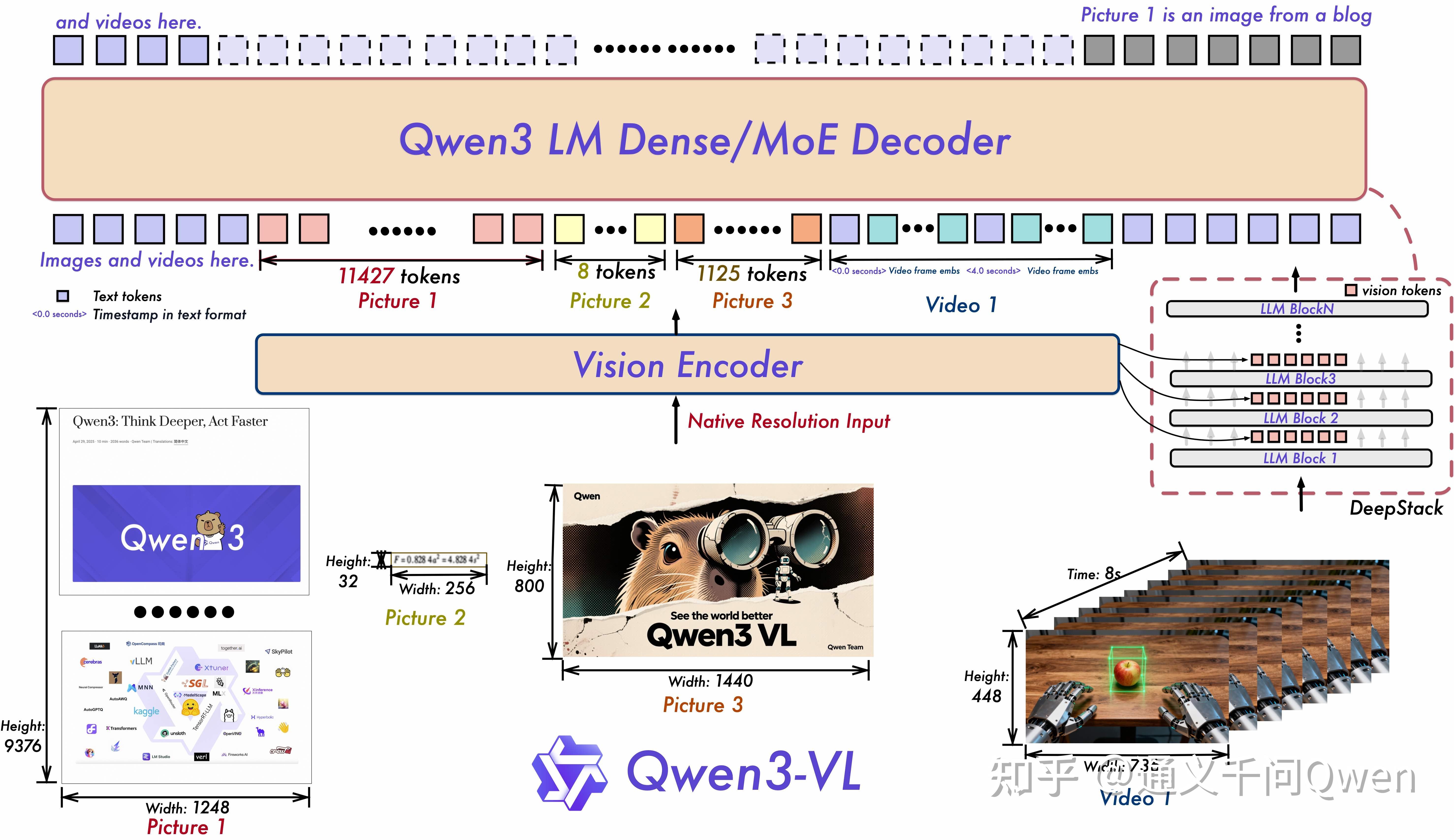
Qwen3-VL,正在从“感知”走向“认知”,从“识别”迈向“推理与执行”。
📍 Qwen3-VL 已在 Hugging Face、ModelScope、DashScope 和 GitHub 上线,也欢迎大家前往QwenChat直接体验!
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/259087.html原文链接:https://javaforall.net


