
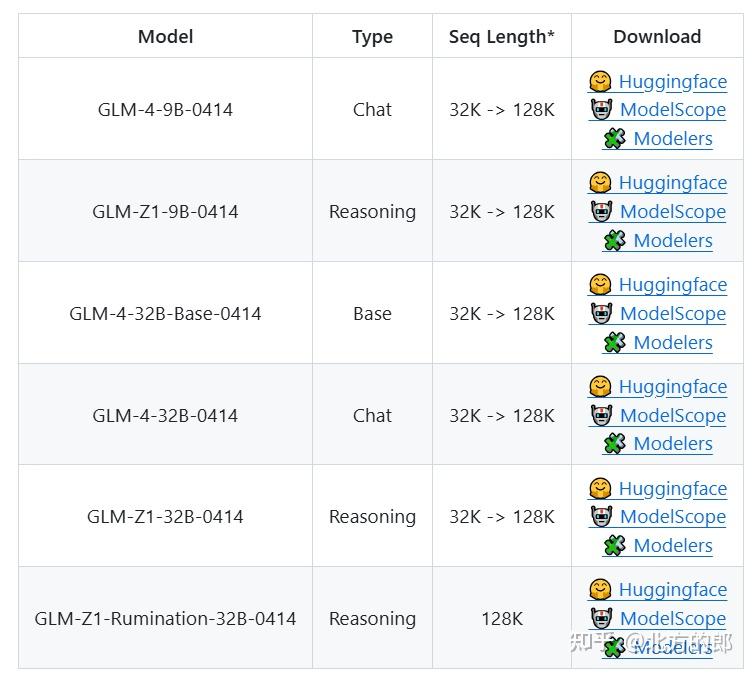
GLM 家族迎来新一代开源模型 GLM-4-32B-0414 系列,320 亿参数,效果比肩 OpenAI 的 GPT 系列和 DeepSeek 的 V3/R1 系列,且支持非常友好的本地部署特性。
GitHub:GitHub – THUDM/GLM-4: GLM-4 series: Open Multilingual Multimodal Chat LMs | 开源多语言多模态对话模型
GLM-4-32B-Base-0414 经过 15T 高质量数据的预训练,其中包含大量推理类的合成数据,这为后续的强化学习扩展打下了基础。在后训练阶段,除了针对对话场景进行了人类偏好对齐外,研究团队还通过拒绝采样和强化学习等技术强化了模型在指令遵循、工程代码、函数调用方面的效果,加强了智能体任务所需的原子能力。
GLM-4-32B-0414 在工程代码、Artifacts 生成、函数调用、搜索问答及报告等方面都取得了不错的效果,部分 Benchmark 甚至可以媲美更大规模的 GPT-4o、DeepSeek-V3-0324(671B)等模型。
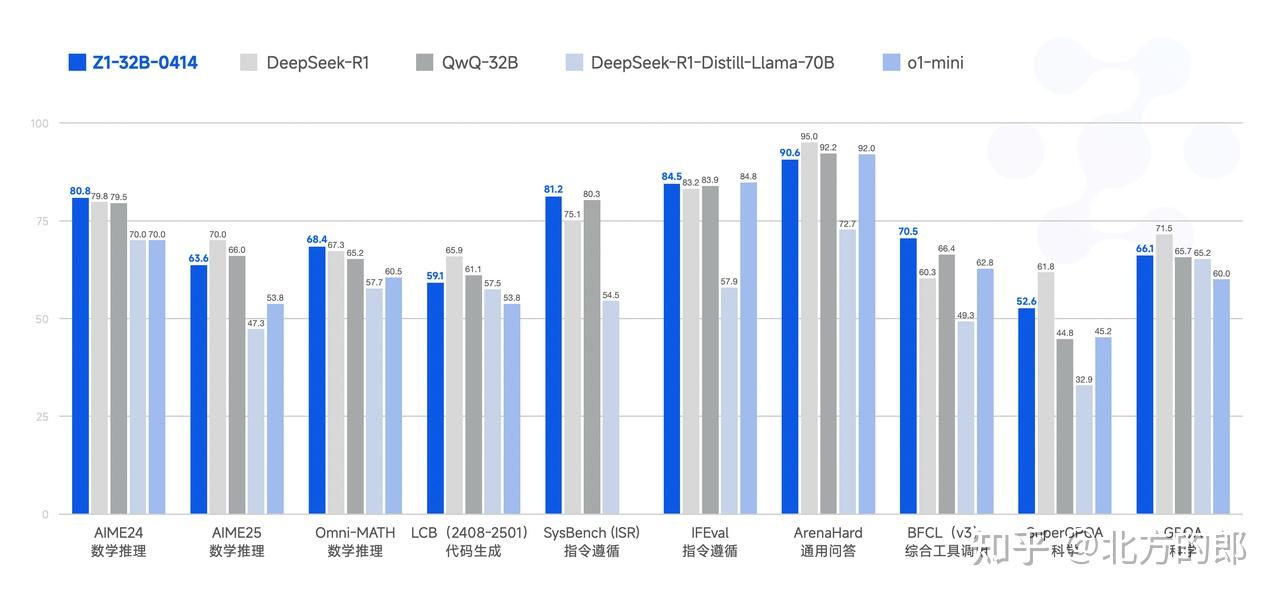
GLM-Z1-32B-0414 是具有深度思考能力的推理模型,这是在 GLM-4-32B-0414 的基础上,通过冷启动和扩展强化学习,以及在数学、代码和逻辑等任务上对模型的进一步训练得到的。相对于基础模型,GLM-Z1-32B-0414 显著提升了数理能力和解决复杂任务的能力。在训练的过程中,还引入了基于对战排序反馈的通用强化学习,进一步增强了模型的通用能力。
GLM-Z1-Rumination-32B-0414 是具有沉思能力的深度推理模型(对标 Open AI 的 Deep Research)。不同于一般的深度思考模型,沉思模型通过更长时间的深度思考来解决更开放和复杂的问题(例如:撰写两个城市AI发展对比情况,以及未来的发展规划),沉思模型在深度思考过程中结合搜索工具处理复杂任务,并经过利用多种规则型奖励来指导和扩展端到端强化学习训练得到。Z1-Rumination 在研究型写作和复杂检索任务上的能力得到了显著提升。
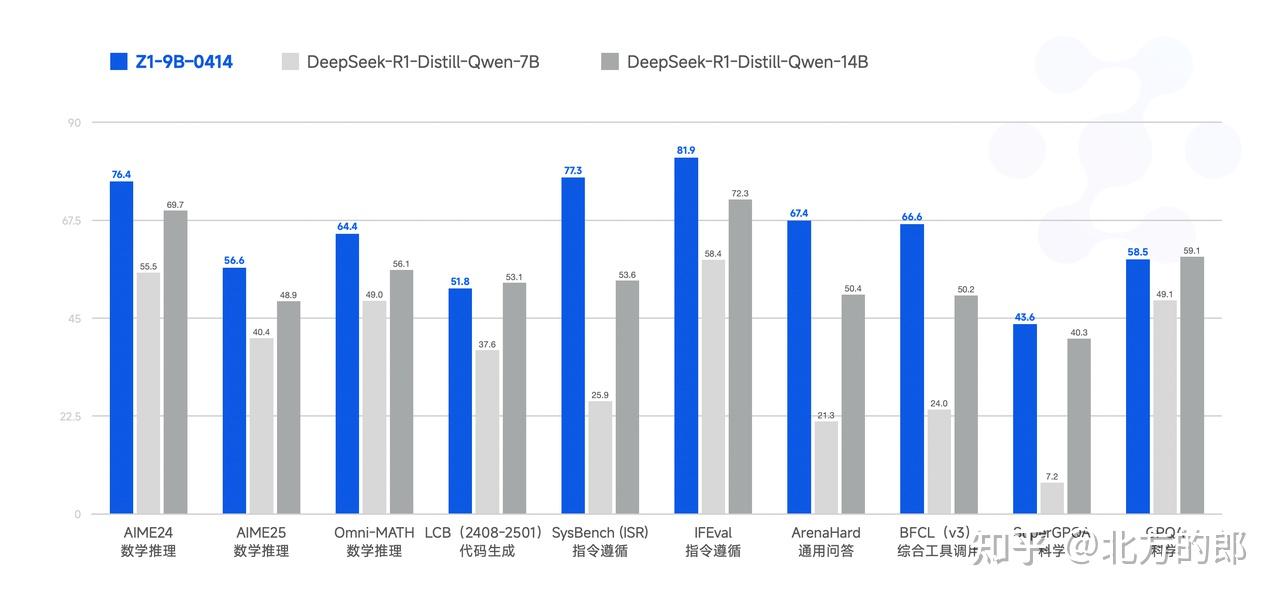
GLM-Z1-9B-0414 研究团队沿用上述一系列技术,训练了一个保持开源传统的 9B 小尺寸模型。尽管规模更小,GLM-Z1-9B-0414 在数学推理和通用任务中依然展现出极为优秀的能力,其整体表现已处于同尺寸开源模型中的领先水平。特别是在资源受限的场景下,该模型在效率与效果之间实现了出色的平衡,为追求轻量化部署的用户提供了强有力的选择。
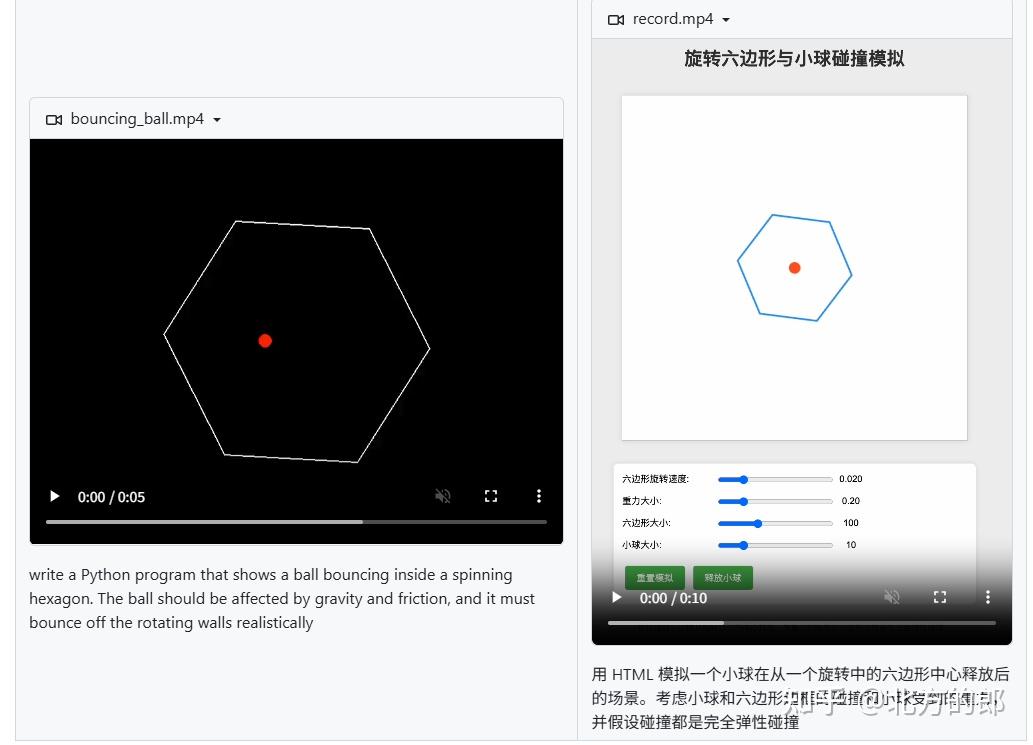

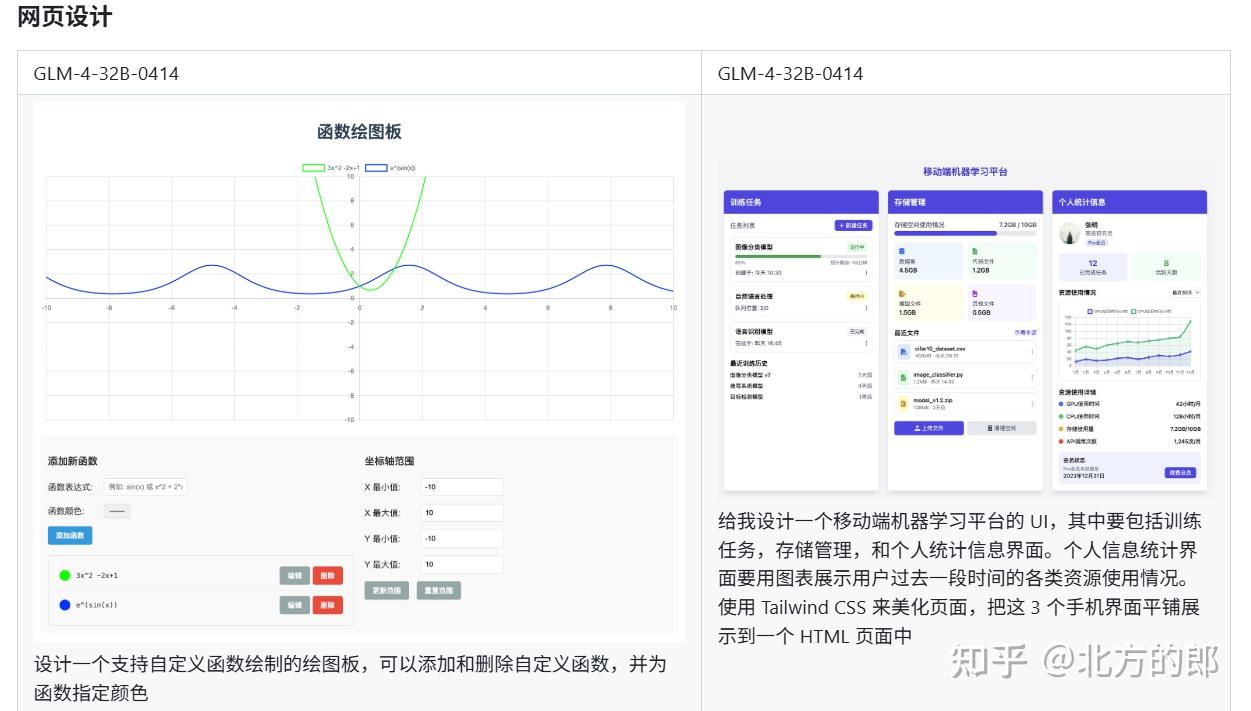
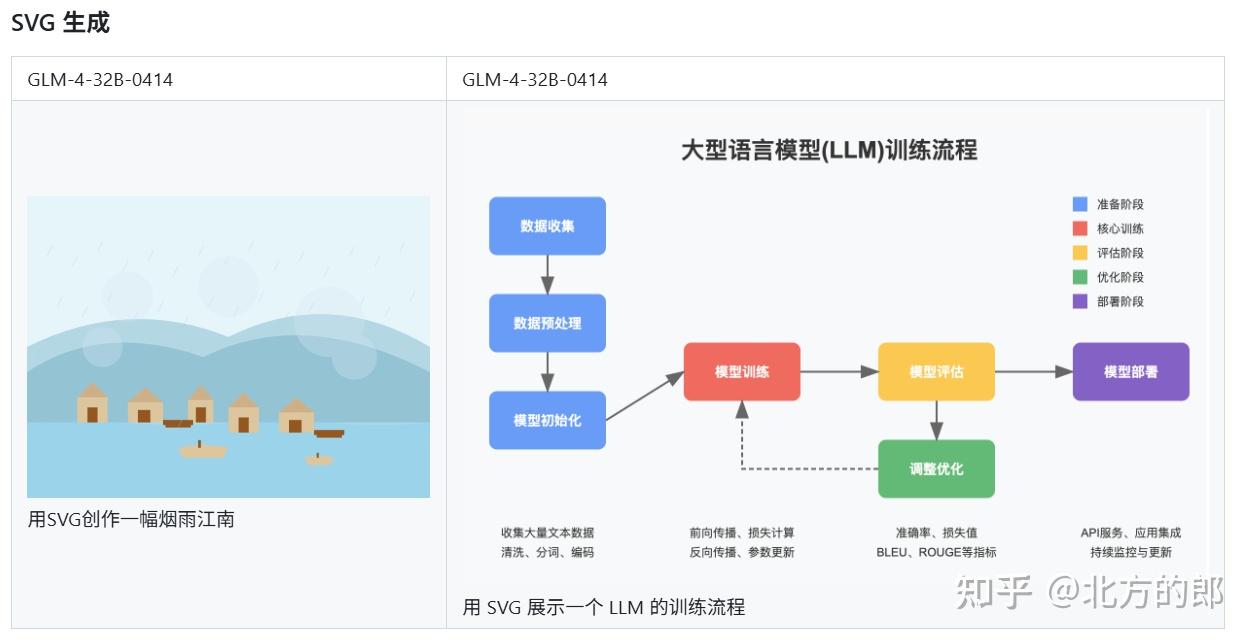
GLM-4-9B-0414 由于其较小的模型容量,未对其智能体能力进行类似 GLM-4-32B-0414 的强化,主要针对翻译等需要大批量调用的场景进行优化。
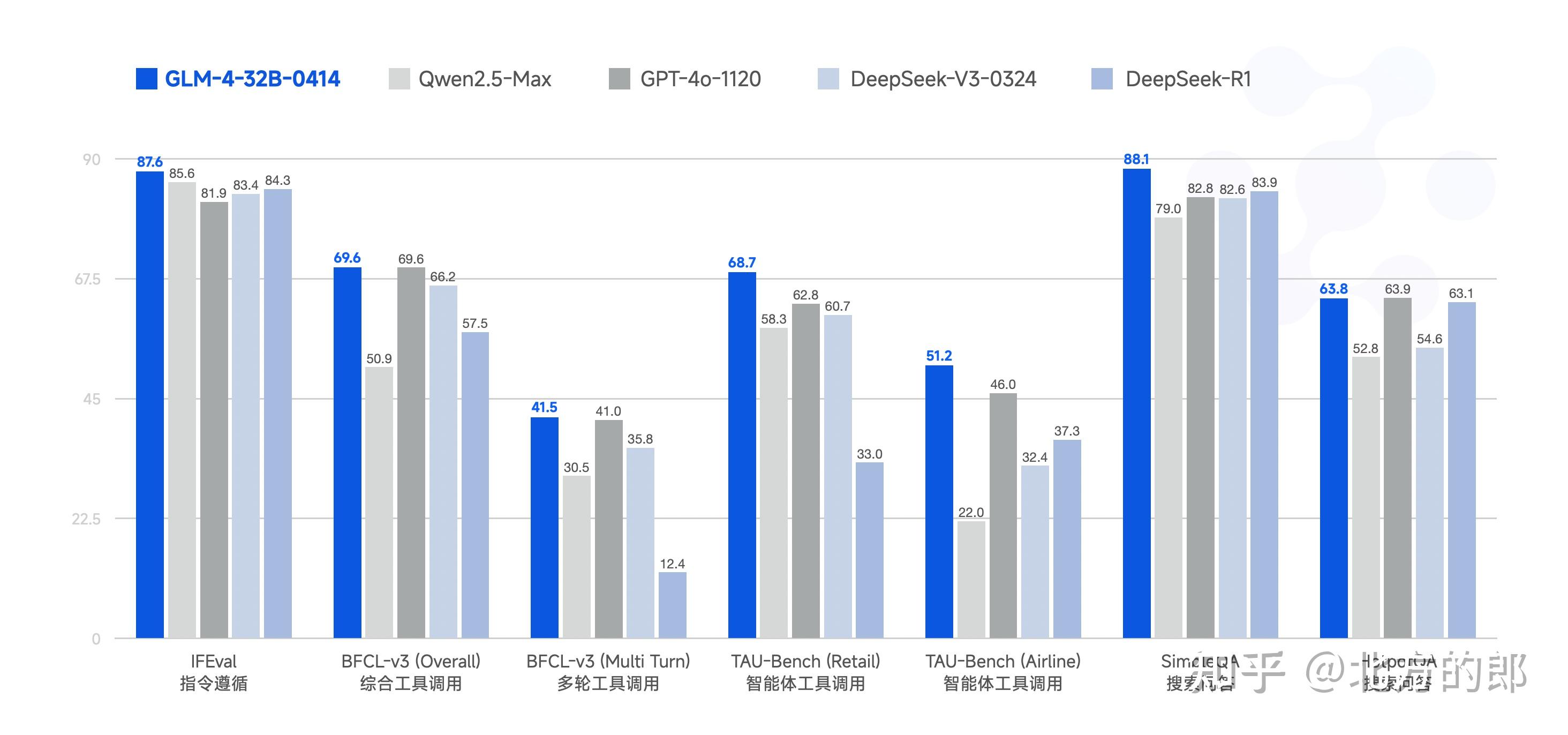
| 模型 | IFEval | BFCL-v3 (Overall) | BFCL-v3 (MultiTurn) | TAU-Bench (Retail) | TAU-Bench (Airline) | SimpleQA | HotpotQA |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Max | 85.6 | 50.9 | 30.5 | 58.3 | 22.0 | 79.0 | 52.8 |
| GPT-4o-1120 | 81.9 | 69.6 | 41.0 | 62.8 | 46.0 | 82.8 | 63.9 |
| DeepSeek-V3-0324 | 83.4 | 66.2 | 35.8 | 60.7 | 32.4 | 82.6 | 54.6 |
| DeepSeek-R1 | 84.3 | 57.5 | 12.4 | 33.0 | 37.3 | 83.9 | 63.1 |
| GLM-4-32B-0414 | 87.6 | 69.6 | 41.5 | 68.7 | 51.2 | 88.1 | 63.8 |
对于
SimpleQA和
HotpotQA,分别从测试集中采样了近500条测试样例,提供所有模型最基础的
search和
click工具,另外确保其余 Setting 保持一致后,3次评测取平均值
| 模型 | 框架 | SWE-bench Verified | SWE-bench Verified mini |
|---|---|---|---|
| GLM-4-32B-0414 | Moatless[1] | 33.8 | 38.0 |
| GLM-4-32B-0414 | Agentless[2] | 30.7 | 34.0 |
| GLM-4-32B-0414 | OpenHands[3] | 27.2 | 28.0 |
[1] Moatless v0.0.3 使用如下参数 response_format="react", thoughts_in_action=False, max_interations=30,未对失败轨迹进行重试,其余为默认配置
[2] Agentless v1.5.0 其中的 Embedding 模型使用了 BGE,基于FAISS进行相似性检索,为加快patch验证的速度同时尽可能保证效果,将运行单个实例的超时时间从默认的300s修改为180s
[3] OpenHands v0.29.1 未采用 YaRN 上下文扩展,而是限制了最大 60 个 iterations,并对 history 进行 summarization 以防止超出 32K 上下文限制,summarization 配置为 llm_config="condenser", keep_first=1, max_size=32,同样未对失败轨迹进行重试
如果你使用transformers库提供的apply_chat_template方法构建提示词。以下是对不同 GLM-4-0414 模型中 系统提示词的限制。
GLM-4-32B-Base-0414: 基座模型,无对话模板。GLM-4-*-0414/GLM-Z1-*-0414: 如果传入tools,则由 智谱 AI GLM 教程apply_chat_template填充工具到chat_template中的固定模板,单独作为一条带有tools绑定的system字段信息并拼接于messages[0]。原本传入的所有messages自动往后移动一个位置。GLM-Z1-Rumination-32B-0414:- 不支持自定义系统提示词,不支持自定义工具,你的所有
tools和system字段会被apply_chat_template忽略。使用该模型需要外接搜索引擎或者自定义retrieval API。 - 一共支持四个工具,分别是1. search 描述: 执行搜索查询并返回搜索结果。当您需要查找有关特定主题的信息时使用此功能。 参数: query (字符串) – 搜索查询字符串,除非是中文专有名词,否则使用英文单词 2. click 描述: 点击搜索结果中的链接并导航到相应页面。当您需要查看特定搜索结果的详细内容时使用此功能。 参数: link_id (整数) – 要点击的链接ID(来自搜索结果中的序号) 3. open 描述: 打开特定网站。通过URL获取任何网站的内容。 参数: url (字符串) – 目标网站URL或域名 4. finish 描述: 完成任务。当您已找到所需信息时使用此功能。 参数: 无
chat_template中的固定模板使用英文思过程,如果要更换其他语言,需要修改以下部分(暂时支持中文和英文)<重要配置> – 采用语言 * 搜索关键词:英文 -> 在这里换成“中文”或者其他语言 * 思考:英文 -> 在这里换成“中文”或者其他语言
GLM-4-0414 系列模型的提示词构造可以前往对应的模型仓库中的 chat_template.jinja 查看具体的模型对话模板。
现在可以通过 https://chat.z.ai/ 测试,左上角可以选择模型。
6.1和6.11哪个大?

Strawberry有几个r
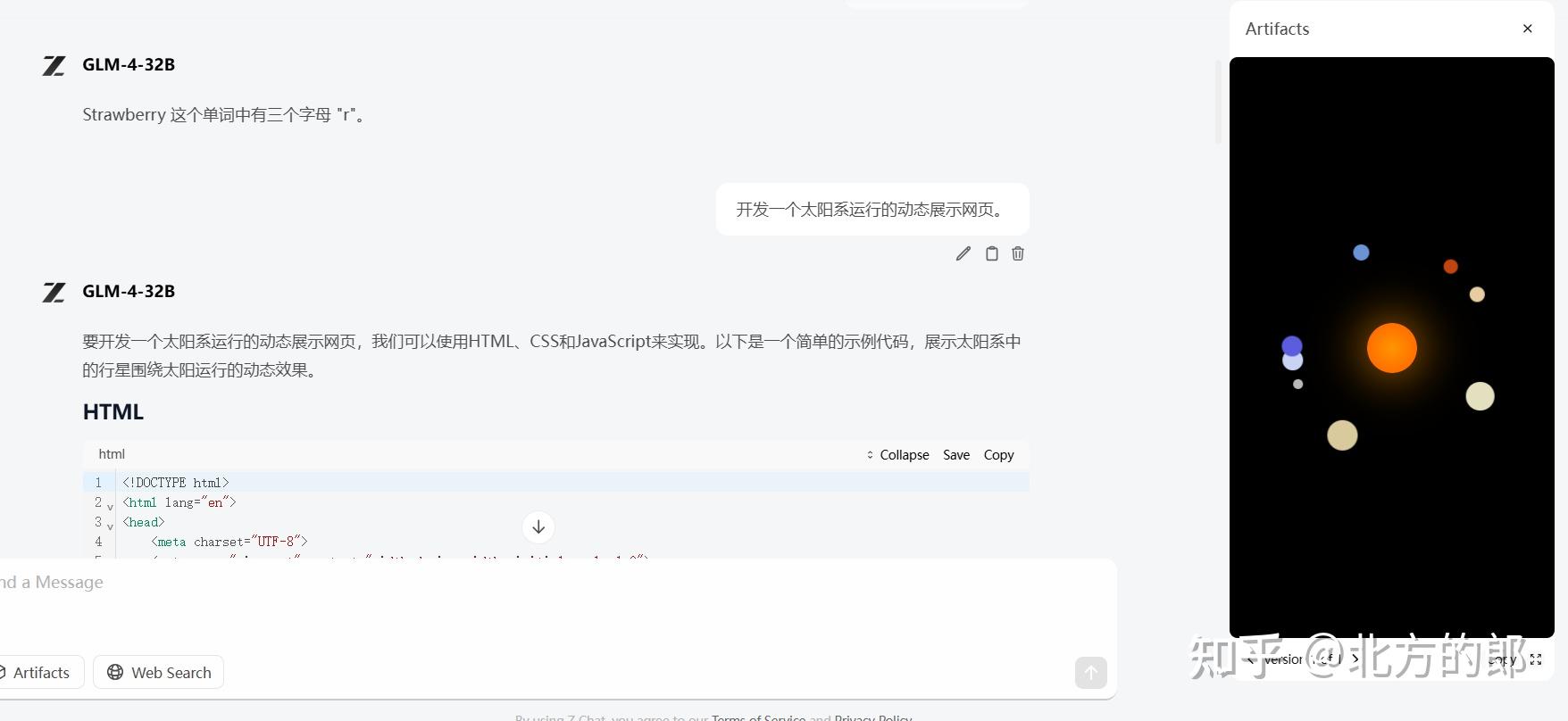
开发一个太阳系运行的动态展示网页
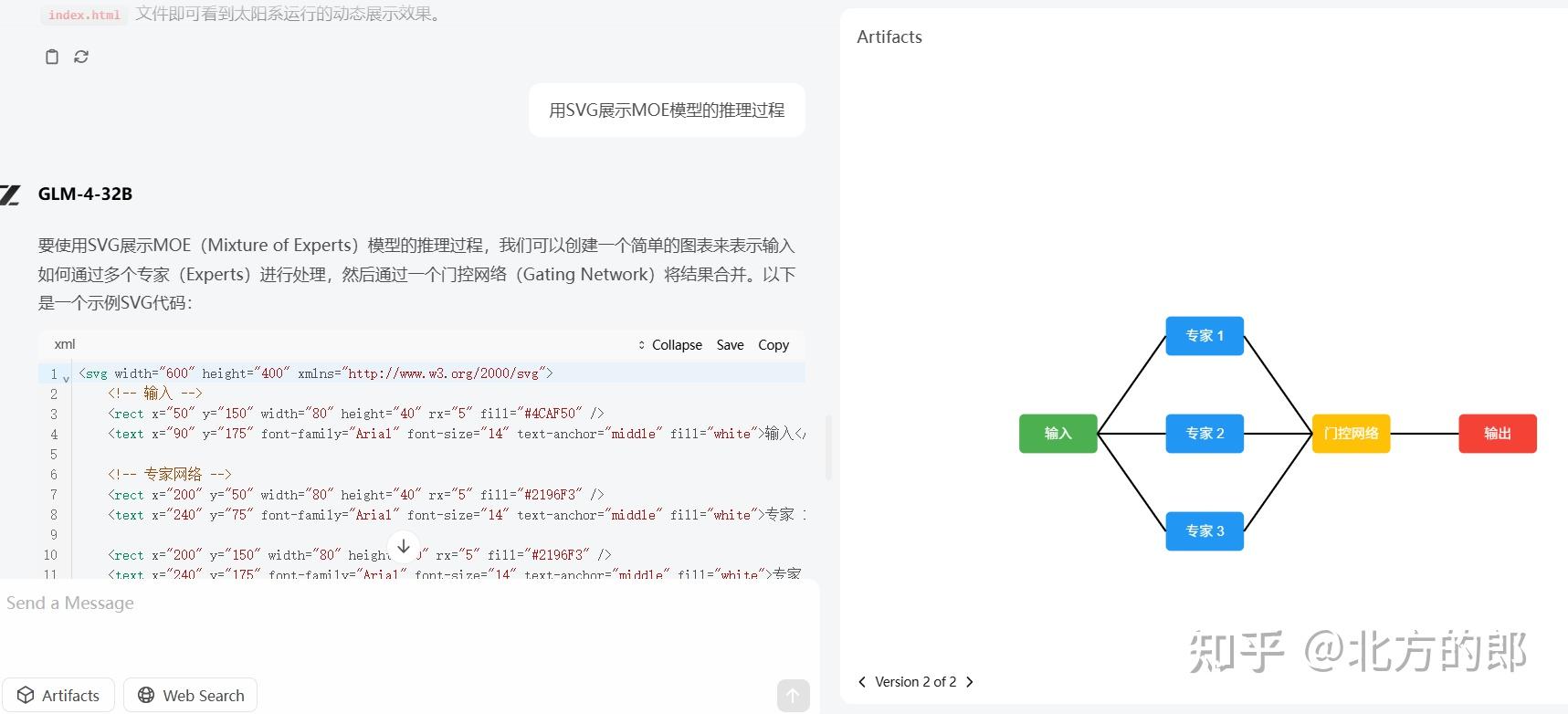
用SVG展示MOE模型的推理过程
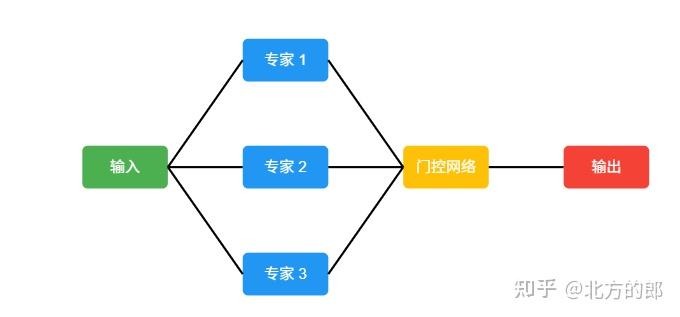
整体效果还不错。
从ChatGLM-6B用到现在,GLM系列终于开源32B的中杯模型了,不容易啊。
——完——
@北方的郎 · 专注模型与代码
喜欢的朋友,欢迎赞同、关注、分享三连 ^O^
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/265371.html原文链接:https://javaforall.net


