
做过科研的人大概都有这样的体会——论文的核心思路可能一周就理清了,但一张方法架构图却能折腾三天。打开 draw.io 或 Visio,手动拖拽矩形、对齐箭头、调整配色,每一步都在消耗本该用于思考的精力。更不用说 BioRender 这类专业工具的高昂订阅费用,对于预算有限的课题组来说并不友好。
传统的科研绘图流程存在几个根本性的痛点。第一,学习成本高——无论是 Adobe Illustrator 还是 Inkscape,掌握矢量绘图软件本身就需要投入大量时间。第二,迭代效率低——导师一句”把模块 A 和模块 B 的位置换一下”,可能意味着半天的返工。第三,审美一致性难以保证——不同作者绘制的图表风格各异,放在同一篇论文里显得参差不齐。
2025 年下半年,Google 发布了 Gemini 3 Pro Image 模型(代号 Nano Banana Pro),这个模型在科研绘图领域展现出了相当强的能力。它能够理解图表中的逻辑关系,准确渲染箭头、标签和层级结构,支持 4K 超高清输出(4096×4096 像素),并且对中文的支持远超同类模型。围绕这个模型,一套从”文献输入”到”可编辑矢量图输出”的完整工作流正在成型。
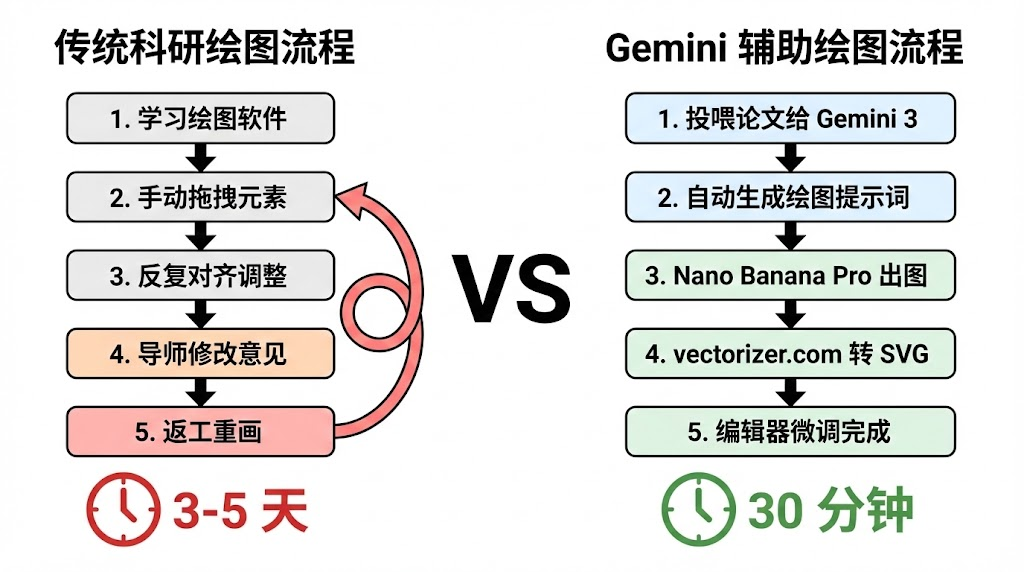

以下是经过社区验证的完整实操流程,不需要编程基础,普通科研人员即可上手。
Step 1:准备 Gemini 3 + Nano Banana Pro 工具环境
国内用户推荐使用 DeepSider 浏览器插件,它封装了 Gemini 3 的 API 接口,无需 Google 账号,也不需要特殊的网络环境。安装后在浏览器侧边栏即可调用。如果你有 Google AI Studio 的访问权限,也可以直接在官方平台上使用。
Step 2:投喂文献,让 Gemini 生成绘图提示词
这一步的关键在于提示词的质量。将 SCI 论文全文(PDF 或纯文本)提供给 Gemini 3,配合以下指令:
Gemini 3 会基于论文内容,输出一段结构化的绘图描述。这段描述本质上是对论文方法部分的视觉化翻译——它会识别出输入、处理模块、输出之间的逻辑关系,并将其组织成适合图像生成模型理解的格式。

Step 3:用 Nano Banana Pro 生成科研绘图
在 DeepSider 中切换至 Nano Banana 2 的 2K 模型(2K 指的是 2048×2048 分辨率的高清模式,日常使用普通模式即可),将上一步生成的提示词粘贴进去,等待出图。
需要注意的是,Nano Banana Pro 的输出是位图格式(PNG),这意味着图中的每个元素——矩形、箭头、文字——都被”烧”在了像素里,无法单独选中和编辑。这正是下一步要解决的问题。
Step 4:位图转矢量图——核心转换步骤
将生成的 PNG 图片上传到 vectorizer.com(中文界面地址:vectorizer.com/zh/),网站会自动将位图转换为 SVG 格式的矢量图。转换完成后,原本”焊死”在像素中的每个图形元素都变成了独立的矢量路径,可以自由选中、移动、缩放和重新着色。
这个转换过程的底层技术叫做”图像描摹”(Image Tracing)。vectorizer.com 采用了深度学习与经典 Potrace 算法相结合的”深度矢量引擎”,相比纯算法方案,它在角点优化、对称性保持和自适应简化方面都有明显改进,尤其擅长保留科研绘图中的文字清晰度和细线条完整性。
Step 5:导入编辑器,自由编辑
将转换后的 SVG 文件导入 Adobe Illustrator、Inkscape(免费开源)、Figma 或任何支持 SVG 的编辑器中,即可开始二次编辑:拖动模块调整布局、修改箭头指向、替换文字标签、统一调整配色、添加新的标注和说明。
至此,一张可自由编辑的、媲美 BioRender 质量的科研机制图就完成了。
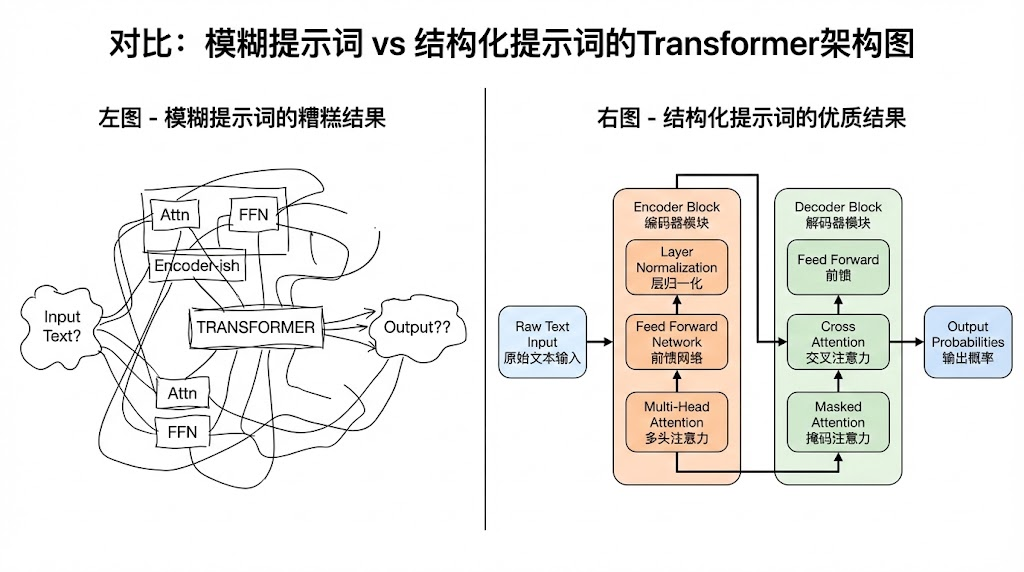
上面五步流程中,真正决定出图质量的是 Step 2——提示词的编写。很多人第一次用 Nano Banana Pro 画科研图时,往往只写一句”画一张 Transformer 架构图”,结果得到的图要么缺少关键模块,要么连线混乱。这不是模型的问题,而是指令不够具体。
一个高质量的科研绘图提示词,应该包含以下几个层次的信息:
第一层:内容描述(画什么)
明确列出所有需要出现的模块名称、模块之间的连接关系、数据流的方向。不要用模糊的描述,而是用结构化的方式逐一列举。比如:
第二层:风格约束(怎么画)
指定配色方案、背景色、形状风格、字体要求。这一层直接决定了图表是否具有学术感:
第三层:布局指令(放在哪)
指定整体的布局方向和模块的相对位置关系:
将这三层信息组合在一起,Gemini 3 生成的提示词质量会有质的飞跃,Nano Banana Pro 的出图准确率也会大幅提高。
Nano Banana 教程
手动工作流虽然可行,但仍然依赖人工编写提示词、手动调整参数、反复抽卡碰运气。Google Cloud AI Research 联合北京大学团队发布的 PaperBanana 项目,试图从根本上解决这个问题——你只需要丢进去一篇论文,它就能全自动输出发表级的科研图表。
- 论文地址:https://arxiv.org/pdf/2601.23265
- 项目主页:https://dwzhu-pku.github.io/PaperBanana/
- GitHub 仓库:https://github.com/dwzhu-pku/PaperBanana
4.1 为什么通用模型画不好学术图
Nano Banana Pro 虽然强大,但在面对学术架构图时仍然力不从心。核心原因在于空间逻辑。学术架构图的本质不是”好看的图片”,而是”精确的视觉化逻辑表达”。模块 A 的输出必须连接到模块 B 的输入,数据流的方向必须与论文描述完全一致,任何一条多余的连线或缺失的箭头都会导致图表传达错误的信息。
而图像生成模型天然擅长”发散”——生成看起来合理的视觉内容,但不擅长”收敛”——严格遵循精确的拓扑约束。结果就是经常出现”幻觉”:该连的线没连,不该连的线乱连。
PaperBanana 的解决方案是:组建一支由五个智能体构成的绘图团队,模拟人类绘制学术插图的完整思维链,将”不可控的像素生成”降维为”可控的结构化渲染”。
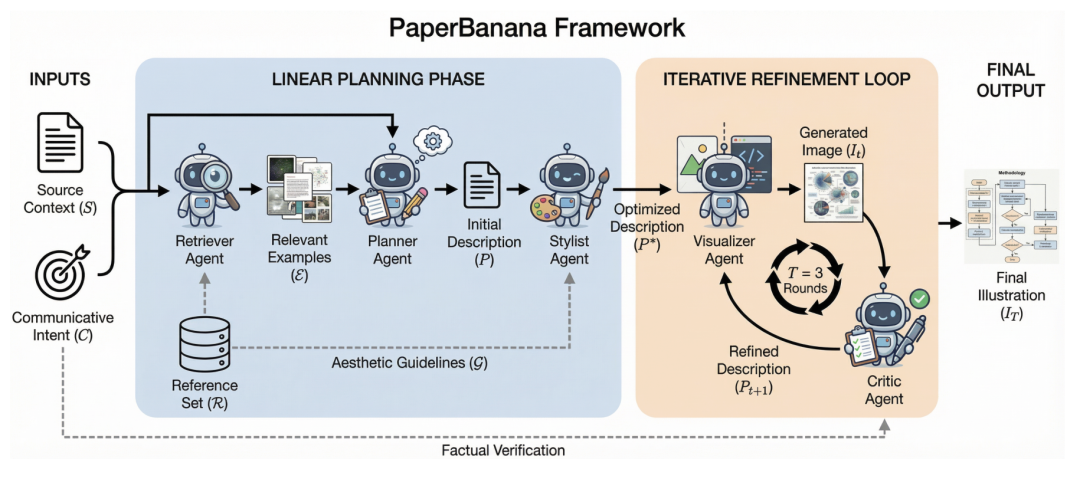
图 8:五大智能体协同工作流——从检索、规划、风格化、可视化到审查修正
4.2 五大智能体的分工
检索智能体(Retriever) —— 解决”无从下笔”的问题。利用 RAG 技术从学术图表库中检索结构相似的参考图,为后续规划提供布局灵感。就像人类画图前也会先翻看同领域的优秀论文一样。
规划智能体(Planner) —— 核心大脑。将论文的方法描述转化为结构化的图表规划文档,精确定义每个模块的名称、位置、尺寸、连接关系和数据流方向。关键贡献在于实现了”内容与样式的解耦”。
审美智能体(Stylist) —— 注入学术灵魂。基于从 5275 篇 NeurIPS 论文中提炼出的审美标准,强制校准配色、背景、几何形状和字体层级。拒绝一切”AI 霓虹感”。
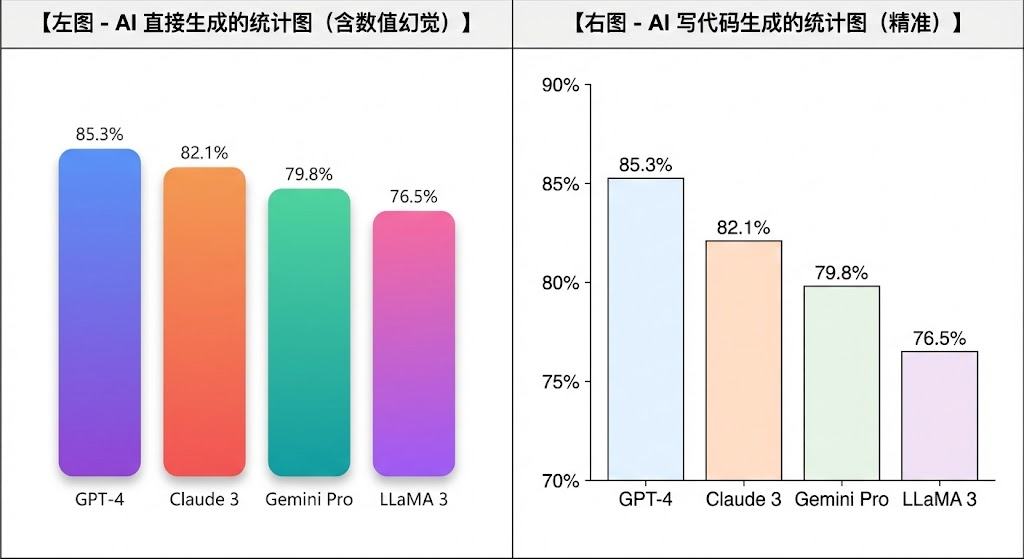
绘图智能体(Visualizer) —— 采用混合渲染策略。架构图调用 Nano Banana Pro 生成(此时前面三个智能体已经将模糊描述转化为精确指令,大幅降低幻觉概率);统计图表则直接生成 Matplotlib 代码绘制,确保数据绝对精准——因为 AI 直接画统计图极易出现”数值幻觉”,比如把 85.3% 的柱子画得比 82.1% 的还矮。
审查智能体(Critic) —— 闭环反馈。模拟导师视角逐项检查:模块是否遗漏?连线是否正确?标签是否一致?支持最多 3 轮自动迭代修正。
4.3 顶会级审美标准
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/274030.html原文链接:https://javaforall.net


