
短的结论:做更好的自己
基本信息:
- 成本:暂时免费
- 速度:约40字每秒
- 平均长度:约4900字
- 平均耗时:128秒

测试方式:参见https://zhuanlan.zhihu.com/p/32
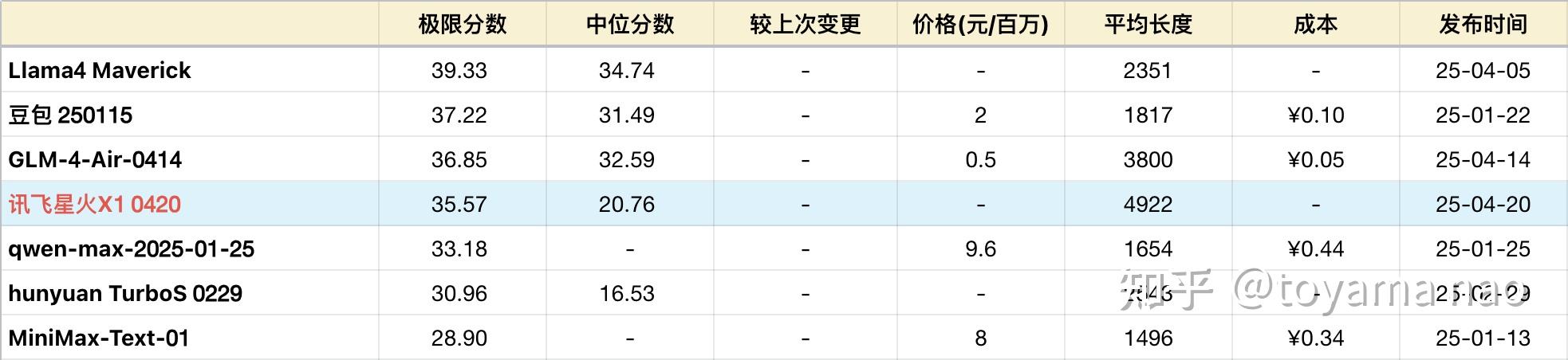
这次测试基于4月题目,已经增加#34 & #35 2道Hard题,所以所有模型的分数相比3月有变动。
讯飞在1月发布X1时,尝试限制只让X1回答数学问题,然而限制本身有很大问题,很多数学问题被挡住。3月发过一次更新,但改善不大。可以看出X1在1月并没有训练好,就匆忙发布。而如今的X1 0420版才能算当时承诺的X1。
讯飞在官宣材料中称X1同时具备快思考和慢思考两种模式,而API并未提供切换设置。从官宣文本细节中找到“基于系统指令控制模型是否深度思考”的描述,疑似要通过prompt来开启。但看X1目前的耗时达到近130秒,并不快。而输出不到5000字,在一众推理模型里确实偏少。不好判断API默认是快模式还是慢模式。在缺乏官方进一步说明前,姑且把本轮测试当做X1的“快模式”成绩。或许成绩还有提升空间。
由于先前的旧X1无法跑完测试,缺乏旧版本的完整数据,从仅有的片段成绩来看,完整版X1对旧版甚至无法保持稳定胜出。下面详细分析。
优势:
- 回答耗时相比旧版平均255秒,有大幅优化。
劣势:
- 极其严重的幻觉。在涉及上下文幻觉、字符幻觉测试的相关题目中,X1表现完全没有推理模型该具备的底线能力。如#9单词缩写,X1表现甚至不如顺序稍低的基础模型混元turbos。#33洗牌分牌问题,对具备逐步推导能力的推理模型算Easy题,而X1竟然从洗牌第一步开始数错分错。#4拧魔方,虽然较难,但大部分推理模型至少知道怎么拧,只是记不住魔方6面的颜色顺序。而X1在2分钟推理后给出了魔方并没有被拧,颜色没有改变的结论。
- 计算能力退步。#10水热热量,X1旧版曾经拿过满分,而新版在3pass中出现三种不同的badcase。包含死循环,重复输出相同搭配,计算错误。#22连续计算和旧版类似,对小数乘法的掌握较差。考察平面几何方程求解的#21线段求交,X科大讯飞 星火 教程1的表现同样不如豆包1.5等基础模型,交点计算大部分错误。
- 多步推理极易中途出错,指令遵循差。在重点考察多步推理的题目中,X1的问题共性是在推理的前半段尚能保持对题意的理解,从约1000字之后开始,尤其当推理出现矛盾时,会尝试撇开题目约束,自行发挥。典型如#30日记整理,X1在第一个条件上花费了上千字推导,随后的约束条件大都忘记,或者只在“嘴上”提一下。
- 偶现死循环,耗尽Token。
赛博史官曰:
讯飞从2023年起,每次发布新模型必打GPT-4/4o/R1/O1,然而对抗强敌的壮志仅在刘总的激情演讲时片刻驻留,一旦民众开始上手体验,种种幻象便会烟消云散,宛如过了午夜12点的水晶鞋和南瓜马车。
当然也要看到,讯飞一路的坚持不放弃。不是讯飞不努力,而是对手都太强。如今讯飞还留在大模型牌桌上,拿出了打磨4个月的X1,刷新了自己的最好成绩,做了更好的自己,这何尝不是一种超越。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/282409.html原文链接:https://javaforall.net


