
Yarn和MapReduce
1 对master上的hadoop/etc/hadoop下的hdfs-site.xml做如下配置
<configuration> <--配置文件在hdfs上每个block的备份数量--> <property> <name>dfs.replication</name> <value>3</value> </property> <--取消hdfs访问的权限限制,为后期计算Java程序调用时使用--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>对所有的master的yarn-site.xml做如下配置
<configuration> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- 指定reducer获取数据的方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>file:///data/hadoop/yarn/nm</value> </property> </configuration>
对所有的slave的yarn-site.xml做如下配置
<configuration> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- 指定reducer获取数据的方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>file:///data/hadoop/yarn/nm</value> </property> </configuration>
2、配置MapReduce
将master上的 mapred-site.xml.template在当前目录下复制一份,并重命名为:mapred-site.xml
对mapred-site.xml做如下配置
<configuration> <property> <!--指定Mapreduce运行在yarn上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> 至此,所有的配置全部完成,此时在master上执行
start-dfs.sh 启动hdfs系统
start-yarn.sh 启动yarn和MapReduce
启动之后使用jps命令查看进程
master:

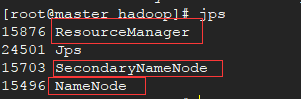
slave:
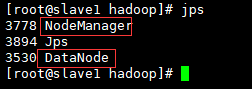
如果看到以上信息,那么恭喜你已经配置成功了。
3 在浏览器中进行查看
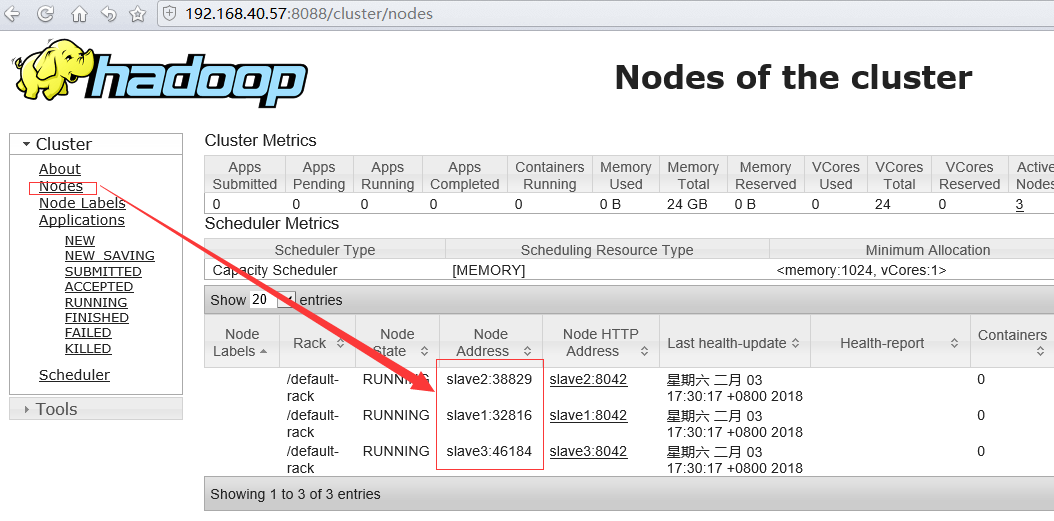
如果浏览信息如果所示。那么从此请开启的大数据之旅。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请联系我们举报,一经查实,本站将立刻删除。
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/111287.html原文链接:https://javaforall.net


