
大家好,又见面了,我是你们的朋友全栈君。
Kafka集群搭建与配置
准备工作
安装java环境
搭建zookeeper集群
搭建kafka集群
1. 准备工作
1.1 安装包
1.2 准备至少3台主机(ubuntu系统)
如果没有物理机,也可以弄3台虚拟机。ubuntu系统不会安装的话可以自己百度哦,这里就不细说了。
作者用的是虚拟机,下面是3台电脑的配置
主机名
IP地址
硬件配置
kafka-1
192.168.1.42
4CPU、4G内存、128G存储
kafka-2
192.168.1.41
4CPU、4G内存、128G存储
kafka-3
192.168.1.47
4CPU、4G内存、128G存储
2. 安装JAVA环境
在每台主机下执行下面步骤:
将安装包移到/usr/local目录下
mv jdk-8u162-linux-x64.tar.gz /usr/local
解压文件
tar -zxvf jdk-8u162-linux-x64.tar.gz
重命名文件夹为java
mv jdk-8u162-linux-x64 java
用vim打开/etc/profile文件(Linux下配置系统环境变量的文件)
vim /etc/profile
按i进入编辑模式,在文件末尾添加如下JAVA环境变量
export JAVA_HOME=/usr/local/java
export JRE_HOME=/usr/local/java/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
添加环境变量后,结果如下图所示,按 esc 退出编辑模式,然后输入:+wq ,按回车保存(也可以按shift + zz 进行保存)。
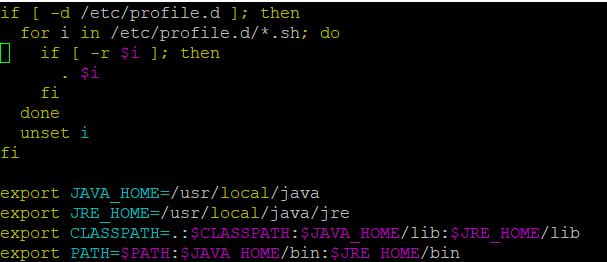

配置环境变量
最后,需要让该环境变量生效,执行如下代码:
source /etc/profile
检验JAVA是否安装成功
>echo $JAVA_HOME ; # 检验变量值
>java -version;
>java;
>javac;
如果设置正确的话,java -version 会输出 java 的版本信息,java 和 javac 会输出命令的使用指导。
3. 搭建zookeeper集群
在每台主机上执行下面步骤:
将安装包移到/usr/local目录下
mv zookeeper-3.4.12.tar /usr/local
解压文件
tar -zxvf zookeeper-3.4.12.tar
重命名文件夹为zookeeper
mv zookeeper-3.4.12 zookeeper
配置zookeeper环境变量,首先打开profile文件
vim /etc/profile
按i进入编辑模式,在文件末尾添加zookeeper环境变量
#set zookeeper environment
export ZK_HOME=/usr/local/zookeeper
export PATH=$ZK_HOME/bin:$PATH
保存文件后,让该环境变量生效
source /etc/profile
打开zookeeper配置文件
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
vim /usr/local/zookeeper/conf/zoo.cfg
修改zookeeper配置文件
#修改数据文件夹路径
dataDir=/usr/local/zookeeper/data
#在文件末尾添加
server.1=192.168.1.42:2888:3888
server.2=192.168.1.41:2888:3888
server.3=192.168.1.47:2888:3888
#其它不变
创建数据文件夹(dataDir指定的路径)
mkdir /usr/local/zookeeper/data
在此文件夹中创建myid文件,在myid文件中添加本机的 server ID,在本例中对应关系如下
主机名
IP地址
zookeeper
myid
kafka-1
192.168.1.42
server.1
1
kafka-2
192.168.1.41
server.2
2
kafka-3
192.168.1.47
server.3
3
所以,在kafka-1中执行下面命令
echo “1” > /usr/local/zookeeper/data/myid #kafka-1主机myid
在kafka-2中执行下面命令
echo “2” > /usr/local/zookeeper/data/myid #kafka-2主机myid
在kafka-3中执行下面命令
echo “3” > /usr/local/zookeeper/data/myid #kafka-3主机myid
在每台电脑上启动zookeeper
/usr/local/zookeeper/bin/zkServer.sh start
全部启动后,查看启动结果
/usr/local/zookeeper/bin/zkServer.sh status
kafka-1启动结果

kafka-2启动结果

kafka-3启动结果

如果启动失败就关闭防火墙再启动
4. 搭建kafka集群
在每台主机上执行下面步骤:
将安装包移到/usr/local目录下
mv kafka_2.11-2.0.0 .tgz /usr/local
解压文件
tar -zxvf kafka_2.11-2.0.0 .tgz
重命名文件夹为kafka
mv kafka_2.11-2.0.0 kafka
配置kafka环境变量,首先打开profile文件
vim /etc/profile
按i进入编辑模式,在文件末尾添加kafka环境变量
#set kafka environment
export KAFKA_HOME=/usr/local/kafka
PATH=${KAFKA_HOME}/bin:$PATH
保存文件后,让该环境变量生效
source /etc/profile
在kafka-1主机中修改server.properties配置文件
打开配置文件
vim /usr/local/kafka/config/server.properties
修改配置如下(IP地址应该根据实际情况填写)
broker.id=1
listeners=PLAINTEXT://192.168.1.42:9092 # 新增
zookeeper.connect=192.168.1.41:2181,192.168.1.42:2181,192.168.1.47:2181 # 新增
在kafka-2主机中修改server.properties配置文件
打开配置文件
vim /usr/local/kafka/config/server.properties
修改配置如下(IP地址应该根据实际情况填写)
broker.id=2
listeners=PLAINTEXT://192.168.1.41:9092 #新增
zookeeper.connect=192.168.1.41:2181,192.168.1.42:2181,192.168.1.47:2181 #新增
在kafka-3主机中修改server.properties配置文件
打开配置文件
vim /usr/local/kafka/config/server.properties
修改配置如下(IP地址应该根据实际情况填写)
broker.id=3
listeners=PLAINTEXT://192.168.1.47:9092 #新增
zookeeper.connect=192.168.1.41:2181,192.168.1.42:2181,192.168.1.47:2181 #新增
启动kafka(要确保zookeeper已启动)
在每台主机上分别启动kafka
/usr/local/kafka/bin/kafka-server-start.sh -daemon config/server.properties
4.测试kafka集群:
在其中一台虚拟机(192.168.1.47)创建topic
/usr/local/kafka/bin/kafka-topics.sh –create –zookeeper 192.168.1.47:2181 –replication-factor 3 –partitions 1 –topic test-topic
查看创建的topic信息
/usr/local/kafka/bin/kafka-topics.sh –describe –zookeeper 192.168.1.47:2181 –topic test-topic
结果如下图所示:

topic信息
搭建成功啦
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/131601.html原文链接:https://javaforall.net


