
大家好,又见面了,我是你们的朋友全栈君。
01 大数据概述
数据来源: 了解大数据到来之前,传统数据的通用处理模式1、企业内部管理系统 ,如员工考勤(打卡)记录。 2、客户管理系统(CRM)
数据特征: 1、数据增长速度比较缓慢,种类单一。 2、数据量为GB级别,数据量较小。
数据处理方式: 1、数据保存在数据库中。处理时以处理器为中心,应用程序到数据库中检索数据再进行计算(移 动数据到程序端)
遇到的问题: 1、数据量越来越大、数据处理的速度越来越慢。 2、数据种类越来越多,出现很多数据库无法存储的数据,如音频、照片、视频等。
02 什么是大数据?(Big Data)
是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
是指一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
数据的存储单位 最小的基本单位是bit 1 Byte =8 bit 1 KB = 1,024 Bytes = 8192 bit
KB MB GB TB PB EB ZB YB BB NB DB 进率1024
03 传统数据与大数据的对比
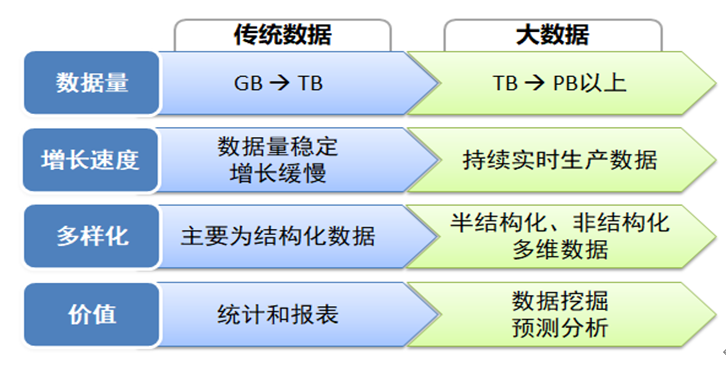

04 大数据的特点
Volume(大量): 数据量巨大,从TB到PB级别。
Velocity(高速): 数据量在持续增加(两位数的年增长率)。
Variety(多样): 数据类型复杂,超过80%的数据是非结构化的。
Value(低密度高价值): 低成本创造高价值。
数据来自大量源,需要做相关性分析。
需要实时或者准实时的流式采集,有些应用90%写vs.10%读。
数据需要长时间存储,非热点数据也会被随机访问。
4.1 传统数据与大数据处理服务器系统安装对比
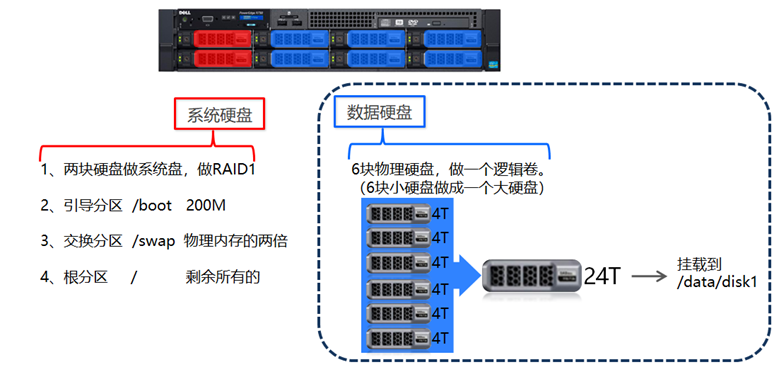
4.2 大数据下服务器系统安装
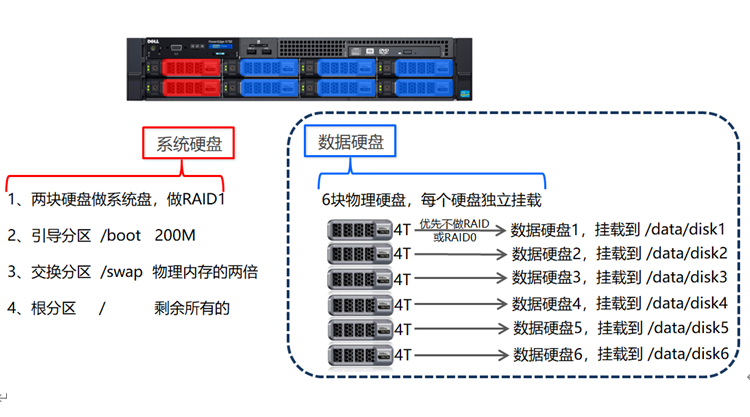
05 大数据生态系统
大数据:历史数据量逐渐攀升、新型数据类型逐渐增多。是企业必然会遇到的问题
新技术:传统方式与技术无法处理大量、种类繁多的数据,需要新的技术解决新的问题。
技术人员:有了问题,有了解决问题的技术,需要大量懂技术的人解决问题。 最佳实践:解决 问题的方法,途径有很多,寻找最好的解决方法。
商业模式:有了最好的解决办法,同行业可以复用,不同行业可以借鉴,便形成了商业模式。
新技术
HADOOP
HDFS: 海量数据存储。
YARN: 集群资源调度。
MapReduce: 历史数据离线计算。
Hive:海量数据仓库。
Hbase: 海量数据快速查询数据库。
Zookeeper: 集群组件协调。
Impala: 是一个能查询存储在Hadoop的HDFS和HBase中的PB级数据的交互式查询引擎。
Kudu: 是一个既能够支持高吞吐批处理,又能够满足低延时随机读取的综合组件
Sqoop: 数据同步组件(关系型数据库与hadoop同步)。
Flume : 海量数据收集。
Kafka: 消息总线。
Oozie: 工作流协调。
Azkaban: 工作流协调。
Zeppelin: 数据可视化。
Hue: 数据可视化。
Flink: 实时计算引擎。
Kylin: 分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析。
Elasticsearch: 是一个分布式多用户能力的全文搜索引擎。
Logstash: 一个开源数据搜集引擎。
Kibana: 一个开源的分析和可视化平台。
SPARK
SparkCore:Spark 核心组件
SparkSQL: 高效数仓SQL引擎
Spark Streaming: 实时计算引擎
Structured: 实时计算引擎2.0
Spark MLlib: 机器学习引擎
Spark GraphX: 图计算引擎
06 大数据生态系统
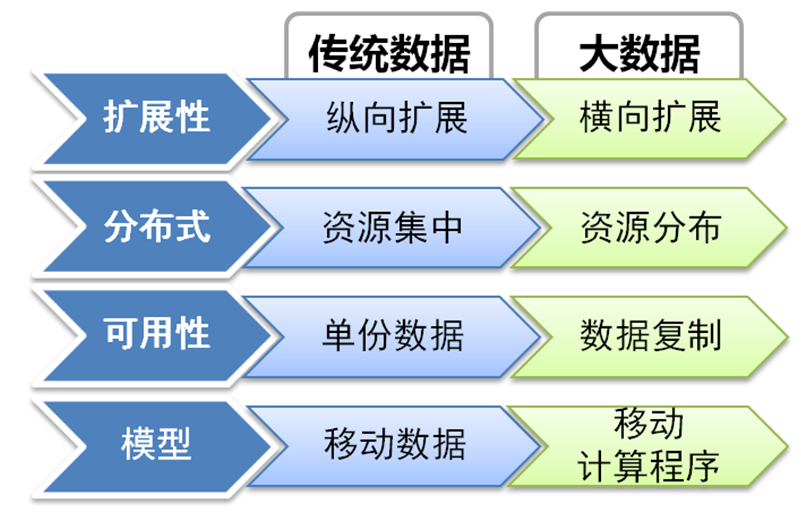
大数据技术快的原因
1、分布式存储
2、分布式并行计算
3、移动程序到数据端
4、更前卫、更先进的实现思路
5、更细分的业务场景
6、更先进的硬件技术+更先进的软件技术
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/135887.html原文链接:https://javaforall.net


