
大家好,又见面了,我是你们的朋友全栈君。
目录
1.宽度学习(Broad Learning System)
对宽度学习的理解可见于这篇博客宽度学习(Broad Learning System)_颹蕭蕭的博客-CSDN博客_宽度学习
这里不再做详细解释
2.MNIST数据集
mnist数据集官网(下载地址):MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
MNIST数据集有称手写体数据集,其中中训练集一共包含了 60,000 张图像和标签,而测试集一共包含了 10,000 张图像和标签。测试集中前5000个来自最初NIST项目的训练集.,后5000个来自最初NIST项目的测试集。前5000个比后5000个要规整,这是因为前5000个数据来自于美国人口普查局的员工,而后5000个来自于大学生。
MNIST数据集自1998年起,被广泛地应用于机器学习和深度学习领域,用来测试算法的效果,相当于该领域的”hello world!”
3.复刻MNIST数据集的预处理及训练过程
原bls代码下载地址:Broad Learning System
下载后,我先用原代码中带的数据和代码进行训练,运行结果如下:
1.不含增量的bls代码:
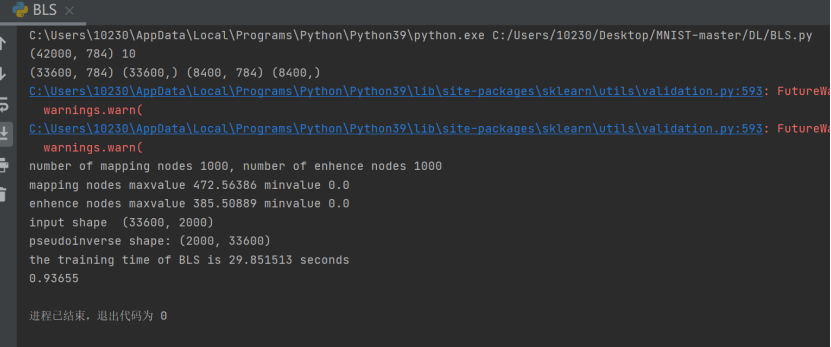

2.含有增量的bls代码:
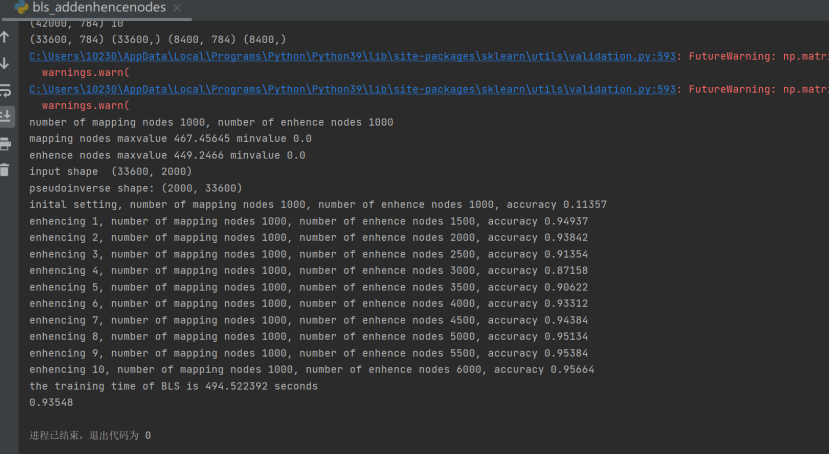
可以看到bls训练模型的时间非常短并且精确度达到0.93以上
然后我们回过头来看它用的训练集和测试集,它共输入三个csv文件,分别为test.csv,train.csv,sample_submission.csv
其中格式为:
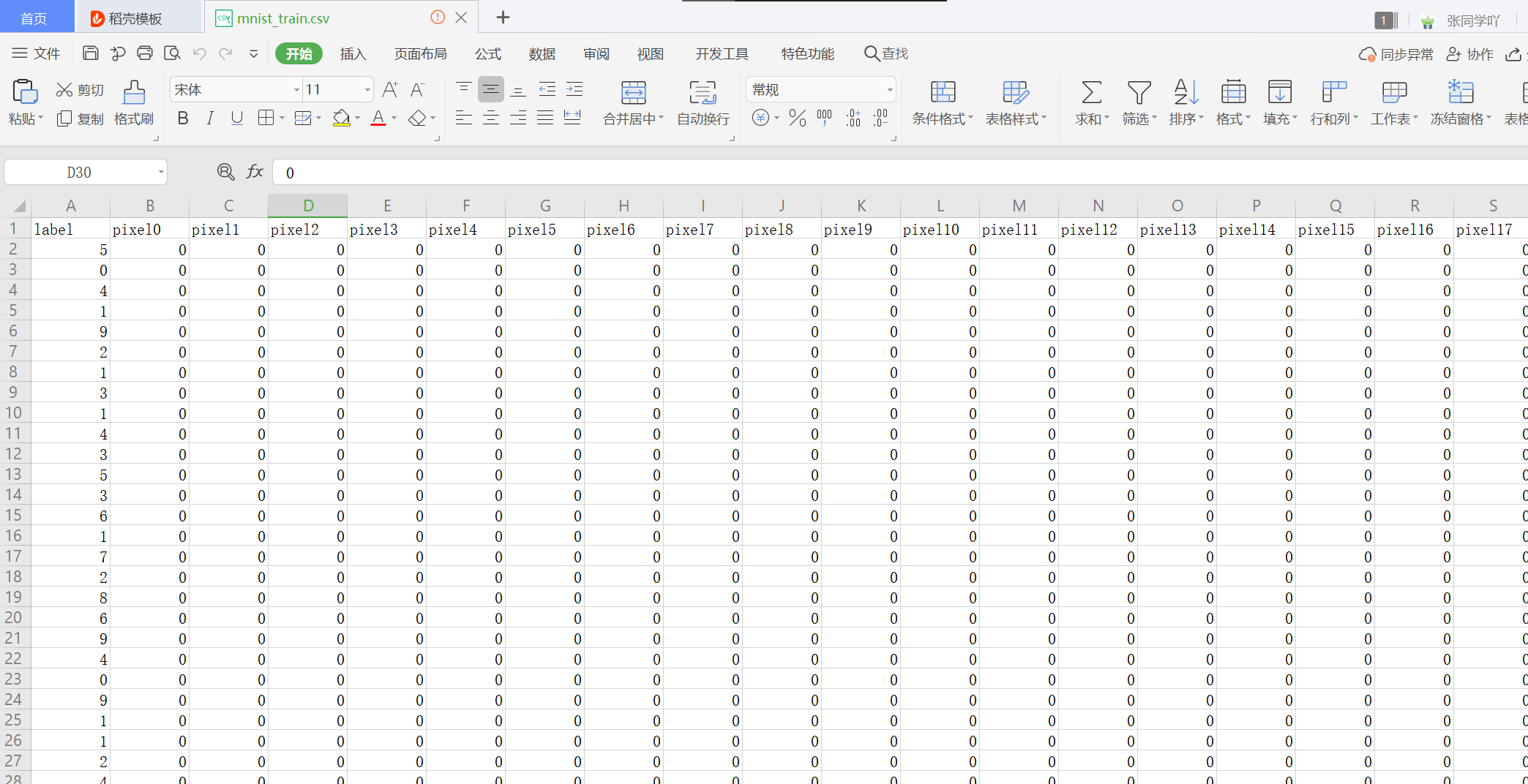
这就是我们处理完MNIST数据之后需要bls代码中训练的数据,统计得到以下信息
| 数据集 | 数据总数 |
| test.csv(测试集) | 28000张 |
| train.csv(训练集) | 42000张 |
其中sample_submission.csv是提交样例,它最后会用来保存训练出的模型对测试集打的标签为csv文件。
那么得到这些信息我们就可以开始处理我们的mnist数据集了,在官网下载完数据集后我们得到了四个文件:
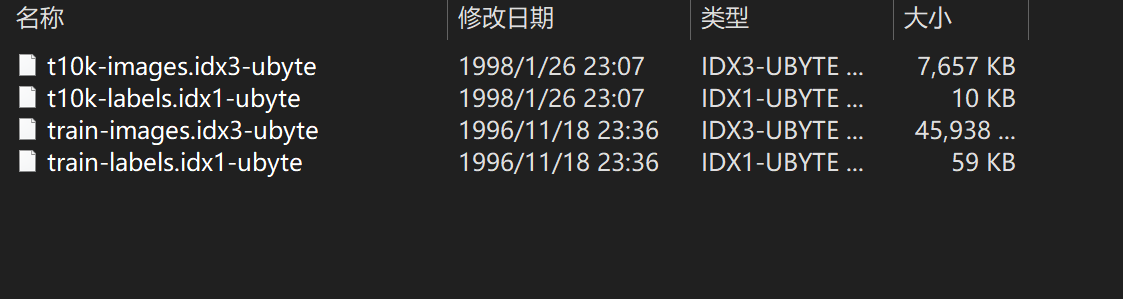
这个时候如果你是初学者,你就会奇怪明明是图像数据为什么下载完会是这四个东西?
这是因为为了方便使用,官方已经将70000张图片处理之后存入了这四个二进制文件中,因此我们要对这四个文件进行解析才能看到原本的图片。
此处用到struct包进行解析,详情见于Mnist数据集简介_查里王的博客-CSDN博客_mnist数据集
解析代码:
import os
import struct
import numpy as np
# 读取标签数据集
with open('../data/train-labels.idx1-ubyte', 'rb') as lbpath:
labels_magic, labels_num = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
# 读取图片数据集
with open('../data/train-images.idx3-ubyte', 'rb') as imgpath:
images_magic, images_num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(images_num, rows * cols)
# 打印数据信息
print('labels_magic is {} \n'.format(labels_magic),
'labels_num is {} \n'.format(labels_num),
'labels is {} \n'.format(labels))
print('images_magic is {} \n'.format(images_magic),
'images_num is {} \n'.format(images_num),
'rows is {} \n'.format(rows),
'cols is {} \n'.format(cols),
'images is {} \n'.format(images))
# 测试取出一张图片和对应标签
import matplotlib.pyplot as plt
choose_num = 1 # 指定一个编号,你可以修改这里
label = labels[choose_num]
image = images[choose_num].reshape(28, 28)
plt.imshow(image)
plt.title('the label is : {}'.format(label))
plt.show()运行结果:
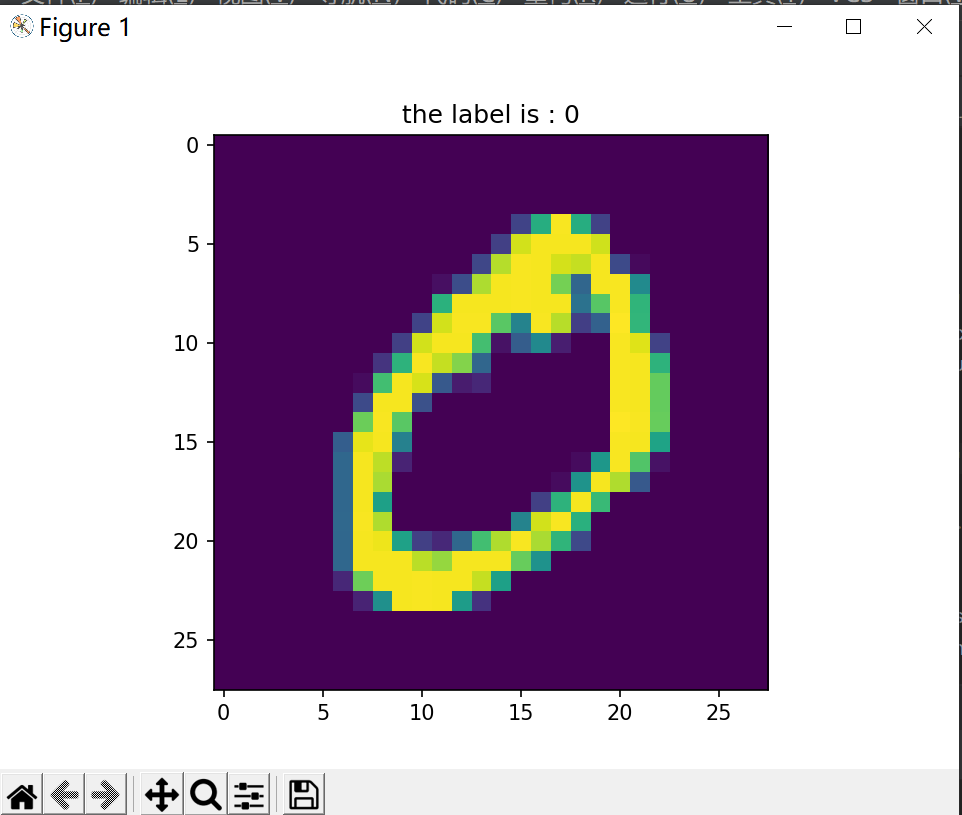
但是这并不是我们要的东西,我们需要的是将二进制文件解析后存入csv文件中用于训练。
在观察了原代码中所用的csv文件的格式以及bls代码中读取数据的方式后,我发现需要再存入之前对数据添加一个index,其中包括”label”和”pixel0~pixel784″,其中pixel是一维数组的元素编码,由于mnist数据集是28*28的图片,所以,转为一维数组后一共有784个元素。
知道这个原理后,编写代码如下:
import csv
def pixel(p_array, outf):
with open(outf, "w",newline='') as csvfile:
writer = csv.writer(csvfile)
# 先写入columns_name
writer.writerow(p_array)
def convert(imgf, labelf, outf, n):
f = open(imgf, "rb")
o = open(outf, "a")
l = open(labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(n):
image = [ord(l.read(1))]
for j in range(28*28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image)+"\n")
f.close()
o.close()
l.close()
if __name__ == '__main__':
p_array = []
for j in range(0, 785):
if j == 0 :
b1 = "label"
p_array.append(b1)
else:
b1 = 'pixel' + str(j - 1)
p_array.append(b1)
pixel(p_array,"../data/mnist_train.csv")
pixel(p_array,"../data/mnist_test.csv")
convert("../data/train-images.idx3-ubyte", "../data/train-labels.idx1-ubyte",
"../data/mnist_train2.csv", 42000)
convert("../data/t10k-images.idx3-ubyte", "../data/t10k-labels.idx1-ubyte",
"../data/mnist_test2.csv", 28000)
print("success!")代码运行结果;
得到经过二进制文件解析以及格式处理后的数据:
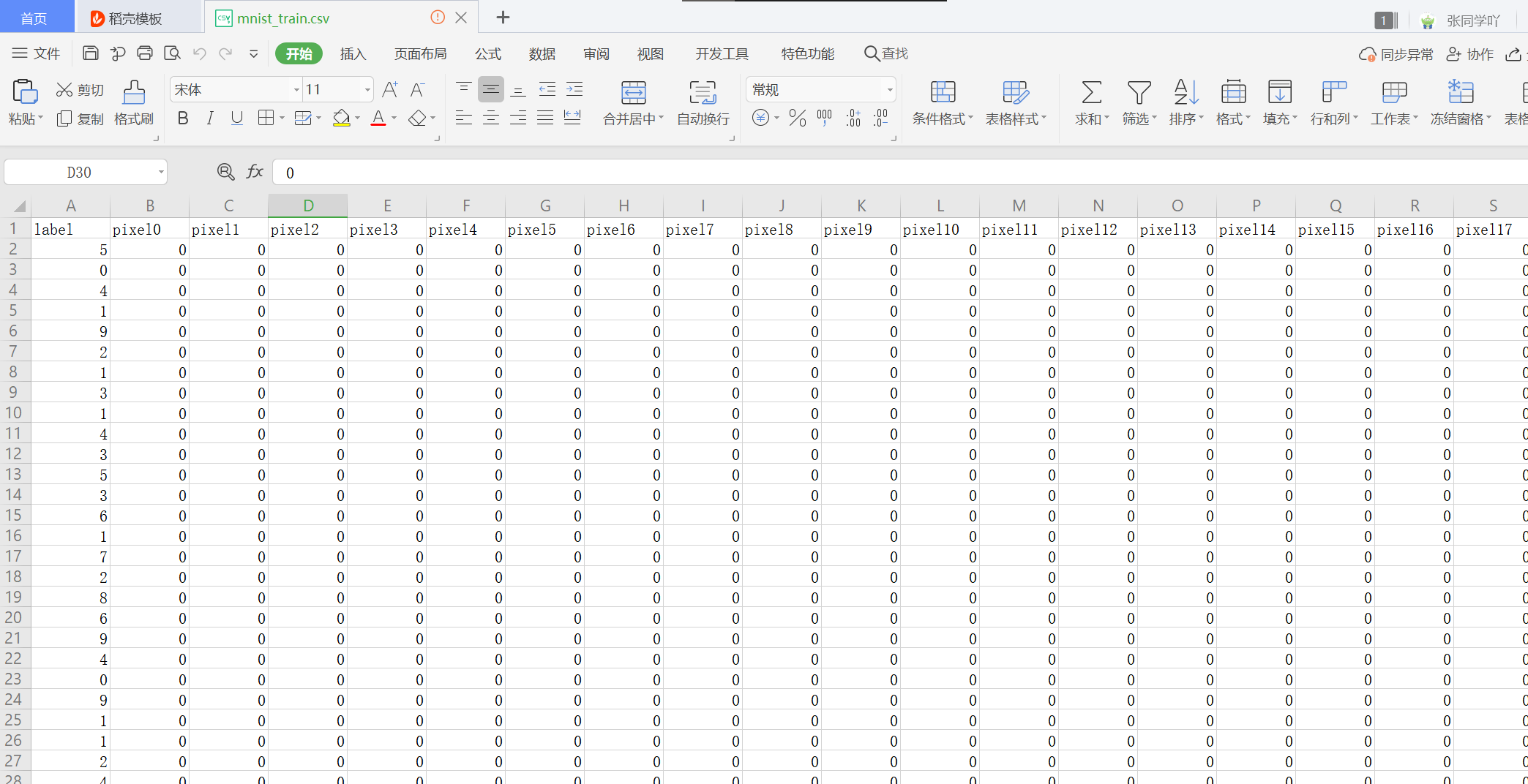
现在训练集文件格式与源代码格式一样了,但是,既然是复刻那么我们还有一个问题没有解决——数据总数不一样,根据源代码中信息,训练集有42000张,测试集28000张,但是我们的训练集有60000张,测试集有10000张,所以我们需要稍微处理一下我们数量,其实这个很简单,只要将训练集中的数据匀18000张给测试集就可以了,另外测试集中标签一行需要删除,因为测试集好比高考试卷,标签相当于答案,没有人会把高考答案告诉你然后让你考对不对。这个过程可以用python代码实现,只要加入一点点功能,编写功能代码如下:
(记得删除测试集中的标签)
import csv
def test_add(train_imgf,train_labelf,outf):
f = open(train_imgf, "rb")
o = open(outf, "a")
l = open(train_labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(42001, 60001):
image = [ord(l.read(1))]
for j in range(28 * 28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image) + "\n")
f.close()
o.close()
l.close()
def pixel(p_array, outf):
with open(outf, "w",newline='') as csvfile:
writer = csv.writer(csvfile)
# 先写入columns_name
writer.writerow(p_array)
def convert(imgf, labelf, outf, n):
f = open(imgf, "rb")
o = open(outf, "a")
l = open(labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(n):
image = [ord(l.read(1))]
for j in range(28*28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image)+"\n")
f.close()
o.close()
l.close()
if __name__ == '__main__':
p_array = []
for j in range(0, 785):
if j == 0 :
b1 = "label"
p_array.append(b1)
else:
b1 = 'pixel' + str(j - 1)
p_array.append(b1)
pixel(p_array,"../data/mnist_train2.csv")
pixel(p_array,"../data/mnist_test2.csv")
convert("../data/train-images.idx3-ubyte", "../data/train-labels.idx1-ubyte",
"../data/mnist_train2.csv", 42000)
convert("../data/t10k-images.idx3-ubyte", "../data/t10k-labels.idx1-ubyte",
"../data/mnist_test2.csv", 10000)
test_add("../data/train-images.idx3-ubyte", "../data/train-labels.idx1-ubyte", "../data/mnist_test2.csv")
print("success!")处理后,与提交案例一起加入bls训练,可以得到:
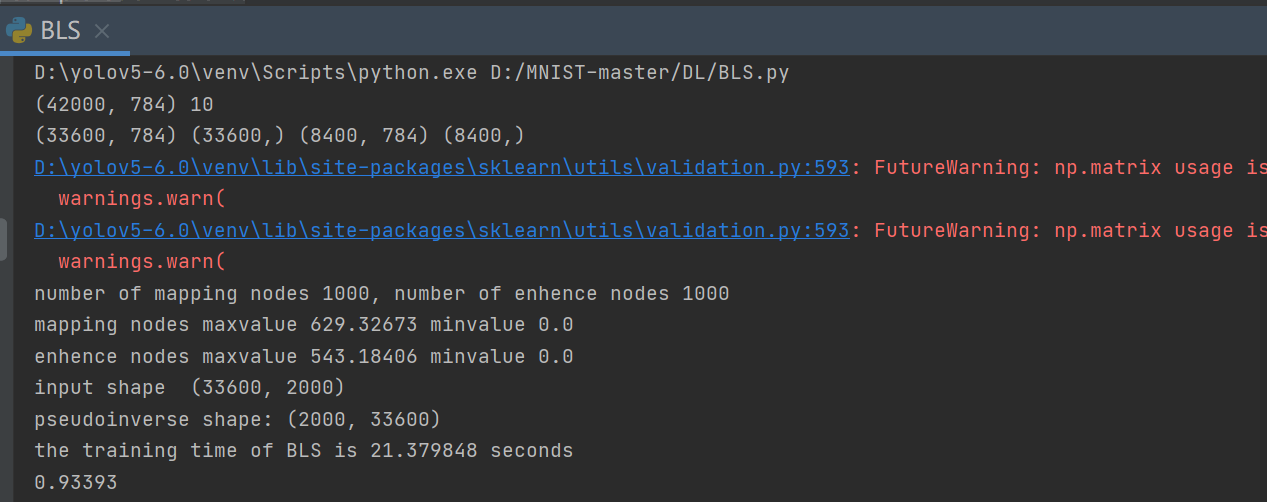
可以看到这与之前原始数据训练的结果几乎相同
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/143425.html原文链接:https://javaforall.net


