
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
DenseNet与ResNeXt
首先回顾一下DenseNet的结构,DenseNet的每一层都都与前面层相连,实现了特征重用。
下图表示一个DenseBlock
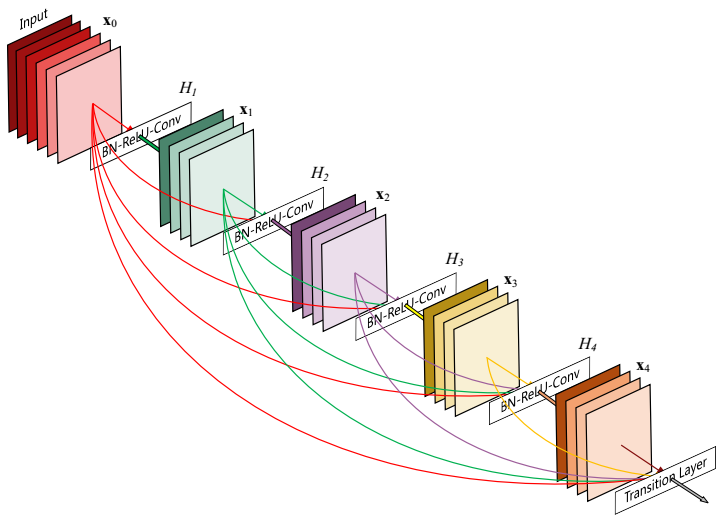

如图所示,在一个DenseBlock中,第i层的输入不仅与i-1层的输出相关,还有所有之前层的输出有关.记作:
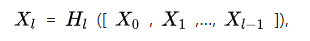
DenseNet网络的搭建
Growth_rate
在一个DenseBlock里面,每个非线性变换H输出的channels数为恒定的Growth_rate,那么第i层的输入的channels数便是k+i* Growth_rate, k为Input
的channels数,比如,假设我们把Growth_rate设为4,上图中H1的输入的size为8 * 32 * 32,输出为4 * 32 * 32, 则H2的输入的size为12 * 32 * 32,
输出还是4 * 32 * 32,H3、H4以此类推,在实验中,用较小的Growth_rate就能实现较好的效果。
Transition Layer
请注意, 在一个DenseBlock里面,feature size并没有发生改变,因为需要对不同层的feature map进行concatenate操作,这需要保持相同的feature size。
因此在相邻的DenseBlock中间使用Down Sampling来增大感受野(卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小),即使用Transition Layer来实现,一般的Transition Layer包含BN、Conv和Avg_pool,
同时减少维度,压缩率(compress rate)通常为0.5, 即减少一半的维度。

例如,假设block1的输出c * w * h是24 * 32 * 32,那么经过transition之后,block2的输入就是12 * 16 * 16。
Bottleneck
为了减少参数和计算量,DenseNet的非线性变换H采用了Bottleneck结构BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),1×1的卷积用于降低维度,将channels数降
低至4 * Growth_rate。
Bottleneck是这样一种网络,其输入输出channel差距较大,就像一个瓶颈一样,上窄下宽亦或上宽下窄,特征图的大小会因为最后一步的cat从N×in_planes×H×W变成N×(in_planes+growth_rate)×H×W。而transition则用来把N×in_planes×H×W变成N×growth_rate×0.5H×0.5W
定义网络
C=torch.cat((A,B),1)就表示按维数1(两位情况是列,四维是channel)拼接A和B,也就是横着拼接,A左B右。此时需要注意:行数必须一致,即维数0数值要相同,方能行对齐。拼接后的C的第1维是两个维数1数值和。
kernelsize为1,padding为0和kernelsize为3,padding为1都会让卷积后的特征图的大小与原来的图片一致:一个是(N-1)/1+1,一个是(N+2*1-3)/1+1,由此我们可以得出结论,在stride为1时,只要kernelsize=2*padding+1,就不会改变特征图的大小。
注意:stride会默认为核的大小,因此在下面的实验里,stride的值为4。一般情况下,池化层的输出大小为(N-kernelsize)/stride+1,当stride等于kernelsize的时候,也就是不填stride时,输出的大小为N/kernel。
# Load necessary modules here
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
import os
from tensorboardX import SummaryWriter
writer = SummaryWriter()
class Bottleneck(nn.Module):
''' the above mentioned bottleneck, including two conv layer, one's kernel size is 1×1, another's is 3×3 in_planes可以理解成channel after non-linear operation, concatenate the input to the output '''
def __init__(self, in_planes, growth_rate):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv1 = nn.Conv2d(in_planes, 4*growth_rate, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(4*growth_rate)
self.conv2 = nn.Conv2d(4*growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
# input and output are concatenated here
out = torch.cat([out,x], 1)
return out
class Transition(nn.Module):
''' transition layer is used for down sampling the feature when compress rate is 0.5, out_planes is a half of in_planes '''
def __init__(self, in_planes, out_planes):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(in_planes)
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False)
def forward(self, x):
out = self.conv(F.relu(self.bn(x)))
# use average pooling change the size of feature map here
out = F.avg_pool2d(out, 2)
return out
class DenseNet(nn.Module):
def __init__(self, block, nblocks, growth_rate=12, reduction=0.5, num_classes=10):
super(DenseNet, self).__init__()
''' Args: block: bottleneck nblock: a list, the elements is number of bottleneck in each denseblock growth_rate: channel size of bottleneck's output reduction: '''
self.growth_rate = growth_rate
num_planes = 2*growth_rate
self.conv1 = nn.Conv2d(3, num_planes, kernel_size=3, padding=1, bias=False)
# a DenseBlock and a transition layer
self.dense1 = self._make_dense_layers(block, num_planes, nblocks[0])
num_planes += nblocks[0]*growth_rate
# the channel size is superposed, mutiply by reduction to cut it down here, the reduction is also known as compress rate
out_planes = int(math.floor(num_planes*reduction))
self.trans1 = Transition(num_planes, out_planes)
num_planes = out_planes
# a DenseBlock and a transition layer
self.dense2 = self._make_dense_layers(block, num_planes, nblocks[1])
num_planes += nblocks[1]*growth_rate
# the channel size is superposed, mutiply by reduction to cut it down here, the reduction is also known as compress rate
out_planes = int(math.floor(num_planes*reduction))
self.trans2 = Transition(num_planes, out_planes)
num_planes = out_planes
# a DenseBlock and a transition layer
self.dense3 = self._make_dense_layers(block, num_planes, nblocks[2])
num_planes += nblocks[2]*growth_rate
# the channel size is superposed, mutiply by reduction to cut it down here, the reduction is also known as compress rate
out_planes = int(math.floor(num_planes*reduction))
self.trans3 = Transition(num_planes, out_planes)
num_planes = out_planes
# only one DenseBlock
self.dense4 = self._make_dense_layers(block, num_planes, nblocks[3])
num_planes += nblocks[3]*growth_rate
# the last part is a linear layer as a classifier
self.bn = nn.BatchNorm2d(num_planes)
self.linear = nn.Linear(num_planes, num_classes)
def _make_dense_layers(self, block, in_planes, nblock):
layers = []
# number of non-linear transformations in one DenseBlock depends on the parameter you set
for i in range(nblock):
layers.append(block(in_planes, self.growth_rate))
in_planes += self.growth_rate
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.trans1(self.dense1(out))
out = self.trans2(self.dense2(out))
out = self.trans3(self.dense3(out))
out = self.dense4(out)
out = F.avg_pool2d(F.relu(self.bn(out)), 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def densenet():
return DenseNet(Bottleneck, [2, 5, 4, 6])
print(densenet())
DenseNet(
(conv1): Conv2d(3, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(dense1): Sequential(
(0): Bottleneck(
(bn1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(24, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Bottleneck(
(bn1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(36, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(trans1): Transition(
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv): Conv2d(48, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(dense2): Sequential(
(0): Bottleneck(
(bn1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(24, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Bottleneck(
(bn1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(36, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Bottleneck(
(bn1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(48, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): Bottleneck(
(bn1): BatchNorm2d(60, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(60, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(4): Bottleneck(
(bn1): BatchNorm2d(72, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(72, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(trans2): Transition(
(bn): BatchNorm2d(84, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv): Conv2d(84, 42, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(dense3): Sequential(
(0): Bottleneck(
(bn1): BatchNorm2d(42, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(42, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Bottleneck(
(bn1): BatchNorm2d(54, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(54, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Bottleneck(
(bn1): BatchNorm2d(66, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(66, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): Bottleneck(
(bn1): BatchNorm2d(78, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(78, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(trans3): Transition(
(bn): BatchNorm2d(90, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv): Conv2d(90, 45, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(dense4): Sequential(
(0): Bottleneck(
(bn1): BatchNorm2d(45, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(45, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Bottleneck(
(bn1): BatchNorm2d(57, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(57, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Bottleneck(
(bn1): BatchNorm2d(69, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(69, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): Bottleneck(
(bn1): BatchNorm2d(81, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(81, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(4): Bottleneck(
(bn1): BatchNorm2d(93, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(93, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(5): Bottleneck(
(bn1): BatchNorm2d(105, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(105, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(48, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(bn): BatchNorm2d(117, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(linear): Linear(in_features=117, out_features=10, bias=True)
)
小测试
x = torch.randn((3,3,4,8))
y = F.max_pool2d(x, 4)
print(x.shape)
print(y.shape)
b = Bottleneck(3, 5)
print(b(x).shape)
t = Transition(3, 5)
print(t(x).shape)
torch.Size([3, 3, 4, 8])
torch.Size([3, 3, 1, 2])
torch.Size([3, 8, 4, 8])
torch.Size([3, 5, 2, 4])
问题1
上面的定义的DenseNet为多少层DenseNet(只计算卷积层与全连接层)?请定义一个卷积层总数为52层的DenseNet。
答:每个Bottleneck包含了两个卷积层,每个Transition包含一个卷积层,总共有2+5+4+6=17个Bottleneck和3个transition,也就是37个卷积层,再加上最前面的卷积层和最后的全连接层,最后总共有39层。
def densenet52():
return DenseNet(Bottleneck, [6, 4, 8, 6])
训练与测试
import torchvision
import torchvision.transforms as transforms
from torch.autograd import Variable
def train(epoch, model, lossFunction, optimizer, device, trainloader):
"""train model using loss_fn and optimizer. When this function is called, model trains for one epoch. Args: train_loader: train data model: prediction model loss_fn: loss function to judge the distance between target and outputs optimizer: optimize the loss function get_grad: True, False output: total_loss: loss average_grad2: average grad for hidden 2 in this epoch average_grad3: average grad for hidden 3 in this epoch """
print('\nEpoch: %d' % epoch)
model.train() # enter train mode
train_loss = 0 # accumulate every batch loss in a epoch
correct = 0 # count when model' prediction is correct i train set
total = 0 # total number of prediction in train set
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device) # load data to gpu device
inputs, targets = Variable(inputs), Variable(targets)
optimizer.zero_grad() # clear gradients of all optimized torch.Tensors'
outputs = model(inputs) # forward propagation return the value of softmax function
loss = lossFunction(outputs, targets) #compute loss
loss.backward() # compute gradient of loss over parameters
optimizer.step() # update parameters with gradient descent
train_loss += loss.item() # accumulate every batch loss in a epoch
_, predicted = outputs.max(1) # make prediction according to the outputs
total += targets.size(0)
correct += predicted.eq(targets).sum().item() # count how many predictions is correct
if (batch_idx+1) % 100 == 0:
# print loss and acc
print( 'Train loss: %.3f | Train Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
print( 'Train loss: %.3f | Train Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
def test(model, lossFunction, optimizer, device, testloader):
""" test model's prediction performance on loader. When thid function is called, model is evaluated. Args: loader: data for evaluation model: prediction model loss_fn: loss function to judge the distance between target and outputs output: total_loss accuracy """
global best_acc
model.eval() #enter test mode
test_loss = 0 # accumulate every batch loss in a epoch
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = lossFunction(outputs, targets) #compute loss
test_loss += loss.item() # accumulate every batch loss in a epoch
_, predicted = outputs.max(1) # make prediction according to the outputs
total += targets.size(0)
correct += predicted.eq(targets).sum().item() # count how many predictions is correct
# print loss and acc
print('Test Loss: %.3f | Test Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*correct/total, correct, total))
def data_loader():
# define method of preprocessing data for evaluating
transform_train = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# Normalize a tensor image with mean and standard variance
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
# Normalize a tensor image with mean and standard variance
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# prepare dataset by ImageFolder, data should be classified by directory
trainset = torchvision.datasets.ImageFolder(root='./mnist/train', transform=transform_train)
testset = torchvision.datasets.ImageFolder(root='./mnist/test', transform=transform_test)
# Data loader.
# Combines a dataset and a sampler,
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
return trainloader, testloader
def run(model, num_epochs):
# load model into GPU device
# device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
device = 'cpu'
model.to(device)
# if device == 'cuda:0':
# model = torch.nn.DataParallel(model)
# cudnn.benchmark = True
# define the loss function and optimizer
lossFunction = nn.CrossEntropyLoss()
lr = 0.01
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
trainloader, testloader = data_loader()
for epoch in range(num_epochs):
train(epoch, model, lossFunction, optimizer, device, trainloader)
test(model, lossFunction, optimizer, device, testloader)
if (epoch + 1) % 50 == 0 :
lr = lr / 10
for param_group in optimizer.param_groups:
param_group['lr'] = lr
用你自己定义的DenseNet进行测试
# start training and testing
model = densenet52()
# num_epochs is adjustable
run(model, num_epochs=20)
Epoch: 0
Train loss: 2.247 | Train Acc: 19.900% (398/2000)
Test Loss: 2.314 | Test Acc: 10.000% (100/1000)
Epoch: 1
Train loss: 1.916 | Train Acc: 38.700% (774/2000)
Test Loss: 2.055 | Test Acc: 25.300% (253/1000)
Epoch: 2
Train loss: 1.398 | Train Acc: 56.450% (1129/2000)
Test Loss: 1.486 | Test Acc: 39.300% (393/1000)
Epoch: 3
Train loss: 0.988 | Train Acc: 72.300% (1446/2000)
Test Loss: 1.224 | Test Acc: 56.600% (566/1000)
Epoch: 4
Train loss: 0.716 | Train Acc: 78.250% (1565/2000)
Test Loss: 0.755 | Test Acc: 75.400% (754/1000)
Epoch: 5
Train loss: 0.561 | Train Acc: 81.000% (1620/2000)
Test Loss: 0.795 | Test Acc: 70.300% (703/1000)
Epoch: 6
Train loss: 0.487 | Train Acc: 82.150% (1643/2000)
Test Loss: 0.634 | Test Acc: 75.500% (755/1000)
Epoch: 7
Train loss: 0.475 | Train Acc: 82.300% (1646/2000)
Test Loss: 0.644 | Test Acc: 77.800% (778/1000)
Epoch: 8
Train loss: 0.458 | Train Acc: 83.550% (1671/2000)
Test Loss: 0.395 | Test Acc: 84.300% (843/1000)
Epoch: 9
Train loss: 0.403 | Train Acc: 86.000% (1720/2000)
Test Loss: 0.551 | Test Acc: 82.500% (825/1000)
Epoch: 10
Train loss: 0.351 | Train Acc: 87.050% (1741/2000)
Test Loss: 0.674 | Test Acc: 77.100% (771/1000)
Epoch: 11
Train loss: 0.321 | Train Acc: 89.100% (1782/2000)
Test Loss: 0.338 | Test Acc: 88.900% (889/1000)
Epoch: 12
Train loss: 0.256 | Train Acc: 92.400% (1848/2000)
Test Loss: 0.394 | Test Acc: 87.800% (878/1000)
Epoch: 13
Train loss: 0.251 | Train Acc: 92.550% (1851/2000)
Test Loss: 0.448 | Test Acc: 84.300% (843/1000)
Epoch: 14
Train loss: 0.259 | Train Acc: 92.150% (1843/2000)
Test Loss: 0.414 | Test Acc: 86.000% (860/1000)
Epoch: 15
Train loss: 0.229 | Train Acc: 93.850% (1877/2000)
Test Loss: 0.321 | Test Acc: 88.300% (883/1000)
Epoch: 16
Train loss: 0.196 | Train Acc: 94.400% (1888/2000)
Test Loss: 0.393 | Test Acc: 87.100% (871/1000)
Epoch: 17
Train loss: 0.178 | Train Acc: 95.350% (1907/2000)
Test Loss: 0.295 | Test Acc: 90.600% (906/1000)
Epoch: 18
Train loss: 0.184 | Train Acc: 94.650% (1893/2000)
Test Loss: 0.351 | Test Acc: 87.700% (877/1000)
Epoch: 19
Train loss: 0.168 | Train Acc: 95.200% (1904/2000)
Test Loss: 0.164 | Test Acc: 95.500% (955/1000)
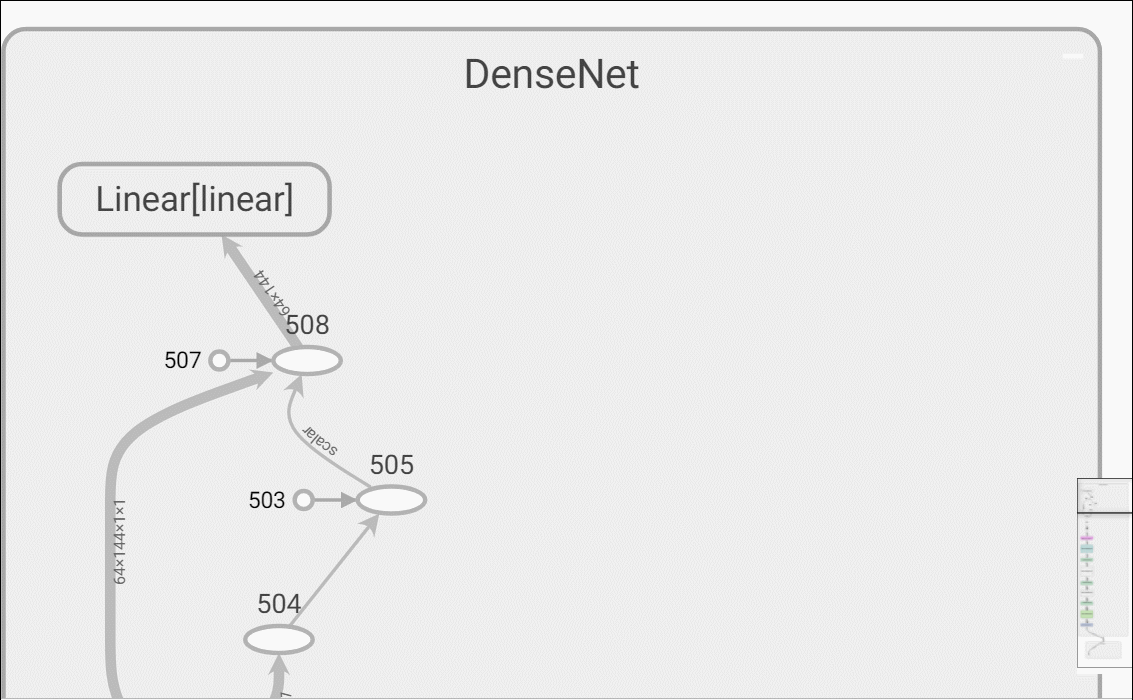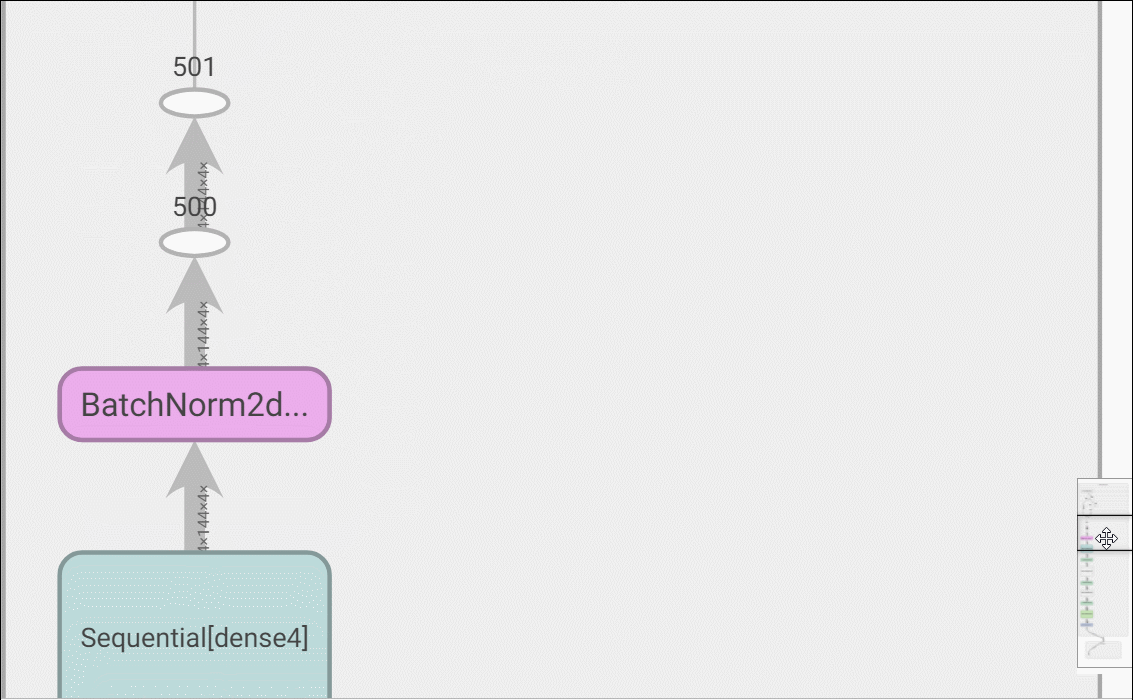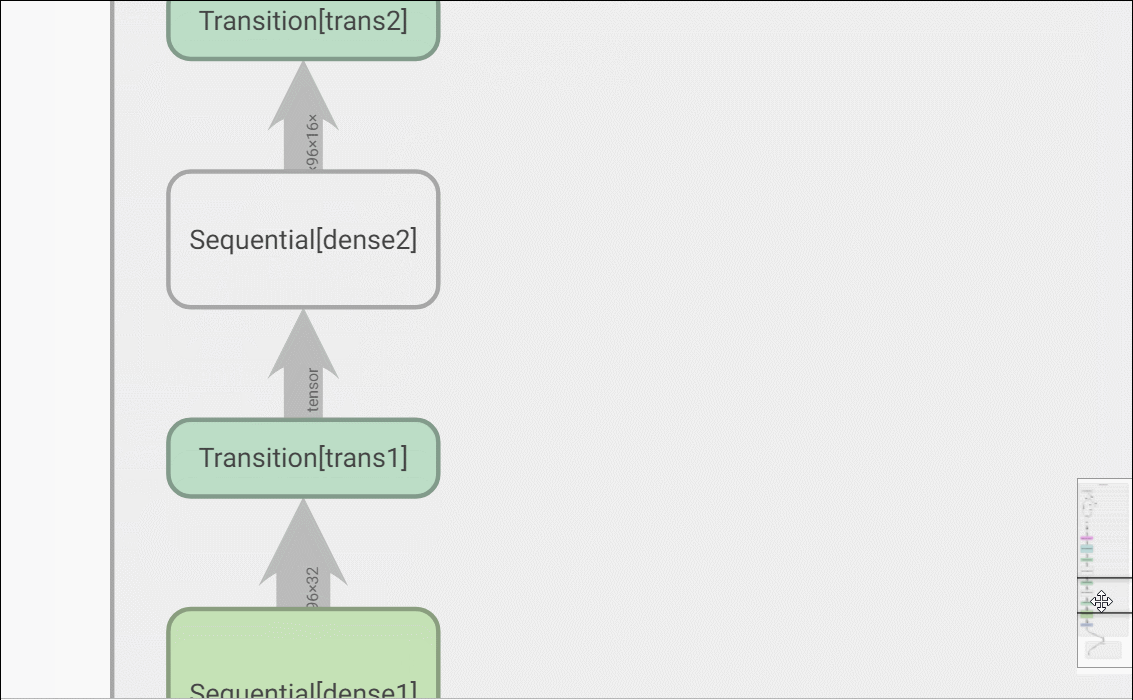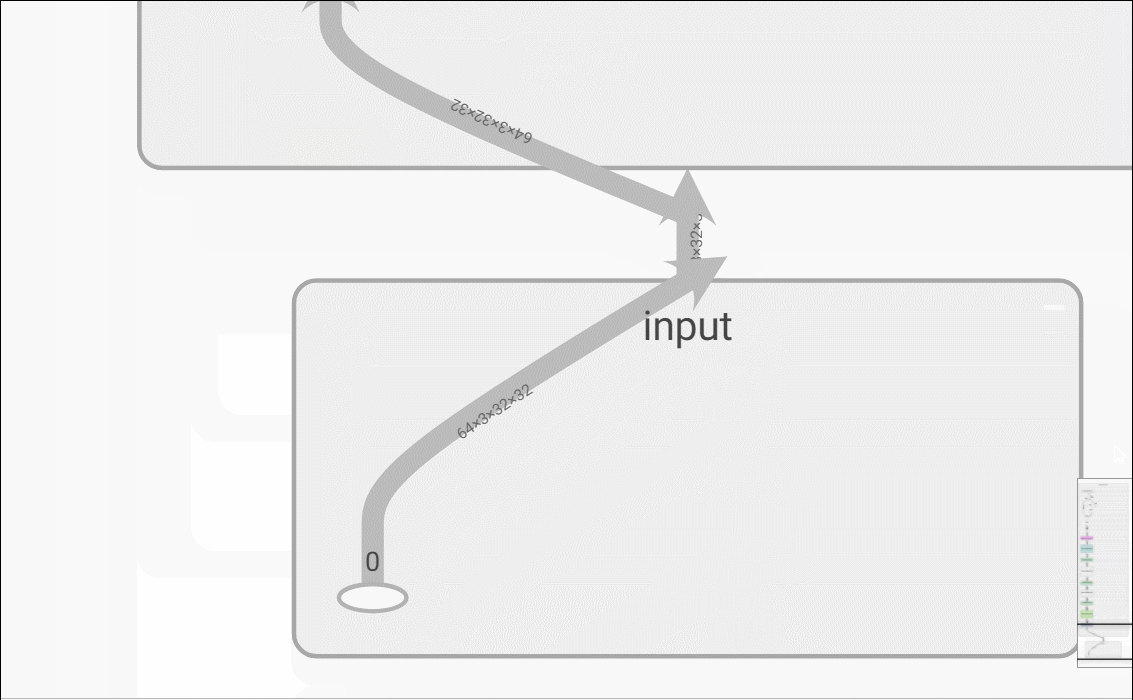
可视化网络结构
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
model.to(device)
train_loader, _ = data_loader()
dataiter = iter(train_loader)
images, _ = dataiter.next() # get a batch of images
images = images.to(device)
with SummaryWriter(comment="densenet52") as s:
s.add_graph(model, (Variable(images),))
s.close()
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/187961.html原文链接:https://javaforall.net


