
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
半监督学习之MixMatch
MixMatch
Unsupervised Data Augmentation for Consistency Training
MixMatch: A Holistic Approach to Semi-Supervised Learning
1.解读
此方法仅用少量的标记数据,就使半监督学习的预测精度逼近监督学习。
- 自洽正则化(Consistency Regularization)。自洽正则化的思路是,对未标记数据进行数据增广,产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增广产生的样本,模型预测结果应保持一致。


x 是未标记数据,Augment(x) 表示对x做随机增广产生的新数据, [公式] 是模型参数,y 是模型预测结果。注意数据增广是随机操作,两个 Augment(x) 的输出不同。这个 L2 损失项,约束机器学习模型,对同一个图像做增广得到的所有新图像,作出自洽的预测。
MixMatch 集成了自洽正则化。数据增广使用了对图像的随机左右翻转和剪切(Crop)。
- 最小化熵(Entropy Minimization)。许多半监督学习方法都基于一个共识,即分类器的分类边界不应该穿过边际分布的高密度区域。具体做法就是强迫分类器对未标记数据作出低熵预测。
MixMatch 使用 “sharpening” 函数,最小化未标记数据的熵。
- **传统正则化(Traditional Regularzation)。**为了让模型泛化能力更好,一般的做法对模型参数做 L2 正则化,SGD下L2正则化等价于Weight Decay。MixMaxtch 使用了 Adam 优化器,而之前有篇文章发现 Adam 和 L2 正则化同时使用会有问题,因此 MixMatch 从谏如流使用了单独的Weight decay。
Mixup数据增强方法。从训练数据中任意抽样两个样本,构造混合样本和混合标签,作为新的增广数据,
这种 MixMatch 方法在小数据上做半监督学习的精度,远超其他同类模型。比如,在 CIFAR-10 数据集上,只用250个标签,他们就将误差减小了4倍(从38%降到11%)。在STL-10数据集上,将误差降低了两倍。
对比 MixMatch 使用 250 张标记图片,就可以将测试误差降低到 11.08,使用4000张标记图片,可以将测试误差降低到 6.24,应该算是大幅度超越使用GAN做半监督学习的效果。
具体实现
1.使用MixMatch算法,对一个Batch的标记数据X和一个Batch的未标记数据U做数据数据增强,分别得到一个Batch的增强数据X’和K个Batch的U’
X ′ , U ′ = M i x M a t c h { X , U , T , K , α } \mathcal {X’,U’=MixMatch\{X,U,T,K,\alpha\}} X′,U′=MixMatch{
X,U,T,K,α}
T,温度参数(sharpen的超参数);K,对未标记的数据做K次随机增强,α是Mixup的超参数
2.对X’和U’分别计算损失

|X|等于batch size,|U|等于K倍的batch size,L是分类类别数,H是CE
对于未标注的数据使用L2范数做损失因为L2比CE约束更加严格
3.最终的损失是两者的加权

另一一篇博客
The Quiet Semi-Supervised Revolution
性能和标注数据量的关系
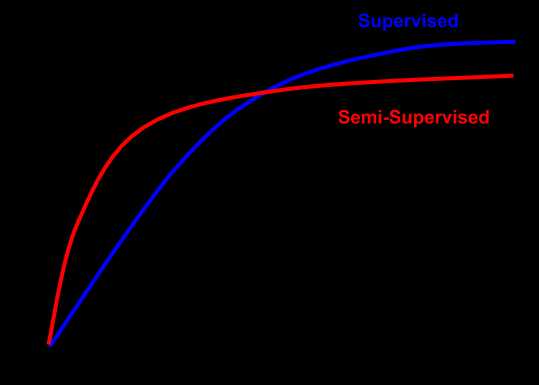
现在的趋势是

2.论文阅读
题目:MixMatch:一个半监督学习的整体(Holistic)方法
代码
- 1.tensorflow
- 2.pytorch
2.1摘要
半监督学习已被证明是一个强大的利用未标签数据来减轻依赖于大型标签数据集的范式(paradigm)。
MixMatch估计(guess)低熵的数据增强后的未标注样本,然后使用Mixup将标注的数据和未标注的数据混合起来。
2.2介绍
SSL,Semi-supervised Learning
许多半监督的学习方法通过增加在未标注的数据上计算的损失项(loss term)来估计模型在没见过的数据上泛化。
损失项分为3类(falls into one of three classes)
- Entropy Minimization,鼓励模型在未标注的数据上输出高置信度(confident predictions)的预测
- Consistency Regularization,鼓励模型在其输入受到干扰时产生相同的输出分布
- Generic Regularization,减少模型过拟合
MixMatch优雅地统一了这些主流的方法(gracefully unifies these dominant approaches)
2.3相关工作
最近的一些SOTA的方法
-
Consistency Regularization
一致性/自洽正则化
数据增强将输入进行转换并且认为类别语义不受影响。
粗略地说,数据增强可以通过生成接近无限的新修改数据流来人为地扩展训练集的大小。一致性正则化将数据增强应用于半监督学习,即分类器应该为未标注的例子输出相同的类分布。更正式地说,一致性正则化强制一个未标记的样本x应该和Augment(x)分为一类。
对于一个点x,过去地工作加了一个损失项
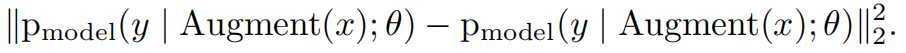
Augment(x)是一个随机地变换,所以2个Augment(*)不等
“Mean Teacher”(2017)将其中一项替换为了模型参数值的滑动平均

MixMatch使用了一种一致性正则化的形式,通过对图像使用标准的数据增强(随机水平翻转和裁切)
-
Entropy Minimization
许多SSL方法的基本假设是分类器的决策边界不应该通过数据分布边际的高密度区域(“非黑即白假设”,想想SVM的决策边界)。一个强制实现的方法是要求分类器对未标记的数据输出低熵的预测。
“Pseudo Label”通过对高置信度的结果变为1-hot标签来隐式地实现低熵
MixMatch通过使用“sharpen”函数来隐式地达到低熵
-
Traditional Regularization
正则化值对模型施以约束来使之更难地记住训练数据以希望对没见过地数据泛化。
使用权重衰减来惩罚模型参数的L2范数,使用MixUp来估计样本之间的凸行为(convex behavior)
2.4 MixMatch
MixMatch是一个”整合“的方法,有上面的主流SSL范式组成。
- 给定batch大小的标注数据和同样大小的标注数据,记为 X , U \mathcal {X,U} X,U
- MixMatch产生一批增强后的数据和增强后的带有“猜测”的标签的增强后的非标注数据,记作 X ′ , U ′ \mathcal {X’,U’} X′,U′

- 使用 X ′ , U ′ \mathcal {X’,U’} X′,U′分别计算标注和未标注损失项
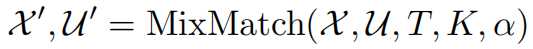
H ( p , q ) H(p,q) H(p,q)是分布p和q的交叉熵, T , K , α , λ U T,K,\alpha,\mathcal{\lambda_U} T,K,α,λU是超参数,L是类别(X of labeled examples with one-hot targets (representingone of L possible labels)
算法:

算法的伪代码
标签“猜测”过程
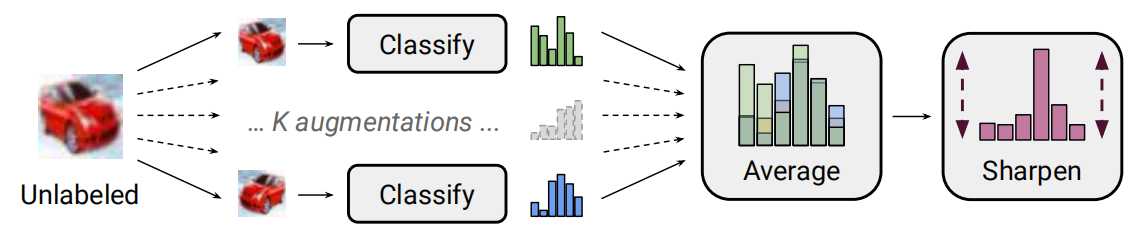
随机数据增强对未标注的数据使用K次,每次的增强后的图片都被输入分类器。然后,这些K个预测被”锐化“(“sharpened”)通过调整分布的温度超参。
- 数据增强
对于标注数据生成一个batch size的增强结果,对于非标注数据,我们生成K*batch size的增强结果。对于非标注的数据,生成K个增强结果。使用这些独立的增强结果来生成”猜测标签”
- 标签猜测
对于每个未标注的样本,MixMatch使用模型的预测产生一个“猜测”的样本标签,这个猜测随后会被用于非监督损失项。
计算K个增强的结果计算平均值:
q ˉ b = 1 K ∑ k = 1 K p m o d e l ( y ∣ u ^ b , k ; θ ) \bar q_b=\frac{1}{K}\sum^K_{k=1}p_{model}(y|\hat u_{b,k};\theta) qˉb=K1∑k=1Kpmodel(y∣u^b,k;θ)
通过对未标记的样本进行增强获得的人工结果来实现一致性正则化
使用一致性正则化会带来域适应(cycleGAN)
- 锐化
通过锐化来减少标签分布的熵。使用常用的方法来调整类分布的**”温度“**
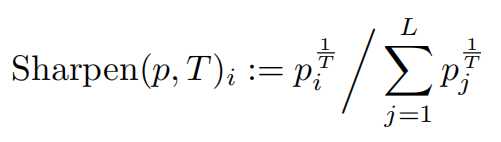
当T→0,输出的结果趋于Dirac分布(one-hot)
- MixUp
将标注的样本的标签和非标注样本的“猜测标签”混合。
具体做法:
从beta分布中采样得到权重λ

对于两对数据标签对 ( x 1 , p 1 ) , ( x 2 , p 2 ) (x_1,p_1),(x_2,p_2) (x1,p1),(x2,p2),mix后的结果为 ( x ′ , y ′ ) (x’,y’) (x′,y′)。 λ ′ \lambda’ λ′的作用是使得x’比x2更加靠近x1(使得标注得标签占比更大)x
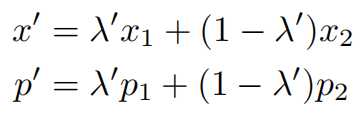
α是调整beta分布的超参数。
为了实现Mixup,首先收集所有得增强后的标注样本标签和增强后的未标注样本的“猜测标签”,然后将结果混洗后作为Mixup的数据源 W \mathcal W W,然后将标注的数据和等量的 W \mathcal W W作为Mixup的输入得到结果 X ^ \mathcal {\hat X} X^,然后将剩余的 W \mathcal W W中的数据和未标记的带“猜测标签”的数据作为Mixup的输入。
SSL对未标注数据使用L2损失的原因是对不正确的预测不敏感。
消融实验的结果:

参数EMA似乎是负面的影响
2.5实践细节
-
超参数的设置
- T=0.5
- K=2
- α=0.75
- λ U \mathcal {\lambda_U} λU=100
训练前的16,000中,线性地将 λ U \mathcal{\lambda_U} λU提高到最大值。
-
模型
- Wide ResNet-28
-
学习率地设置
- 不使用学习率衰减而是使用模型参数值的滑动平均,衰减率为0.999
发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/215899.html原文链接:https://javaforall.net

![霍尼韦尔与浙江石化扩大合作,助力中国最大石化项目进一步建设[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
