
大家好,又见面了,我是你们的朋友全栈君。
上一篇文章我们简单阐述了,大多数研究者在进行大数据分析时,所存在的逻辑问题,并简明扼要的对大数据建模流程进行了说明,那么为了使大家更加清晰每一个步骤的具体内容,我们将每一个模块展开分析。详细阐述流程中具体要做的工作内容?
一.宏观角度
无论是大数据还是人工智能技术,其实都是需求或者项目主题的实现手段,商业上希望技术能够将产品向商品转化,或者对市场进行科学的分析,从而引导公司决策更符合市场需求;科研上希望技术能够进行多学课融合,使得科研结果更具有说服力,亦或者是技术本身的创新与变革,使得科技文明不断发展。由此看来,无论是商业界还是科研界,技术的核心作用是更为科学合理的解决实际问题。所以科研主题和业务需求是决定宏观方向和最终结果的地基。所以,需求的重要性决定了产品的价值。
下图清晰的阐述了目前流行的相关数据职业与需求的关系。
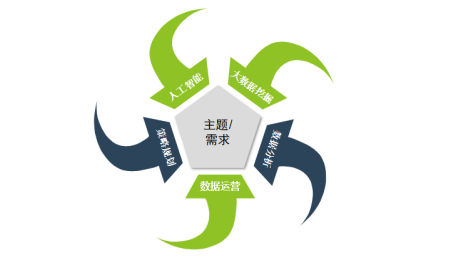

二.微观角度
当一个主题或者业务需求确定之后,我们需要做的第一个工作是尽可能的全面的去解析业务需求(主题),也就是大数据建模的第一步任务分析。Madge老师将从以下几个方面为大家一一说明:
1.准备工作
对于不同的主题或者业务需求所属的行业环境是不一样的,很多数据研究者是需要对业务所需要的环境有所了解的。但是,要是为了一次业务去学习一个行业这是不现实的,所以从以往文献中快速提取可用信息便是数据建模师必备的能力。除此之外,一个资深的数据建模师,有非常强的数据敏感度,当大量的数据出现在面前时候,凭借这种超强的数据敏感度和知识提取能力,是完全可以看出数据所呈现的就基本特征和可能的潜在关系。所以,资深的大数据建模师或者AI能够涉猎的领域非常广泛。
所以,当拿一个主题,首要的第一个任务就是通过各种方式了解行业背景,以及业务常识,方法有很多,如果具备我上述的能力的话,直接通过文献提取重要信息结合市场需求扩展即可。
2.任务分析
当行业背景或者主题的环境了解全面之后,就进入了最为重要的一步,就是任务分析,小编之前说过,任务分析越全面整体脉络也就越清晰,从而架构越完整,模型更容易搭建。那么任务分析对的内容是什么呢?我们用一张图说明。

根据上图我们能够观察到,任务分析大致分为了五个部分,至于第一部分任务描述,小编这里就不详细描述了。我们详细阐述一下:任务拆分,任务定类,确定任务环境。
为了能够更直观的反应各个步骤我们设立这样一个简单的项目场景,
例:已知过去20年某一个GDP,我们来预测未来五年该城市GDP的走向。
(当然,这里我们只是用这个例子做一步骤引导。切不可当成一个完整的项目去看。)
首先,我们知道这是一个研究一个城市经济发展状况的案例,所以要进行经济环境的基本描述,另外补充国民经济的相关常识,这些我们就不在赘述。
2.1任务拆分
当一个任务被指定或者一个主题被提出,我们不难发现他们所需要处理的问题并不只是一个。我们需要考虑该任务所包含的子问题的需要解决。当然,这就去取决于建模师对问题的认知和业务常识了,所以这一步份往往需要参考文献,或者同专业领域的专家进行合作。
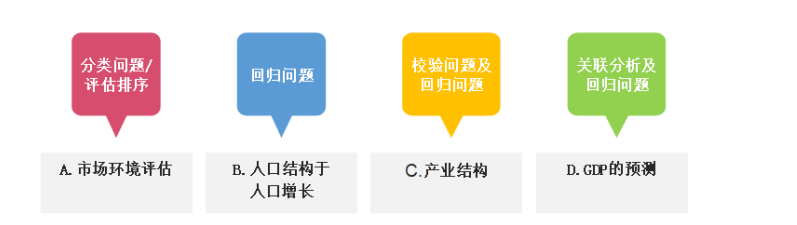
例如:就研究GDP而言,就有可能存在以下子问题。
A.整体市场大环境的评估,属于稳定期,飞速发展时期,还是动荡时期等。
B.该城市的人口结构以及人口增长进行预测分析。
C.该城市的产业结构变动
D.该城市的GDP的变化
以上我们只是简单的罗列出几条,当然任务拆分由于角度不同会长产生很多子问题,有很多时候我们只选择我们需求的角度详细分析即可。但是,一定要能够说明单个子问题产生的原因。
例如,一个城市的GDP一定是受市场经济状况,社会是否稳定,或者是否出现不可抗因素等影响的。因此,对大环境的评估将是一个很重要的问题。当然有些时候我们也可以假定是稳定期,这取决于你自己的需求和所处的环境。
2.2任务定类
当子问题确定之后,对问题进行定类是十分重要的。定类主要考虑的是子问题的类别,是分类,回归,关联关系等?当然还要分析是有监督还是无监督?至于问题的类别,有时间我们会详细阐述。
例如:在上述例子中,我们的子问题对应的类别可以这样评定。
2.3 确定任务环境
确定任务环境主要是指数据环境。
第一:要先确定你所选择的子任务是作为假设还是具体的分析对象;
第二:确定你的数据集是文本,语音,图像还是数值;
第三:对单个子问题进行背景描述。
2.4 梳理逻辑
将以上任务分析总结一个逻辑框架,进行整理。
推荐大家关注公众号,有很多有意思的的知识,可免费领取学习资料哦

发布者:全栈程序员-站长,转载请注明出处:https://javaforall.net/135828.html原文链接:https://javaforall.net

![Excel 8000401a 错误 及解决办法[通俗易懂]](https://javaforall.net/wp-content/uploads/2020/11/2020110817443450-480x300.jpg)
